

在AI音乐领域,中文歌曲的生成一直是个难题。尽管AI技术在音乐创作上取得了巨大进步,但真正能唱出中文歌曲独特韵味的AI却寥寥无几。本文将带你体验Mureka V7.5的强大功能,从简单模式到高级模式,再到音频编辑,看看它如何让中文歌曲的创作变得更加简单和有趣,甚至可能开启中文音乐创作的新篇章。

这两年,AI音乐变化有点像坐过山车。
从最早SVC翻唱,到能生成旋律、编曲的大模型,再到Suno这样的现象级应用,让很多人第一次觉得「原来我也能写」”。
但在中文歌曲领域,能真正唱出我们耳朵里那种味道的AI,还屈指可数。
所以,当我听到昆仑万维上线了一款专门为中文优化的AI音乐模型:Mureka V7.5时,第一反应是:值得试一试。
毕竟,它不仅号称在细节上,能和国际顶尖模型掰一掰手腕,还专门调教过咬字、情绪、音色,让中文歌词听起来更自然、更有情感。
抱着好奇,第一时间打开了它。结果,生成后第一首歌就让我愣住了,情绪起伏、咬字的细腻感,是我在AI歌曲里很少听到的。
话不多说,先听歌:
感觉怎么样?进入首页,操作页面非常简洁,「创作音乐」区域有三个模块:简单模式、高级模式、音频编辑。
我先选择简单模式。让AI帮我想了个提示词:
写一首流行摇滚风的中文歌曲,歌名叫《诺基亚的夏天》。讲述一个少年时代的爱情故事,从短信、慢歌、校服,到毕业分离;主歌温暖怀旧,副歌情绪瞬间拉高,像是压抑多年后的情感宣泄。
没想到,它没有机械地照搬,帮我优化了提示词,还补充了创意说明和音乐细节。我只要点「下一步」,剩下就是傻瓜式等待。
不到一分钟,成了。上面你听到的。高潮部分「那个夏天」几个字冲上来的瞬间,情绪被点燃,感觉耳蜗把我带到了校园场景。
情绪还没散,我直接切到高级模式,想整一首更有空间感的歌,参考歌曲、歌手、歌词描述、甚至哼唱旋律,都能自己调。
选了个Pop风的嗓音,起了歌曲名叫《重力之外》,自己写版歌词,不过,好像不够味儿,干脆交给一键生成。
前奏一出来,厚实的合成器铺底,像一层雾拨开,主歌里乐器的留白也很克制,让我忍不住想去听完后面有没有什么惊喜瞬间。
第三轮,我想换个口味,看看Mureka在柔和情绪里能玩到什么程度,就选了 R&B。
给它的提示是:
夜晚的城市,潮湿的路面,路灯在雨幕里晕成一圈一圈的光。
节奏要松弛点,旋律要带着慵懒的呼吸。
前奏一响,低沉的贝斯,像雨点敲车窗;
主歌里,嗓音带着沙哑,好像隔着雨雾,在说一段很久以前的故事;
副歌、和声慢慢叠上来,情绪也不急不躁,让人忍不住一遍遍循环。
玩到这一步,有点上瘾。我翻了下它的曲库,发现选项夸张到离谱;曲风有23种,从古典、世界音乐、朋克、金属,到蓝调、民谣一应俱全。还能叠加情绪,比如欢快、浪漫、活力”等等。
这次我选了「世界音乐」,因为这种风格常有民族打击乐、空灵和声,以及像风一样的流动感。
我给它取了个名字:《风从远方来》。
一生成,第一秒的鼓声就一拍一拍砸进耳朵里,心跳一下被放大了,催着你往前走;背景里的空灵和声在游走,像远处有人在呼喊。旋律不拐弯,很快把我带进状态。
到这,我在想,能不能再来点「进阶玩法」?因为不可能所有音乐一次性做出来都非常满意。
然后发现,音频编辑能力也很好玩。这里有四个方面:
局部编辑,能针对某一段歌词重新生成旋律和演唱,不用推倒重来。比如:一首歌里有一句情绪不到位,可以单独修改,让整首歌的情绪一致。
延长,就是给有歌曲加长,比如副歌太短,直接无缝接一个延长段落,保持同样的风格和氛围。乐器分轨,可以把任何一首歌拆成鼓、贝斯、吉他、伴奏等单独轨道,这个功能玩混音、做翻唱的人会爱死。
剪裁就不说了,觉得哪里不满意,直接减掉即可。
像我这样纯好奇去玩的人,也能感受到它的细节做得很到位,编辑响应快、衔接流畅,没有那种“AI 硬拼接”的违和感。
不过,写再多都不如你真实感受下,再放几首我做的,能进到你的耳蜗里吗:
这些歌,我只是随手玩出来的,如果它们能让你哪怕有一秒跟着哼,就算值了;玩到这里,用 Mureka V7.5,三个模式我算是都跑了一遍。
不管是咬字,情绪还是旋律推进,都蛮自然的,不像过去很多 AI 歌曲,听着像卡在喉咙里。
所以,你有没有想过一个问题:为什么过去 AI 中文歌总是不好听?
很多人以为 AI 中文歌难听,因为模型不够强大、算力不够。但真正原因是,大多数模型的「耳朵」是用英文音乐训练出来的。
换句话说,它们理解的是西方旋律结构、英文的音节节奏,而不是汉语的声调、语感和文化氛围。
汉语音高变化本身就带有旋律,一个字的平、上、去、入,会影响一句话的旋律走向,这对 AI 来说,像学一门完全不同的乐器。
我第一次在老款 AI 歌曲里听到「爱你」两个字时,差点没认出来。模型把「爱」唱得像英文的 「I」,而「你」则完全丢了尾音的起伏,瞬间情绪断层。
词和曲的脱节,更是常见问题。
过去AI 歌曲生成,更像先做旋律,再硬塞歌词。尤其中文,字与字之间没有空格,歌词按意群和韵脚排布,但 AI 并不懂这种分句习惯。
于是,我们就会听到:
有些句子尾音被拉得很怪,只是为了凑节拍;有些情感词(比如想你、再见)落在了旋律的弱拍上,唱出来没力度。
英文歌里,这些问题不明显,因为英语的重音规律和四四拍天然契合。但中文歌,哪怕一个词落错拍,整句都不对味。
还有情绪。早期的 AI 歌曲,大多靠音量、速度去模拟情绪,快一点显得兴奋,慢一点就是悲伤。但人类的情绪变化不是调节按钮,而是从气息、咬字、甚至停顿里自然长出来的。
这些细节,过去AI 很难兼顾,它们听得懂音符,却听不懂中文歌的“呼吸”,也感受不到歌词背后的文化情绪,于是,就有了听起来像在唱中文,却没有唱出中文的味道。
那Mureka V7.5 又是怎么跨过这些门槛的呢?
后来我忍不住去翻了背后的技术细节。才发现,Mureka V7.5 这次能唱出「中文耳朵的味道」,并不单靠算力或者随便加点训练量,是把整个模型的「耳朵和大脑」都换了。
它用大量优质的中文歌曲去重新调教,让 AI 真正学会汉语的声调、韵律和情绪落点。
不再像过去那样用英文旋律去套中文歌词,那种平、上、去、入的微妙变化,它都能识别出来并融进旋律里,甚至会根据歌词里的意境去调整音高和节奏。
就像训练一个外国歌手唱京剧,不仅要教他吐字,还要让他懂得那个“味儿”。
V7.5还学会了听歌词,是先理解歌词的意群和情感,再去规划旋律的走向。
比如一个:想你,它会刻意把“想”落在情绪高点,让那种牵挂的张力自然出来,这种理解力,靠它在底层用 ASR(语音识别)技术做了优化,让模型能精准对齐字与音的关系。
换句话说,它一边唱歌一边看着歌词,每个字该重、该轻都心里有数。
还有一点很关键,它用了一套叫 MusiCoT 的架构去生成音乐,你可以把它理解成,AI是先学人类的创作逻辑,先构思情绪走向、段落结构,再细化到旋律和配器。
这样做的结果,是它的歌听起来更像一个有想法的创作者写出来的。
有一个对比数据:
Mureka V7.5的「音乐性」评分比同类高了 34.8%,歌词与旋律的契合度高了 45.2%。这些数字背后,其实就是你耳朵里那种“顺”的感觉。
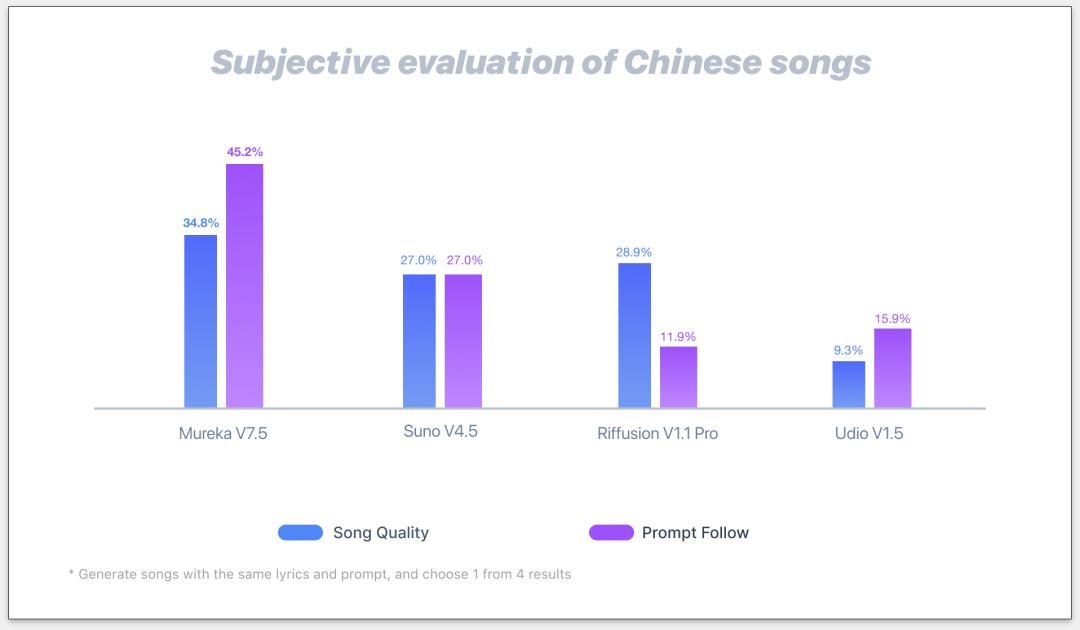
图释: 在中文音乐生成评测中,Mureka V7.5 的歌曲质量和提示跟随表现均领先其他模型。
如果只谈技术升级,也还是工具的进步。我在意它把中文歌的创作门槛降下来了,让不会谱曲的人、写歌词有障碍的人,都能用母语做出一首有记忆、有情绪的歌。
这相当于一次文化上的守护。
毕竟在全球 AI 音乐潮流里,小语种音乐往往被忽视,而 Mureka V7.5 相当于在告诉我们中文歌的美感和文化,不必被牺牲在技术的统一标准下。
甚至我会想,未来孩子们的第一首原创歌,可能不再是五线谱上的笨拙哼唱,是他们用自己的话、自己的情绪,让 AI 帮他们唱出来的。
从更长远角度看,这可能也和昆仑万维的多模态布局、开源战略价值观连在一起的。
它试图在搭一套让更多人用中文去表达、去创造的底层能力,这样的投入,是那种你放在十年后回看,会觉得「好在那时候有人做了这件事」的事情。
或许未来某一天,我们会发现,陪伴一代人成长的旋律,不一定诞生在录音棚里,也可以诞生在每一个有故事、有情绪的人手中。
那时,我们回头看今天,可能会说,原来中文歌的新篇章,就是从这里翻开的。
文:王智远 本文由人人都是产品经理作者【王智远】,微信公众号:【王智远】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。















