最新
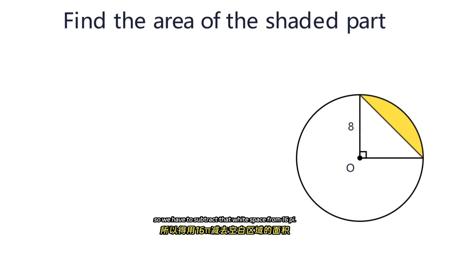
学习
人工智能
K-12
教育助手

















B轮融资6000万美元:这家公司如何用AI赋能基层医疗?
2025年5月,美国数字健康企业 Akido Labs 宣布完成6000万美元B轮融资,由 McKesson Ventures 和 Polaris Partners 联合领投,老股东 Andreessen Horowitz(a16z)与 SVB Capital 跟投。融资所得将主要用于扩大其核心平台 ScopeAI 的部署,尤其是在医疗资源匮乏的社区加速落地。在美国,医生就诊需求每年超过 30

华为版《黑客帝国》首次亮相:训推复杂AI前先“彩排”,小时级预演万卡集群
就在刚刚,华为首次亮相了一套“虚”的技术——数字化风洞,一个在正式训推复杂AI模型之前,可以在电脑中“彩排”的虚拟环境平台。这套有种《黑客帝国》意味般的技术(都是通过虚拟世界预演现实),是由华为马尔科夫建模仿真团队构建,可以小时级预演万卡集群方案。而之所以要在真枪实弹训推复杂AI模型之前来这么一个步骤,是因为华为研究团队发现,超过60%的算力浪费在硬件资源错配与系统耦合上。于是,就像汽车设计师用

1000 亿天价,扎克伯格买下「半个天才」和 Meta AI 的未来
不仅是大模型本身,Meta 也要成为 AI 基建大厂。「21 世纪最贵的是什么?人才!」多年前葛优在《天下无贼》里台词的含金量,还在不断提升。当地时间 6 月 10 日,媒体曝光 Meta 将以 149 亿美元(折合人民币约 1066 亿元)的价格收购 Scale AI 49% 的股权,而后者的联合创始人 Alexandr Wang,将成为 Meta 新成立的「超级智能小组」的掌门。按照股权比推

不是视频模型“学习”慢,而是LLM走捷径|18万引大牛Sergey Levine
为什么语言模型能从预测下一个词中学到很多,而视频模型却从预测下一帧中学到很少?这是UC伯克利大学计算机副教授Sergey Levine最新提出的灵魂一问。他同时是Google Brain的研究员,参与了Google知名机器人大模型PALM-E、RT1和RT2等项目。Sergey Levine在谷歌学术的被引用次数高达18万次。“柏拉图洞穴”是一个很古老的哲学比喻,通常被用来说明人们对世界认知的局
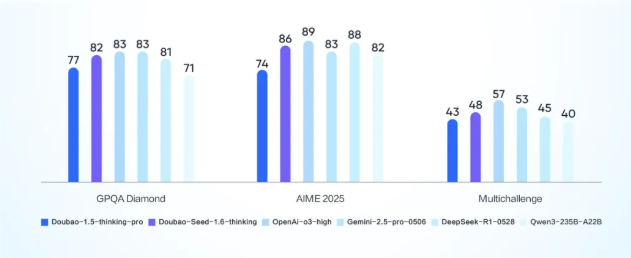
火山引擎正式发布豆包大模型1.6和豆包·视频生成模型 Seedance 1.0 pro
在 FORCE 原动力大会上,火山引擎正式推出了豆包大模型1.6及其全新的视频生成模型 Seedance1.0pro,标志着 AI 云原生全栈服务的全面升级。作为一个多模态、高性价比的领先模型家族,豆包大模型1.6在功能和性能上都进行了显著提升。突破性的价格与性能字节跳动的 CEO 梁汝波在发布会上表示,豆包大模型1.6采用统一定价模式,开创了按 “输入长度” 区间定价的先河。在企业常用的0-32

AI 应用助力低技能出租车司机提升工作效率
近日,日本东京大学的研究者们发现,人工智能(AI)工具在出租车司机中的应用,特别是对技能较低的司机,有助于提高他们的工作效率。该研究揭示了一个令人惊讶的趋势:AI 不仅可以帮助高技能的工人,反而在一些情况下能够更显著地提升低技能工人的表现,缩小技能差距。图源备注:图片由AI生成,图片授权服务商Midjourney研究团队专注于日本横滨市的出租车司机,分析了一款名为 AI Navi 的应用程序。这个
苹果AI模型更新:设备端实力逐渐接近竞争对手,但服务器端表现欠佳
苹果公司发布了最新的人工智能模型更新,这一更新主要为其 Apple Intelligence 功能提供支持,适用于 iOS 和 macOS 等系统。根据苹果官方的数据,新推出的模型在性能上与谷歌和阿里巴巴的同类产品相当,但与 OpenAI 一年前发布的 GPT-4o 相比,苹果的服务器端模型表现则显得逊色不少。在更新中,苹果强调了其 “苹果设备端模型” 的能力。这个模型能够在 iPhone 等设备
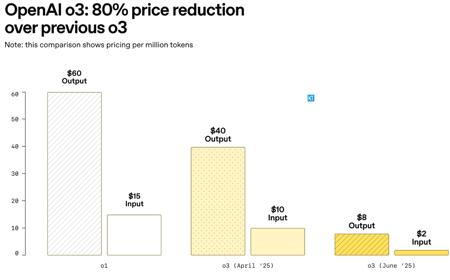
OpenAI放大招 !o3价格暴降80% ,o3-pro强势上线
OpenAI宣布对其旗舰推理模型o3的价格下调80%,同时推出高性能的o3-pro模型。此举大幅降低了开发者成本,引发AI市场新一轮竞争。o3价格大幅下调OpenAI对o3模型的定价进行了重大调整,具体如下:输入令牌:原价每百万令牌10美元,现降至每百万令牌2美元。输出令牌:原价每百万令牌40美元,现降至每百万令牌8美元。缓存输入令牌:提供额外75%折扣,定价为每百万令牌0.5美元。新定价使o3的

Meta 推 LlamaRL 强化学习框架:全异步分布设计,训练 AI 模型提速 10.7 倍
IT之家 6 月 11 日消息,科技媒体 marktechpost 昨日(6 月 10 日)发布博文,报道称 Meta 公司推出 LlamaRL 框架,采用全异步分布式设计,在 405B 参数模型上,LlamaRL 将强化学习步骤时间从 635.8 秒缩短至 59.5 秒,速度提升 10.7 倍。IT之家注:强化学习(Reinforcement Learning,RL)通过基于反馈调整输出,让模
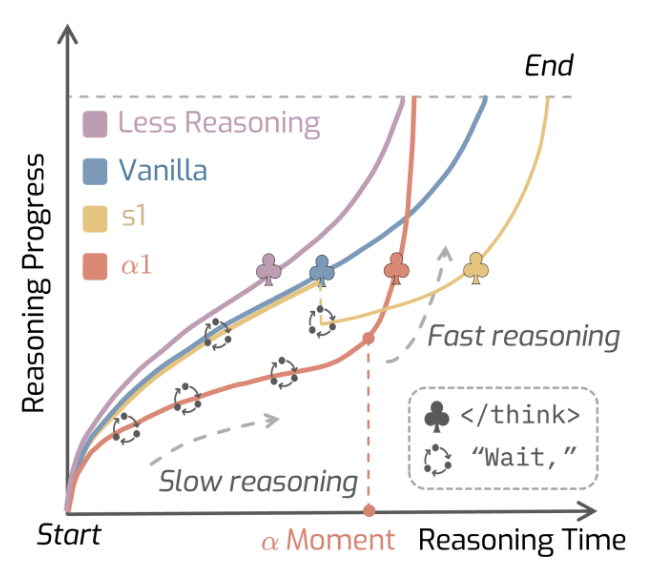
突破性AI框架AlphaOne:让大模型"先慢思考后快思考",效率提升21%
伊利诺伊大学香槟分校和加州大学伯克利分校研究人员联合开发的AlphaOne(α1)框架,为大型语言模型推理控制带来重大突破。该框架能让开发者精确调节模型"思考"方式,在提升推理能力的同时显著优化计算资源使用。解决AI推理痛点当前大型推理模型如OpenAI o3和DeepSeek-R1虽然融入了"系统2"慢思考机制,但存在明显缺陷:对简单问题"过度思考"浪费计算资源,对复杂问题"思考不足"导致错误答
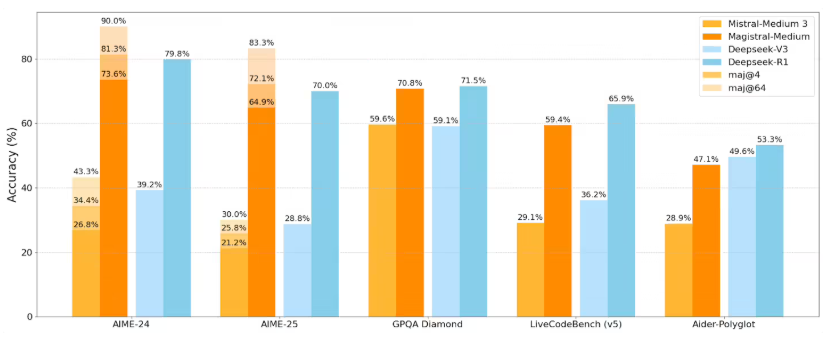
法国 AI 实验室 Mistral 发布全新推理模型 Magistral,Small 版已开放下载
法国人工智能实验室 Mistral 近日宣布正式推出其首个推理模型系列 ——Magistral。该系列包括 Magistral Small 和 Magistral Medium 两个版本,旨在提升在数学、物理等学科领域的逻辑推理能力。Mistral 表示,Magistral 系列模型通过分步骤解决问题,以期提高结果的一致性和可靠性。Magistral Small 版拥有240亿个参数,并已在人工智
英伟达黄仁勋盛赞 AI 行业变革速度惊人:过去 10 年进步了 100 万倍
IT之家 6 月 11 日消息,英伟达首席执行官黄仁勋本周与英国首相基尔・斯塔默会面,在“伦敦科技周”开幕式上探讨 AI 的未来。据外媒 Tom"s Hardware 报道,双方共同宣布一系列举措,将 AI 纳入国家经济规划,配套大规模基础设施建设、人才培养,以及政府与产业的深度合作。黄仁勋还强调,过去十年间 AI 硬件性能提升了 100 万倍 —— 但这背后也有隐忧。黄仁勋说:“过去 10 年

奥尔特曼:平均每次 ChatGPT 查询将消耗“约 1/15 茶匙”的水
IT之家 6 月 11 日消息,OpenAI CEO 奥尔特曼今日在一篇博客文章中表示,一次平均的 ChatGPT 查询大约消耗 0.000085 加仑水,相当于“约 1/15 茶匙”。他在一篇关于 AI 如何改变世界的预测文章《温和的奇点(The Gentle Singularity)》中提出了上述看法。“很多人关心 ChatGPT 的能耗,一次查询大概用掉 0.34 瓦时,大约等于烤箱运行一
AI医疗的黄金赛道,大厂卷疯了
AI看病,真的靠谱吗?AI大模型正在医疗服务行业中扎根。“我们医院在科研平台上已经接入使用了DeepSeek。”北京某三甲医院相关负责人对光锥智能说道,“形式类似于AI助理,能提供科研政策问答、查询、常用文件下载等功能。”这仅仅是当前AI大模型在医疗行业应用的一个缩影。短短4个月时间,DeepSeek已被数百家医院拥抱,覆盖北京、上海、广东、江苏、浙江等20余个省份,其中不乏北京大学第一医院、清

李飞飞自曝详细创业经历:五年前因眼睛受伤,坚定要做世界模型
因为眼睛受伤暂时失去立体视觉,李飞飞更加坚定了做世界模型的决心。在a16z的最新播客节目中,“AI教母”李飞飞讲述了五年前因为一次角膜损伤暂时失去立体视觉的经历:尽管凭借多年经验能想象出三维世界,但一只眼睛看东西时,我开始害怕开车。但作为一名科学家,她也把这次经历当成一次宝贵的“实验”机会。这次生病让她明白了立体视觉对空间交互具有决定性作用,“就像语言模型处理文本时需要理解上下文,物理世界的交互

史上最大AI投资?小扎百亿重金押注Scale AI,华裔最强打工皇帝赢麻了
辍学MIT创业八年,走上人生巅峰刚刚曝出的消息:Meta要向Scale AI再投一笔巨资,可能高达百亿美元!如果数目为真,这将成为有史以来规模最大的一笔私营公司融资。小扎都忍不住上车了,Alexandr Wang的AI数据帝国,还要继续走向巅峰。就在刚刚,Meta被曝出一项改变整个行业布局的战略——豪掷百亿,投资Scale AI!这项手笔,堪称史上最大私营公司AI融资之一。而Scale AI的最