
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 功能:支持超低延迟的流式语音合成,首包合成延迟仅150ms。
- 性能:发音准确性显著提升,音色一致性和韵律自然度大幅改善。
- 技术:采用全尺度量化和离线流式一体化建模,支持多语言和指令可控的音频生成。
正文(附运行示例)
CosyVoice 2.0 是什么

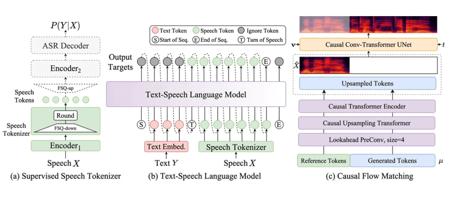
CosyVoice 2.0 是阿里巴巴通义实验室推出的语音生成大模型升级版,旨在通过有限标量量化技术和块感知因果流匹配模型,提升语音合成的质量。该模型简化了文本-语音语言模型架构,支持多样的合成场景,并在发音准确性、音色一致性、韵律和音质上都有显著提升。
相比前版本,CosyVoice 2.0 的MOS评测分从5.4提升到5.53,支持流式推理,大幅降低首包合成延迟至150ms,适合实时语音合成场景。此外,它还支持多语言和跨语言语音合成,能够满足不同应用场景的需求。
CosyVoice 2.0 的主要功能
- 超低延迟的流式语音合成:支持双向流式语音合成,首包合成延迟可达150ms,适合实时应用场景。
- 高准确度的发音:相比前版本,发音错误率显著下降,尤其在处理绕口令、多音字、生僻字上表现突出。
- 音色一致性:在零样本和跨语言语音合成中保持音色高度一致性,提升合成自然度。
- 自然体验:合成音频的韵律、音质、情感匹配得到提升,MOS评测分提高,接近商业化语音合成大模型。
- 多语言支持:在大规模多语言数据集上训练,实现跨语言的语音合成能力。
CosyVoice 2.0 的技术原理
- LLM backbone:基于预训练的文本基座大模型(如Qwen2.5-0.5B),替换原有的Text Encoder + random Transformer结构,进行文本的语义建模。
- FSQ Speech Tokenizer:用全尺度量化(FSQ)替换向量量化(VQ),训练更大的码本(6561),实现100%激活,提升发音准确性。
- 离线和流式一体化建模方案:提出一体化建模方案,让LLM和FM均支持流式推理,实现快速合成首包音频。
- 指令可控的音频生成能力升级:优化基模型和指令模型的整合,支持情感、说话风格和细粒度控制指令,新增中文指令处理能力。
- 多模态大模型技术:基于多模态大模型技术,实现语音识别、语音合成、自然语言理解等AI技术,提供“能听、会说、懂你”式的智能人机交互体验。
如何运行 CosyVoice 2.0
环境配置
克隆仓库并安装依赖:
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git cd CosyVoice git submodule update --init --recursive创建 Conda 环境并安装依赖:
conda create -n cosyvoice python=3.10 conda activate cosyvoice conda install -y -c conda-forge pynini==2.1.5 pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
模型下载
from modelscope import snapshot_download
snapshot_download("iic/CosyVoice2-0.5B", local_dir="pretrained_models/CosyVoice2-0.5B")
snapshot_download("iic/CosyVoice-300M", local_dir="pretrained_models/CosyVoice-300M")
基本使用
from cosyvoice.cli.cosyvoice import CosyVoice2
cosyvoice = CosyVoice2("pretrained_models/CosyVoice2-0.5B", load_jit=True, load_onnx=False, load_trt=False)
# 零样本推理
prompt_speech_16k = load_wav("zero_shot_prompt.wav", 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot("收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。", "希望你以后能够做的比我还好呦。", prompt_speech_16k, stream=False)):
torchaudio.save("zero_shot_{}.wav".format(i), j["tts_speech"], cosyvoice.sample_rate)
资源
- 项目官网:https://funaudiollm.github.io/cosyvoice2/
- GitHub 仓库:https://github.com/FunAudioLLM/CosyVoice
- 技术论文:https://funaudiollm.github.io/pdf/CosyVoice_2.pdf
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦





发表评论 取消回复