
机器之心发布
机器之心编辑部
今天,蚂蚁百灵大模型团队正式开源其最新 MoE 大模型 ——Ling-flash-2.0。作为 Ling 2.0 架构系列的第三款模型,Ling-flash-2.0 以总参数 100B、激活仅 6.1B(non-embedding 激活 4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越 40B 级别 Dense 模型和更大 MoE 模型的卓越性能。
这不是一次简单的 “模型发布”。在 “大模型 = 大参数” 的共识下,Ling-flash-2.0 用极致的架构设计与训练策略,在推理速度、任务性能、部署成本之间找到了一个新平衡点。这不仅是 Ling 系列开源进程中的又一重要节点,也为当前大模型 “参数膨胀” 趋势提供了一种高效、实用、可持续的新路径。
一、从 “参数军备” 到 “效率优先”:MoE 的下一步怎么走?
在当前大模型竞争愈发激烈的背景下,参数规模似乎成为衡量模型能力的 “硬通货”。但 “参数越多 = 能力越强” 的公式,正在失效:
- 训练成本指数级上升
- 推理延迟成为落地瓶颈
- 多数参数冗余,激活效率低
MoE(Mixture of Experts)架构被寄予厚望:通过 “稀疏激活” 机制,用更少的计算,撬动更大的参数容量。但问题在于 —— 如何设计一个 “真高效” 的 MoE?
Ling-flash-2.0 的答案是:从架构、训练到推理,全栈优化。
以小博大:6.1B 激活参数,撬动 40B 性能
Ling Team 早期的关于 MoE Scaling Law(
https://arxiv.org/abs/2507.17702)的研究揭示了 MoE 架构设计 scaling 的特性。在此研究工作的指导下,通过极致的架构优化与训练策略设计,在仅激活 6.1B 参数的前提下,实现了对 40B Dense 模型的性能超越,用最小激活参数,撬动最大任务性能。为此,团队在多个维度上 “做减法” 也 “做加法”:
- 1/32 激活比例:每次推理仅激活 6.1B 参数,计算量远低于同性能 Dense 模型
- 专家粒度调优:细化专家分工,减少冗余激活
- 共享专家机制:提升通用知识复用率
- sigmoid 路由 + aux-loss free 策略:实现专家负载均衡,避免传统 MoE 的训练震荡
- MTP 层、QK-Norm、half-RoPE:在建模目标、注意力机制、位置编码等细节上实现经验最优
最终结果是:6.1B 激活参数,带来约 40B Dense 模型的等效性能,实现 7 倍以上的性能杠杆。
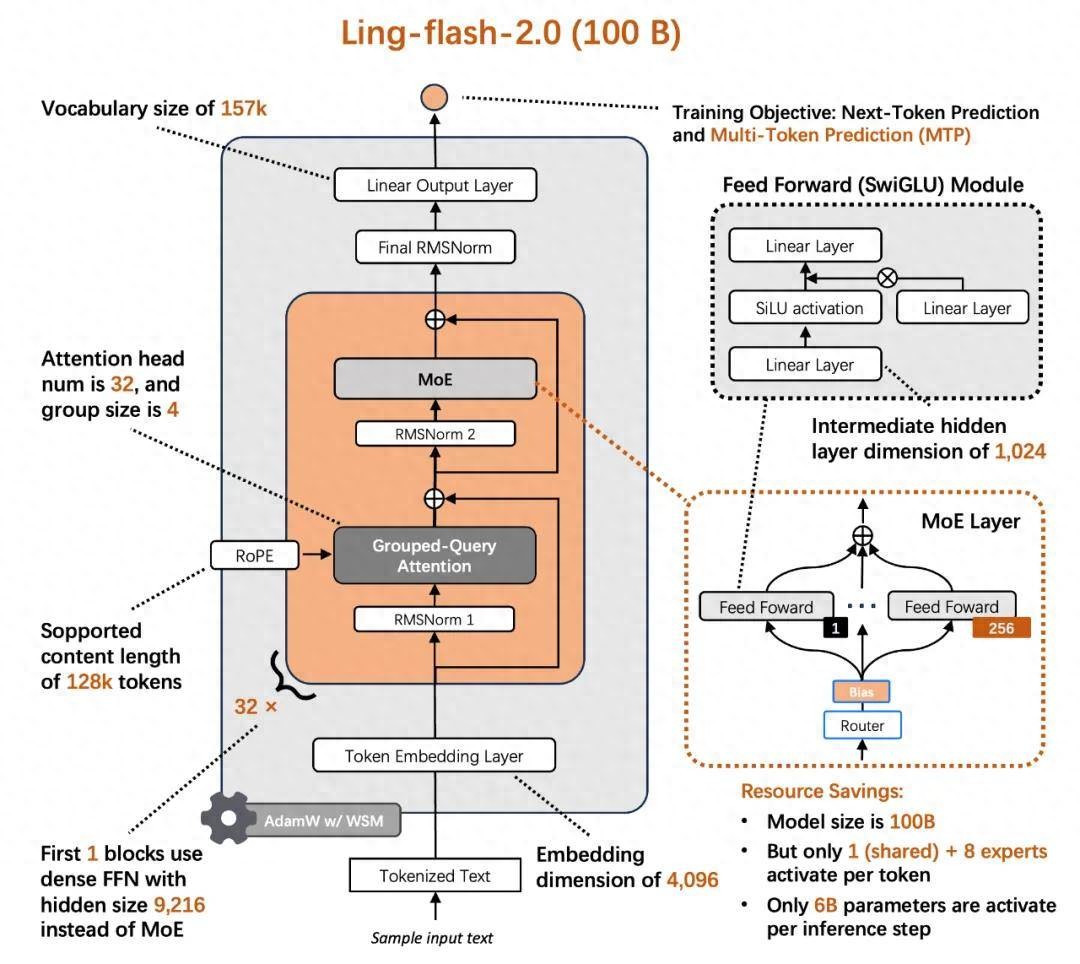
换句话说,6.1B 的激活参数,带来了接近 40B Dense 模型的实际表现,而在日常使用上推理速度却提升了 3 倍以上,在 H20 平台上可实现 200+ tokens/s 的高速生成,输出越长,加速优势越明显。

1/32 激活比例 + 7 倍性能杠杆,这一 “以小博大” 的背后,是 Ling 团队在 MoE(Mixture of Experts)架构上的深度探索。
强大的复杂推理能力
为了全面评估 Ling-flash-2.0 的推理能力,蚂蚁百灵大模型团队在模型评估中覆盖了多学科知识推理、高难数学、代码生成、逻辑推理、金融与医疗等专业领域,并与当前主流模型进行了系统对比。从下面的多个榜单分数对比可以看出,Ling-flash-2.0 不仅优于同级别的 Dense 模型(如 Qwen3-32B、Seed-OSS-36B),也领先于更大激活参数的 MoE 模型(如 Hunyuan-A13B、GPT-OSS-120B)。

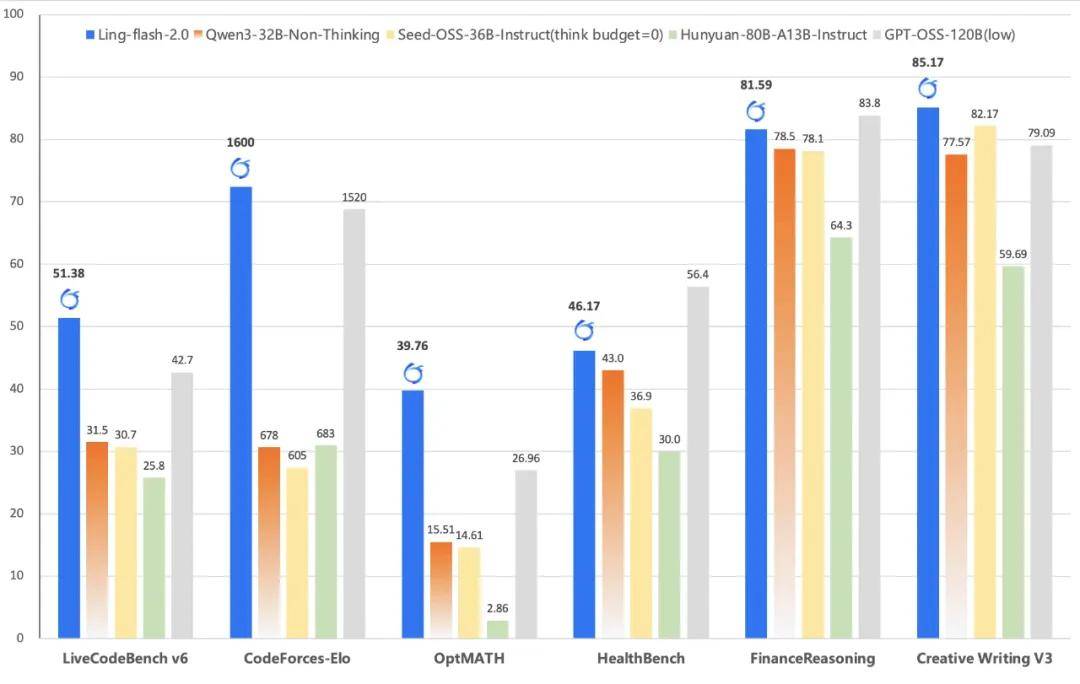
尤其在以下三类任务中表现尤为突出:
- 高难数学推理:AIME 2025、Omni-MATH
得益于高推理密度语料 + 思维链训练的预训练策略,Ling-flash-2.0 在高难数学推理 AIME2025、Omni-MATH 数学竞赛级题目中展现出稳定的推理链路与多步求解能力。
- 代码生成:LiveCodeBench、CodeForces
在功能正确性、代码风格、复杂度控制方面,Ling-flash-2.0 表现优于同规模模型,甚至在部分任务中超越 GPT-OSS-120B。
- 前端研发:与 WeaveFox 团队联合优化
通过大规模 RL 训练 + 视觉增强奖励(VAR)机制,模型在 UI 布局、组件生成、响应式设计等前端任务中,实现了 “功能 + 美学” 的双重优化。
二、不只是 “跑分”:代码生成、前端研发、推理优化全面突破
Ling-flash-2.0 的性能优势不仅体现在 “跑分” 上,更在多个实际应用场景中展现出强大能力。
丰富的用例展示
1. 代码生成与编辑
prompt1:
编写一个 Python 程序,实现10个小球在旋转六边形内部弹跳的效果。球应受到重力和摩擦力的影响,并且必须真实地碰撞旋转的墙壁。
prompt2:
提示
Traceback (most recent call last):
File "/Users/zzqsmall/Documents/code/test.py", line 131, in
if is_point_in_hexagon(x, y, hex_center, hex_radius):
NameError: name "is_point_in_hexagon" is not defined
看看哪里错了
prompt3:
输出下修改后的完整代码
prompt4:
需要考虑球和球之间的碰撞,再优化下现在的代码实现

2. 前端研发
在前端研发方面,Ling 团队携手 WeaveFox 团队,基于大规模强化学习全面升级 Ling-flash-2.0 的前端代码生成能力,为开发者打造更强大的智能编程体验。
- WeaveFox 生成:计算器生成
Prompt:做一个计算器,采用新粗野主义风格,大胆用色、高对比度、粗黑边框(3-4px)和强烈的阴影。通过原始的字体和略微不对称的布局,营造一种刻意“未经设计”的美感。按钮应采用粗边框和强烈的色彩对比度。避免使用渐变和微妙的阴影,而应采用鲜明大胆的设计元素。

- WeaveFox 生成:旅游攻略网站制作
Prompt:制作一个多语言旅游攻略网站 - 提供不同国家和城市的旅行指南,用户可以分享自己的旅行经验和照片。

- 模型直出:网页创作
Prompt:创作一个万相 AIGC 模型的海外 Landing page,黑色风格,搭配渐变紫色流动,体现 AI 智能感,顶部导航包括 overview、feature、pricing、contact us

- 模型直出:贪吃蛇
prompt:帮我写个贪吃蛇小游戏

3. 数学优化求解
- 数独问题
下面是一个数独问题,请你按照步骤求解:
1. 建模成运筹优化问题,给出数学模型。
2. 编写能够求解的 pyomo 代码。
问题是:
_ _ _|_ _ 2|9 3 _|
_ _ _|_ _ _|_ 1 5|
_ 4 6|_ _ _|_ _ 7|
-------------------
_ 6 _|8 _ 4|_ _ 9|
_ _ 8|1 _ 7|6 _ _|
4 _ _|2 _ 9|_ 5 _|
-------------------
3 _ _|_ _ _|2 9 _|
7 9 _|_ _ _|_ _ _|
_ 2 5|3 _ _|_ _ _|

4. CLI 接入
Ling-flash-2.0 模型可以方便的融合进去 Qwen Code 等 CLI 服务中,只需要在环境变量(.bashrc, .zshrc)中加入以下变量
export OPENAI_API_KEY="自己的key"
export OPENAI_BASE_URL="提供服务的url"
export OPENAI_MODEL="Ling-flash-2.0"

三、20T 语料 + 三阶段预训练:打造高质量基础模型
Ling-flash-2.0 的优异表现,离不开其扎实的预训练基础。百灵大模型团队构建了一套基于统一数据湖宽表设计的 AI Data System,支持样本级血缘管理,完成了 40T+ tokens 的高质量语料处理,并从中精选出最高质量的部分用于支持 Ling-flash-2.0 的 20T+ tokens 的预训练计划。
为了充分提升模型的知识压缩和基础推理能力,百灵大模型团队将预训练分成 3 个阶段:
- Pre-training Stage 1:10T tokens 高知识密度语料,夯实知识基础
- Pre-training Stage 2:10T tokens 高推理密度语料,提升推理能力
- Mid-training Stage:扩展至 32K 上下文,引入思维链类语料,为后训练做准备
训练过程中,关键超参数(如学习率、batch size)均由百灵大模型团队自研的 Ling Scaling Laws 给出最优配置。此外,团队还创新性地将传统的 WSD 学习率调度器替换为自研的 WSM(Warmup-Stable and Merge)调度器,通过 checkpoint merging 模拟学习率衰减,进一步提升了下游任务表现。

为增强多语言能力,Ling 2.0 将词表从 128K 扩展至 156K,新增大量多语言 token,并在训练中引入 30 个语种的高质量语料,显著提升了模型的跨语言理解与生成能力。
四、后训练创新:解耦微调 + 演进式 RL,让模型 “会思考”,也会 “说话”
高效推理能力只是起点,百灵大模型团队更希望打造一款 “能思考、能共情、能对话” 的模型,实现 “智理相济,答因境生”。
为此,团队设计了一套四阶段后训练流程:

1. 解耦微调(DFT):双模式能力奠基
通过完全解耦的系统提示词设计,模型在微调阶段同时学习 “即时回答” 与 “深度推理” 两种模式。微调数据涵盖数理科学、创意写作、情感对话、社科哲思等多个领域,并引入金融建模、工业调度、供应链优化等数学优化任务,赋予模型解决实际问题的能力。
2. ApexEval:精准筛选潜力模型
在 RL 前,团队提出 ApexEval 评测方法,聚焦模型的知识掌握度与推理深度,弱化格式和指令遵循,筛选出最具探索潜力的模型进入强化学习阶段。
3. 演进式 RL:动态解锁推理能力
在 RL 阶段,模型以简洁思维链为起点,根据问题复杂度动态 “解锁” 更深层的推理能力,实现 “遇简速答、见难思深” 的智能响应。
针对代码任务,团队统一采用测试用例驱动的功能奖励机制,并创新引入视觉增强奖励(VAR),对前端任务的 UI 渲染效果进行美学评估,实现功能与视觉体验的协同优化。
在开放域问答中,团队构建了组内竞技场奖励机制(Group Arena Reward),结合 RubriX 多维度评价标准,有效抑制奖励噪声,提升模型的人性化与情感共鸣能力。
4. 系统支撑:高效奖励系统保障训练质量
后训练奖励系统由奖励服务调度框架、策略引擎、执行环境三部分组成,支持异步奖励计算、GPU 资源时分复用,支持 40K 并发执行,为高质量数据筛选与模型迭代提供底层保障。
结语: 高效大模型的未来,不是 “更小”,而是 “更聪明”
Ling-flash-2.0 的意义,不在于 “参数小”,而在于重新定义了 “效率” 与 “能力” 的关系。
它用 6.1B 激活参数告诉我们:模型的智能,不止于规模,更在于架构、训练与推理的协同优化。
在 “参数即能力” 的惯性思维下,百灵大模型团队用 Ling-flash-2.0 提供了一种可部署、可扩展、可演进的新范式。
即:模型的智能,不止于规模,更在于架构、数据与训练策略的深度融合。
此次开源,Ling 团队不仅放出了 Ling-flash-2.0 的对话模型,也同步开源了其 Base 模型,为研究者和开发者提供更灵活的使用空间。
Base 模型在多个榜单上已展现出强劲性能,具备良好的知识压缩与推理能力,适用于下游任务的进一步微调与定制。
随着 Ling-flash-2.0 的开源,我们有理由相信,高效大模型的时代,已经到来。
Ling-flash-2.0 可在以下开源仓库下载使用:
- HuggingFace:https://huggingface.co/inclusionAI/Ling-flash-2.0
- ModelScope:https://modelscope.cn/models/inclusionAI/Ling-flash-2.0
- GitHub:https://github.com/inclusionAI/Ling-V2
文中视频链接:https://mp.weixin.qq.com/s/sWmYK-umJ9mvxx7hn4O6KA
















