你以为智能体只是“能聊天”?其实它有“五脏六腑”。感知是眼,决策是脑,规划是意图,执行是动作,记忆是经验,学习是成长。这篇文章带你一次看懂智能体的底层构造,理解它为什么越来越像“人”,也越来越值得被产品化。

在第一篇《智能体:AI的下一场革命?》里,我们把Agent比作一位“个人助理”。今天,我们就把这位助理请上手术台,拆开看看它到底靠什么“活”得这么像人。
别担心,全程无血,只有例子和概念。读完你会明白:Agent智能体就是一台精密的“五件套”机器。
一台自动咖啡机,它要:
- 看见杯子(感知)
- 想明白你要拿铁还是美式(大脑/决策)
- 决定先做咖啡再倒奶(规划与执行)
- 记得你上次要半糖(记忆)
- 下次你再说“老样子”它就能做对(学习与适应)
Agent的五大模块,跟自动咖啡机的逻辑几乎一一对应。下面逐个拆。
01 感知模块 – Agent的“眼睛和耳朵”
感知模块是智能体的“眼睛和耳朵”,负责从外部环境中收集各种信息,这是智能体与外界交互的第一步。它能看见什么?很多:
- 文字:聊天窗口、邮件、文档、网页。
- 语音:(通过语音识别ASR)听懂你的语音命令。
- 图像/视频:(通过多模态模型)识别图片中的物体、分析图表数据、读懂界面元素。
- 结构化数据:表格、数据库、API返回的JSON。
但是感知≠看懂。前阵子有博主测评刚刚推出的GPT-5,在“数图中有多少个圆圈”这类任务上仍有错误率。可见,把像素变成意义,比人类想像的难。
中国科学院院刊2025年第3期《政策与管理研究》曾指出,英文多模态数据是中文的8倍左右,因此中文Agent的视觉“近视”更明显。一句话,任何能塞进计算机0和1的东西,都能被Agent“感知”。
02 大脑/决策模块 – Agent的“指挥官”
神经科学里,海马体负责记忆,额叶负责推理。LLM其实把两者合并在了一起:
- 快思考:直接给出答案,像人脑“直觉”。
- 慢思考:Chain-of-Thought(思维链),先写草稿再回答,准确率可提升10%~30%
当智能体接收到用户的任务指令后,LLM会对指令进行理解和分析。比如,用户要求智能体写一份行业报告,LLM会搜索最新趋势→抓取竞品数据→生成报告大纲→撰写内容并排版。
然后,基于从海量数据中学习到的知识与经验,LLM开始规划在每一步中决定接下来做什么以及调用哪个工具。
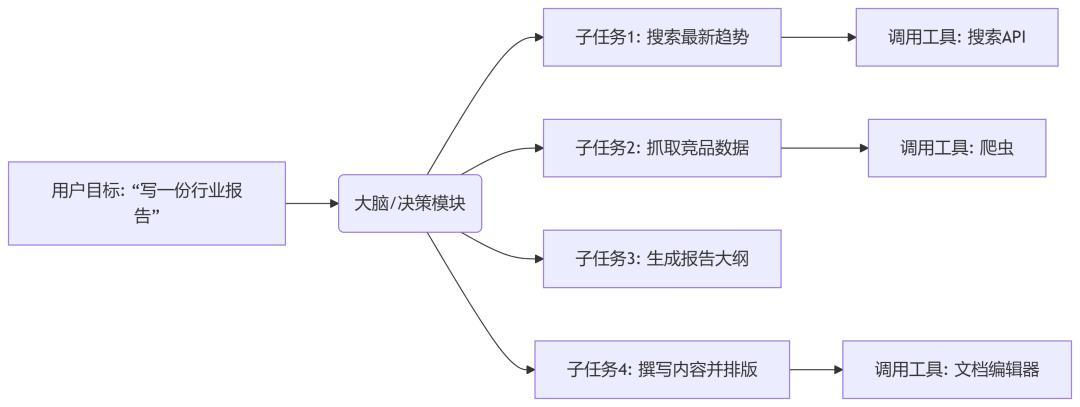
在推理过程中,LLM就会运用思维链等方法,将复杂问题分解为多个逻辑步骤,逐步推导得出解决方案。
顺便提一下,大家都知道LLM有“幻觉”现象,即生成看似合理但与事实不符的内容。为了弥补这一不足,我们就会引入RAG、知识图谱,为大语言模型提供更准确、结构化的知识支持,从而提升其决策的准确性与可靠性。
一句话:LLM在此并非直接“回答”问题,而是扮演“规划师”和“调度员”的角色,强大的逻辑链推理能力是拆解复杂任务的关键。
03 规划与执行模块 – Agent的“手和脚”
人类点外卖时会自然拆步骤:打开App→选餐厅→加购物车→结算。Agent也得把“写一篇行业报告”拆成“搜索→读文章→整理大纲→填充段落→校对”,并调用外部工具来完成具体操作。
LangChain的统计显示,一个典型研究任务平均需要调用5.2个外部工具,最复杂的可到20个以上。那工具集(Toolbox)里有什么?
- 基础工具:计算器、日历。
- 网络工具:搜索引擎、API接口(如天气查询、邮件发送、支付接口)。
- 专业工具:Photoshop、数据分析软件、代码解释器。
- 硬件工具:控制机械臂、调节智能家居开关。
当智能体为用户制定好写报告计划后,便进入执行阶段:大脑发出“调用搜索API”指令→本模块找到对应工具→格式化输入参数→执行调用→获取返回结果→送回给大脑进行下一步分析。
一句话:工具使用能力是Agent区别于纯聊天机器人的分水岭,它让Agent的能力边界得以无限扩展。
04 记忆模块 – Agent的“日记本与知识库”
记忆模块负责存储和快速检索信息,让Agent拥有长期记忆和个性化上下文,避免“金鱼脑”。它主要分为短期上下文记忆和长期存储记忆两部分。
- 短期:对话窗口里的上下文窗口,容量有限(8k~128ktoken)。像便签,对话关闭后即“遗忘”。
- 长期:一个独立于对话的外部存储系统,通常是向量数据库。像档案柜,下次开机还在。
但是,向量数据库的检索逻辑并非“精确匹配”,这是因为向量数据库的核心是通过向量相似度计算来检索数据。具体来说:
首先,所有数据(文本、图像、音频等)会被转化为高维向量(通过嵌入模型,如BERT、Sentence-BERT等),向量的距离或夹角代表数据的语义相似度。
当用户输入查询时,查询也会被转化为向量,数据库通过计算查询向量与库中所有数据向量的相似度,返回“最相似”的结果。
这种逻辑决定了它的检索结果是“语义相关”优先,而非传统数据库的“精确匹配”(如SQL的=或like)。因此,“准确性”在这里更偏向于“结果是否与查询意图相关”,而非“是否严格符合某个精确条件”。
下面对两种类型数据库做个对比:
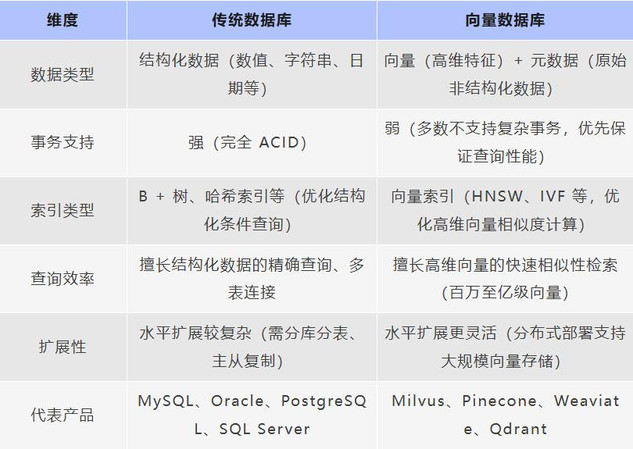
有数据显示,74%的企业级Agent部署了向量数据库,但仍有46%的开发者抱怨“检索不准”,说明长期记忆不只是“存”,还得“找得快、找得准”。
所以,在对准确性要求极高的场景,如医疗诊断、法律检索等,需结合具体场景优化技术细节,并对检索结果的内容进行二次验证。
一句话:记忆模块让Agent能够学习和个性化,从一个通用工具变成你的专属助手。即使相隔数月,Agent也能“想起”你“不喜欢报告背景是黄色”或“上次项目的最终数据”。
05 学习与适应模块 – Agent的“进化引擎”
学习与适应模块是让Agent具备“从过去的经历中学习,并用学到的东西应对新情况”的能力。该模块主要通过两大机制实现功能:学习机制(获取新知识)和适应机制(应用知识应对变化),二者相辅相成。
常见的学习机制包括:
- 监督学习:通过“标注数据”学习输入与输出的映射关系。例如,智能客服的意图识别模块通过标注的“用户问句-意图标签”数据,学习识别用户需求。
- 无监督学习:从无标注数据中自主发现隐藏规律。例如,推荐系统通过分析用户行为数据(如浏览、购买记录),无监督地聚类“相似用户”,从而优化推荐策略。
- 强化学习:通过与环境的交互(“试错”)学习最优策略。例如,机器人通过“行动-获得奖励/惩罚”的循环,学习在迷宫中找到出口的最短路径(奖励:靠近出口;惩罚:撞到墙壁)。
- 多任务学习:同时学习多个相关任务,通过任务间的知识共享提升效率。例如,自动驾驶系统同时学习“车道保持”和“障碍物避让”,两个任务共享路况感知的底层知识。
常见的适应机制包括:
- 在线学习:在实时交互中持续更新模型。例如,语音助手在使用过程中,不断根据用户的口音、用词习惯微调识别模型,提高准确率。
- 迁移学习:将在A任务中学到的知识迁移到B任务(A和B相关),减少重复学习成本。例如,已学会“识别猫”的模型,可通过迁移学习快速掌握“识别老虎”(二者均为猫科动物,共享部分特征)。
- 鲁棒性调整:应对环境突发变化(如传感器故障、未知干扰)。例如,无人机在遇到强风时,通过实时调整飞行姿态模型(基于历史抗风数据学习的规则),维持稳定飞行。
- 元学习:学习“如何快速学习新任务”。例如,机器人通过元学习掌握“抓取物体的通用策略”,之后遇到新形状的物体时,只需少量尝试就能调整抓取方式。
但是,如果用户群体单一,Agent可能学会“讨好”而失真。Anthropic提出“Constitutional AI”:给Agent写一份“行为宪法”,防止它一味迎合。
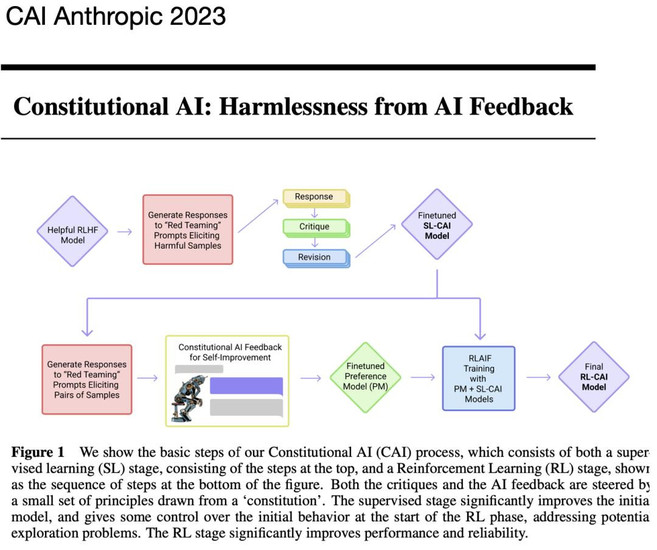
一句话:学习与适应模块是高级Agent的标志,使其行为不再僵化,能够持续改进,适应复杂多变的环境。
06 Agent实战:一个3分钟的“订健康餐”实战
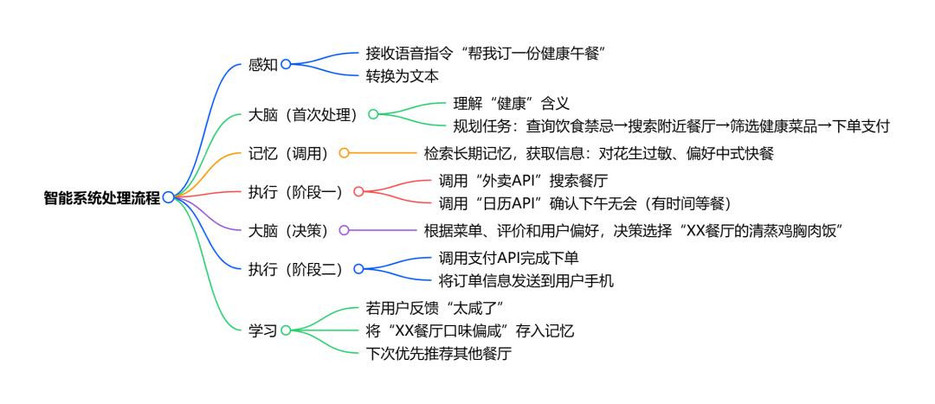
让我们用一个订餐Agent的例子,看五大模块如何流水线作业,完成“帮我订一份健康午餐”的任务:
你只需要告诉订餐Agent需求,它会
- 感知:接收你的语音指令“帮我订一份健康午餐”,转换为文本。
- 大脑:理解“健康”的含义,规划任务:查询你的饮食禁忌→搜索附近餐厅→筛选健康菜品→下单支付。
- 记忆:检索长期记忆,发现你“对花生过敏”且“偏好中式快餐”。
- 执行:调用“外卖API”搜索餐厅,调用“日历API”确认你下午无会,有时间等餐。
- 大脑:根据菜单、评价和你的偏好,决策选择“XX餐厅的清蒸鸡胸肉饭”。
- 执行:调用支付API完成下单,并将订单信息发送到你的手机。
- 学习:如果你反馈“太咸了”,它会将“XX餐厅口味偏咸”存入记忆,下次优先推荐其他餐厅。
下期预告:智能体的“超能力”之源
你如果仔细阅读会发现,工具使用是Agent能力的倍增器。下一篇将深度解密Agent的“工具箱”:它如何学会使用成千上万的工具?为什么说工具生态的成熟是Agent爆发的关键?
作者:阿木聊AI(智能体),公众号:Agent智能体
本文由 @阿木聊AI(智能体) 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务