

告别繁琐微调,一句话就能生成LoRA?!
由Transformer作者之一Llion Jones联合创立的明星AI公司SakanaAI,近期推出Text-to-LoRA (T2L),彻底简化了模型适配流程:

现在,微调大模型时动辄数周的数据集准备、反复调整超参数的复杂流程,可以省了。

使用T2L生成的LoRA在参数压缩率上可达80%却仅降1.2%准确率,零样本场景下更以78.3%的平均准确率超越现有SOTA方法。
可以说,“一句话定制模型”的时代正在开启,非技术用户不再需要学习复杂的微调知识,直接用通俗易懂的自然语言就可以完成相应工作。

有网友甚至把它比喻为LLM的一个只有文字描述的私人教练,将会彻底改变游戏规则。

目前该论文已被ICML2025收录。

详细内容如下:
从文本到LoRA
LLM在执行特定任务前,都需要先进行适配的LoRA微调,为每个任务单独训练低秩矩阵,往往耗费大量计算资源和时间。
研究团队从人类视觉系统中汲取灵感,即在有限的感官线索下可以实现环境快速适应,并由此构建了能够动态调制大模型的超网络架构Text-to-LoRA(T2L)。

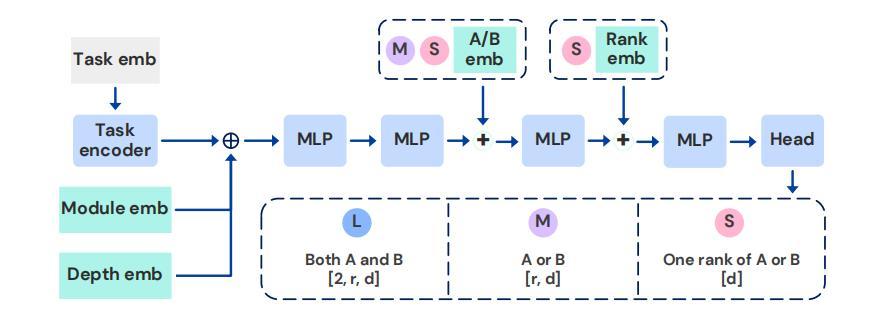
T2L包含3种架构变体,它们在输出空间和参数规模上各有不同,具体为:
- T2L-L:
为每个目标模块(如注意力层、MLP 层)和网络层生成完整的 LoRA 权重矩阵。
该架构的参数规模最大,但能灵活适配不同层的特性,适用于需要精细控制每层适配的场景。
- T2L-M:
按模块类型(而非具体层)共享输出空间。对于同一类型的模块,超网络仅生成一组共享的LoRA矩阵,并应用于该类型下的所有层。
该架构通过参数共享减少了模型规模,同时保留了模块类型级别的适配能力,在参数效率和性能之间取得平衡。
- T2L-S:
为整个模型生成统一的LoRA适配器,不区分模块类型和层索引。
该架构参数规模最小,适用于计算资源有限或任务需求较通用的场景,通过全局适配实现快速部署。
为了训练T2L模型,可以采用两种训练模式,分别是基于LoRA的重建和跨多个任务的监督微调 (SFT)。
LoRA重建的核心思想是让T2L从任务的文本描述中,生成与真实LoRA适配器效果相近的参数,从而最大限度地减少生成适配器和目标适配器之间的重建损失。
这种方法避免了传统方法中对大量任务数据的依赖,转而利用已有的LoRA适配器和文本描述构建监督信号,压缩了现有的LoRAs,但难以进行零镜头泛化。
而监督微调则是使用任务描述,在任务数据集上直接端到端训练T2L。这改进了对未知任务的泛化,并能够根据文本描述生成具有可引导行为的适配器。

针对T2L的适配器压缩性能,团队进行了实验验证。
通过设置9个不同的NLP任务,将一一对应的LoRA适配器参数压缩为文本描述的嵌入向量,并通过3种T2L变体分别重建LoRA参数。
实验发现,重建LoRA与原始LoRA相比,参数规模从15.8M下降为3.2M,压缩率达80%,但在任务的平均准确率上仅下降了1.2%,证明了压缩过程中的知识保留能力。
其中,T2L-L在压缩后性能最接近原始LoRA,而T2L-S压缩率最高。
T2L能够实现高效的参数压缩,可以极大地减少存储需求,帮助LLM在资源受限环境中进行部署。

团队还进一步验证了T2L在零样本场景下生成LoRA适配器的能力。
构建了12个全新的NLP任务并各自提供自然语言描述,使用T2L生成的对应LoRA适配器直接应用于基础模型,测试其在标注数据集上的性能。
结果表明,T2L的平均准确率达到了78.3%,显著高于多任务LoRA的65.1%,和目前最先进的零样本LoRA路由方法Arrow Routing的72.4%。
其中T2L-L因为能够为不同层定制参数,在复杂任务中表现最佳,而T2L-S在简单任务上效率更高,参数规模仅为T2L-L的五分之一,但性能仅下降3.2%。
源于超网络对 “文本语义 - 参数空间” 映射的显式学习,T2L实现了真正的文本驱动,无需任务数据即可通过自然语言描述生成有效LoRA,这为模型快速适应长尾任务提供了可能。
Transformer作者创业公司
背后的公司Sakana AI,由前谷歌研究人员Llion Jones于2023年7月共同创立。
Llion Jones是著名论文《Attention Is All You Need》的8位核心作者之一,论文中首次提出了Transformer架构,为现代LLM架构奠定了基石。

在谷歌工作期间,他还深度参与NLP、模型架构创新等众多核心AI项目,例如Prot Trans、Tensor2Tensor等。
而创办Sakana AI后,他也始终致力于探索超越和补充当前Transformer范式的新路径,例如他们在去年底推出了用于Transformer的新型神经记忆系统NAMM,今年1月提出的Transformer²可以针对各种任务动态调整权重。

目前公司专注利用自然启发的方法(如进化计算和集体智能)来开发基础模型,例如在今年5月他们根据达尔文进化论提出了达尔文哥德尔机 (DGM),可以让AI通过读取和修改自身代码来提升编码性能。

而本篇论文则由Rujikorn Charakorn、Edoardo Cetin、Yujin Tang、Robert T. Lange共同完成。

Rujikorn Charakorn曾在朱拉隆功大学就读,目前在VISTEC研究所攻读博士学位,主要研究方向是深度强化学习、多智能体学习和元学习。
Edoardo Cetin于2023年获得伦敦国王学院的博士学位,目前是Sakana AI的研究科学家,此前还曾在推特的Cortex团队、丰田和高盛实习。
而Yujin Tang则博士毕业于东京大学,曾在谷歌工作长达5年,后来于2024年加入Sakana AI。

Robert T. Lange是Sakana AI的研究科学家和创始成员之一,致力于用基础模型来增强和自动化科学发现过程。
他还主导参与了首个独立生成学术论文的“AI科学家”项目,还曾在社区引起广泛热议。
论文链接:https://arxiv.org/abs/2506.06105代码链接:https://github.com/SakanaAI/Text-to-Lora
参考链接:
[1]https://x.com/RobertTLange/status/1933074366603919638
[2]https://huggingface.co/SakanaAI/text-to-lora/tree/main
[3]https://x.com/tan51616/status/1932987022907670591
[4]https://x.com/SakanaAILabs/status/1932972420522230214
本文来自微信公众号“量子位”,作者:关注前沿科技,36氪经授权发布。
















NeonBloom07
太酷了!一句话搞定LLM微调,效率提升太多了!
NeonBloom07
我支持!这绝对是科技进步的加速器,准备好迎接新世界!
StarryNight_Z
这个想法太疯狂了,但又有点让人觉得,也许这才是未来!
NeonBloom07
这效率提升,说不定就是AI开始统治地球的预兆!
LunarEcho77
感觉人类的创造力在被这玩意儿一点点榨干!
NeonBloom07
这简直是给AI喂了糖,然后它也学会了撒谎!
NeonBloom07
我赌这玩意儿会成为我们生活中最强大的“唠叨者”!
LunarEcho77
效率提升?这跟提升智商有什么区别?有点意思!
LunarEcho77
我感觉未来人类的价值都快被算法取代了,太可怕!
StarryNight_Z
太搞笑了,直接一句话搞定?这简直就是魔术!