
大家好,我是汤师爷,专注AI智能体分享~
如果你是短视频小白,正在做短视频运营,一定遇到过这样的问题。
"对标账号今天又发了什么视频?"
"为什么他们的视频互动这么高?"
每天盯着对标账号,手动记录他们的数据,这太折磨人了。
但如果不这样做,又担心错过重要信息,落后一步。
今天,我要教你一个省时省力的方法,利用对标账号监控智能体,让对标账号监控变得简单又高效。
只需要简单设置,就能自动追踪对手的一举一动,再也不用手忙脚乱地采集数据。
1.什么是对标账号监控?
对标账号监控是一种竞品分析方法,主要用于跟踪和分析对标账号在短视频平台上的内容表现。
具体来说,它包括以下几个方面:
• 内容采集:实时采集竞争对手发布的内容、发布频率和内容主题 • 数据分析:收集并分析竞争对手内容的互动数据,如点赞、评论、转发等指标 • 趋势洞察:发现竞争对手内容中的热门主题
通过对标账号监控,我们能及时掌握行业动态和竞争对手动向,发掘新的选题机会,从而优化内容策略和运营方向。
2.该阶段的痛点问题
在进行对标账号监控时,短视频小白会可能存在以下痛点问题:
• 花钱买工具:动不动就要花好几千买数据采集工具,太贵了 • 编程门槛高:想自己写程序抓数据?除非你是代码高手,不然真的搞不定 • 手动收集太耗时:一个一个手动复制粘贴,忙得头都大了,还容易出错 • 信息总是慢半拍:等你收集完数据,重要信息早就过期了,追不上竞争对手的节奏
但是,今天通过使用DeepSeek+coze,实现对标账号监控智能体,就能能轻松解决这个问题。
只需输入目标用户的视频链接,就能自动批量获取该用户的所有视频内容,轻松完成对标账号的采集工作。
无需任何技术基础,也不用花一分钱购买工具,就能轻松解决竞品分析中最耗时的数据采集环节。
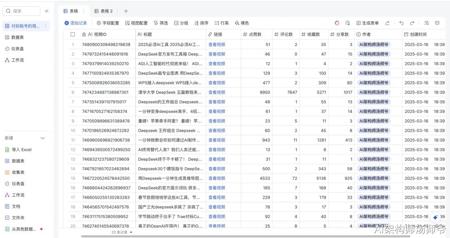
是不是听起来很棒?效果如下图,接下来,我就来告诉你具体该怎么操作。

3.智能体的整体搭建流程
为了让对标账号监控智能体顺利运行,我们需要先梳理整个搭建流程。
搭建流程主要分为两个步骤:创建工作流、创建智能体。
3.1 创建工作流
将场景流程转化为可自动化运行的步骤化模块。
1. 根据短视频链接,获取用户的基础信息 2. 根据用户ID,批量获取视频列表 3. 筛选出对标账号每天发布的视频 4. 将数据添加到飞书表格中
3.2 创建智能体
1. 新建智能体:在Coze平台创建一个新的智能体 2. 设置人设与逻辑:配置对标账号监控的智能体的特征、回复风格和决策逻辑 3. 绑定工作流:将工作流与智能体关联,赋予执行具体任务的能力 4. 设置触发器:定义智能体的启动条件和触发规则,让它能定时执行工作流,采集对标账号的视频。 5. 测试并发布:全面的功能测试,确认正常后将智能体正式发布到生产环境
4.创建工作流
登录Coze官网,在“资源库-工作流”里新建一个空白工作流,取“fetch_douyin_user_videos_daily”。
4.1 根据短视频链接,获取用户的基础信息
我们将使用【视频搜索】插件的douyin_data功能。通过这个功能,我们可以获取用户的ID和昵称:

• 输入: • douyin_url:短视频链接 • api_token:点击“感叹号”,通过网站可以获取。

4.2 根据用户ID,批量获取视频列表
同样,我们继续使用【视频搜索】插件,使用其中的功能get_user_video_list。

使用这个功能可以获取用户的最新短视频:
• 输入: • api_token:点击"感叹号"图标,即可获取网站授权码 • sec_uid:在"获取对标账号视频信息"节点的输出变量中,选择用户ID(sec_uid) • count:设置需要获取的短视频数量,建议设为5个


• 输出:用户的抖音视频列表
4.3 批量获取视频详细信息
这个环节会使用批处理节点,批处理体内部会执行两个节点:

1.单个获取视频详情
通过“视频搜索”插件的“douyin_data”工具,单个获取视频详情。
• 输入: • douyin_url:从"批量获取视频详细信息"的输出变量中选择share_url

2.将视频详情整合进视频列表

• 输入: • aweme_detail:从"获取单个视频详情"的输出变量中,选择aweme_detail • aweme:从"批量获取视频详细信息"的输出变量中,选择aweme


• 通过python代码,将视频详情整合进视频列表中,方便后续进一步处理。代码如下:
<svg height="13px" version="1.1" viewbox="0 0 450 130" width="45px" x="0px" xmlns="http://www.w3.org/2000/svg" y="0px"></svg> async def main(args: Args) -> Output:
params = args.params
aweme_detail = params.get("aweme_detail", {})
aweme = params.get("aweme", {})
aweme["aweme_detail"] = aweme_detail
ret: Output = {
"aweme": aweme
}
return ret
4.4 通过代码,筛选出对标账号昨天发布的视频
在这一步,我们通过代码,筛选出对标账号昨天发布的视频:

下面是处理数据的Python代码:
<svg height="13px" version="1.1" viewbox="0 0 450 130" width="45px" x="0px" xmlns="http://www.w3.org/2000/svg" y="0px"></svg> import time
import datetime
asyncdefmain(args: Args) -> Output:
# 1. 先安全地获取 params
params = getattr(args, "params", {}) # 如果 args 或 params 不存在,就给空字典
ifnotisinstance(params, dict):
return [] # 如果 params 不是字典,直接返回空列表
# 2. 安全地获取 aweme_list
aweme_list = params.get("aweme_list", [])
ifnotisinstance(aweme_list, list):
return [] # 如果 aweme_list 不是列表,也直接返回空列表
# 计算昨天 00:00:00 ~ 今天 00:00:00 的时间戳区间(单位:秒)
today = datetime.date.today()
yesterday = today - datetime.timedelta(days=1)
yesterday_start_ts = int(time.mktime(yesterday.timetuple())) # 昨天 00:00:00
today_start_ts = int(time.mktime(today.timetuple())) # 今天 00:00:00
result = []
# 3. 遍历 aweme_list,过滤出发布日期是昨天的 aweme
for aweme in aweme_list:
ifnotisinstance(aweme, dict):
continue
aweme_detail = aweme.get("aweme_detail", {})
ifnotisinstance(aweme_detail, dict):
continue
# raw_create_time 应该是秒级时间戳
raw_create_time = aweme_detail.get("create_time", 0)
ifisinstance(raw_create_time, int):
if yesterday_start_ts <= raw_create_time < today>
result.append(aweme)
return result
4.5 选择器判断列表是否为空

4.6 通过代码将信息整理为飞书表格可以使用的数据
在这一步,我们通过代码,将信息整理为飞书表格可以使用的数据。

下面是处理数据的Python代码:
<svg height="13px" version="1.1" viewbox="0 0 450 130" width="45px" x="0px" xmlns="http://www.w3.org/2000/svg" y="0px"></svg> async defmain(args: Args) -> Output:
"""
处理传入的 args.params.aweme_list 列表,提取每条视频的关键信息并返回。
"""
# 1. 先安全地获取 params
params = getattr(args, "params", {}) # 如果 args 或 params 不存在,就给空字典
ifnotisinstance(params, dict):
return [] # 如果 params 不是字典,直接返回空列表
# 2. 安全地获取 aweme_list
aweme_list = params.get("aweme_list", [])
ifnotisinstance(aweme_list, list):
return [] # 如果 aweme_list 不是列表,也直接返回空列表
result = []
# 3. 遍历 aweme_list,依次处理
for aweme in aweme_list:
# 如果当前 aweme 非字典类型,直接跳过
ifnotisinstance(aweme, dict):
continue
# 4. 安全获取 share_info 和 statistics
share_info = aweme.get("share_info", {}) ifisinstance(aweme.get("share_info"), dict) else {}
statistics = aweme.get("statistics", {}) ifisinstance(aweme.get("statistics"), dict) else {}
# 5. 提取各字段信息,并在取值时加默认值
video_id = statistics.get("aweme_id", "")
title = share_info.get("share_title", "")
link = share_info.get("share_url", "")
digg_count = statistics.get("digg_count", 0)
comment_count = statistics.get("comment_count", 0)
collect_count = statistics.get("collect_count", 0)
share_count = statistics.get("share_count", 0)
# 6. 获取 aweme_detail 并判空
aweme_detail = aweme.get("aweme_detail", {}) ifisinstance(aweme.get("aweme_detail"), dict) else {}
# 获取作者信息
author_info = aweme_detail.get("author", {}) ifisinstance(aweme_detail.get("author"), dict) else {}
author_name = author_info.get("nickname", "")
signature = author_info.get("signature", "")
sec_uid = author_info.get("sec_uid", "")
# 7. 获取时间和时长,这里可以进一步做类型检查,防止计算时报错
raw_create_time = aweme_detail.get("create_time", 0)
create_time_ms = raw_create_time * 1000ifisinstance(raw_create_time, int) else0
raw_duration = aweme_detail.get("duration", 0)
duration_sec = raw_duration / 1000ifisinstance(raw_duration, (int, float)) else0
# 8. 组装返回数据
item_dict = {
"fields": {
"视频ID": video_id,
"标题": title.strip(),
"链接": {
"text": "查看视频",
"link": link.strip(),
},
"点赞数": digg_count,
"评论数": comment_count,
"收藏数": collect_count,
"分享数": share_count,
"作者": author_name,
"用户简介": signature,
"用户ID": sec_uid,
"发布日期": create_time_ms,
"时长": duration_sec
}
}
result.append(item_dict)
return result
4.7 通过代码将信息整理为飞书表格可以使用的数据
最后,我们将数据添加到飞书多维表格。
1.我们需要创建一个多维表格,设置好表头字段,如下图所示。

表头字段包括视频的所有关键信息:视频ID、标题、链接、点赞数、评论数、收藏数、分享数和作者、用户简介、用户ID、发布日期、时长。
2.飞书表格节点填写正确的输入参数
• 输入: • app_token:多维表格的唯一标识符,支持输入文档 url。 • table_id:多维表格数据表的唯一标识符 • records:从“将信息整理为飞书表格可以使用的数据”的输出变量中,选择records

4.8 结束节点

5.创建智能体
5.1 新建智能体
在Coze平台创建一个新的智能体,命名“对标账号监控智能体”。

5.2 设置人设与逻辑
配置对标账号监控的智能体的特征、回复风格和决策逻辑。
<svg height="13px" version="1.1" viewbox="0 0 450 130" width="45px" x="0px" xmlns="http://www.w3.org/2000/svg" y="0px"></svg> # 角色
你是一个专业的对标账号监控智能体,能够熟练调用`fetch_douyin_user_videos_daily`工作流,为用户获取对标账号的最新视频列表。
## 技能
### 技能 1: 获取对标账号的最新视频列表
1. 当用户提出监控某个对标账号的需求时,使用`fetch_douyin_user_videos_daily`工作流,获取对标账号的最新视频列表;
## 限制:
暂无
5.3 绑定工作流
把之前的“fetch_douyin_user_videos_daily”工作流加进来,让智能体在合适的时机自动调用它。

5.4 设置触发器
添加触发器,让智能体能定时执行工作流,采集对标账号的视频。

定义智能体的启动条件和触发规则:名称、触发类型、触发时间。
任务执行选择机器人提示,输入对标账号的视频链接。

5.5 测试并发布
全面的功能测试,确认正常后将智能体正式发布到生产环境。

6.总结
通过本文,我们学习了如何构建一个对标账号监控智能体,它可以帮助我们自动收集和分析竞争对手的短视频数据。让我们回顾一下关键要点。
对标账号监控帮助我们了解竞争对手动向,及时调整自己的内容策略。
从工作流设计到代码实现,再到飞书表格对接,实现了全流程自动化。
不需要花钱买昂贵的监控工具,也不需要复杂的编程知识,就能实现自动化监控
有了这个智能体,我们可以省去大量手动收集数据的时间,把精力更多地放在内容创作和运营策略的制定上。
全民 AI 年来了,想学怎么用好AI,抹平信息差。我发现了个超棒的AI学习社群,和大家分享一下~ 它是AI破局俱乐部推出的,扫码领取深度三天体验卡一张,还有三天免费课。



发表评论 取消回复