
来扒一扒OpenAI算力支出的天价账单——
爆款产品的最终训练占小额,大部分钱花在了幕后实验上。
据Epoch AI统计的数据显示,去年OpenAI在计算资源上支出了70亿美元。
由于公司当时还没有大量的算力,所以这笔天价账单基本都是以向微软租用云算力的形式支付出去的,并不包括对数据中心的前期投入。
70亿中,包括大约50亿美元用于研发算力(涵盖所有训练和研究),约20亿美元用于面向用户的推理算力**。

值得注意的是,这50亿美元研发投入的绝大部分,竟然没有花在GPT-4.5、GPT-4o等爆款模型的最终训练上,而是贡献给了幕后的研究和各种实验性运行。
OpenAI真·实验狂魔!
不只热衷爆款模型,更爱“做实验”
首先来区分两个概念:
- 最终训练运行
- 实验性运行
那么,像GPT-4.5、GPT-4o这种级别的模型,光是最终训练一次,不得把研发的这50亿美元花掉一大半?
答案是nonono。
研究人员估算了OpenAI在2024年第二季度到2025年第一季度期间发布或宣布的重要模型(包括GPT-4.5、GPT-4o、o3和Sora Turbo)的训练成本。
计算目标是只估算最终训练运行的成本,刻意排除那些用于预热和探索的实验性运行。
他们采用了两种各有侧重的算账方法。
针对GPT-4.5,研究人员通过集群规模、训练持续时间、云成本三个指标,直接估算了GPT-4.5的最终运行成本。
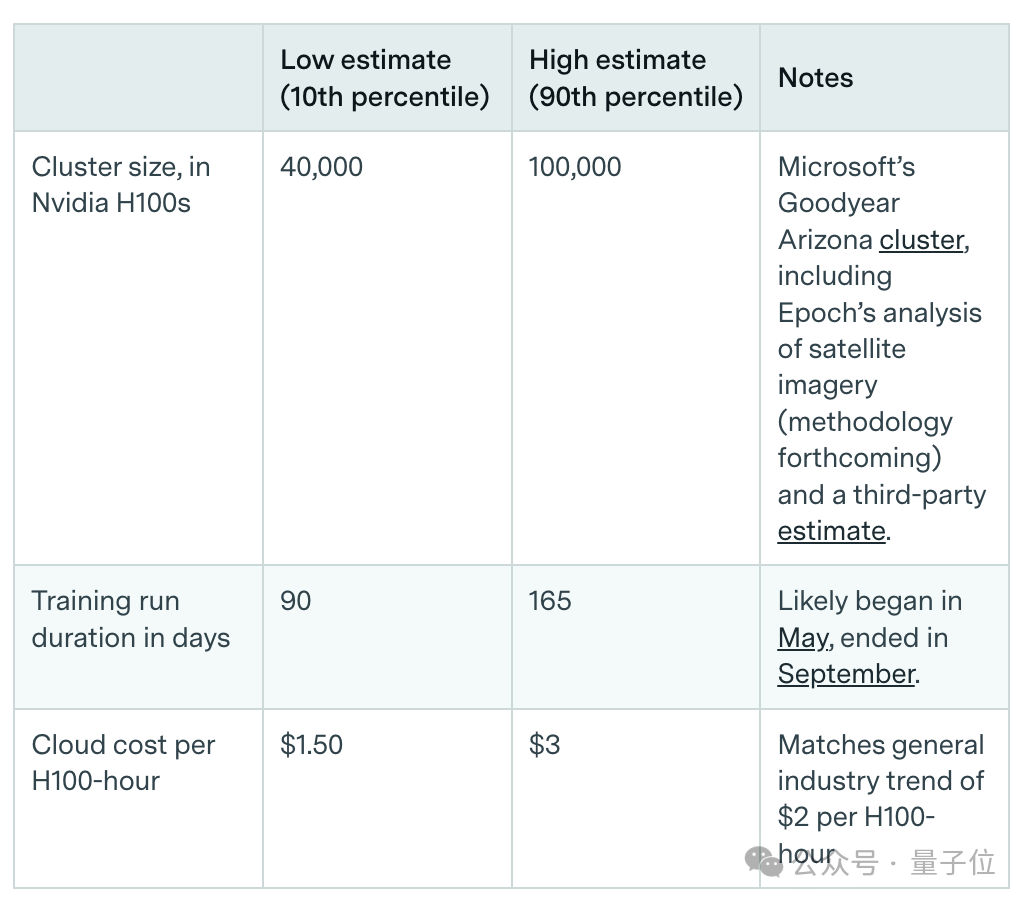
对于像GPT-4o和Sora Turbo这样的模型,研究人员采取了更为标准的间接估算方法。
首先估计这些模型在训练过程中进行了多少次浮点运算(FLOP),随后利用一套标准化的假设来计算出云算力费用。

团队通过比对分析,得出了关键结论:OpenAI 2024年的大部分研发算力,可能分配给了研究、实验性训练运行,或训练还没露面的模型。
这部分训练并不直接产出最终面向公众的产品版本,而是在探索模型的最佳参数、架构等。
也就是说,我们看到那些轰动一时的爆款模型,它们在发布时进行的那个最终的训练所消耗的成本,在50亿美元的总研发支出中,其实只占了很小一部分。
总之,据这项分析报告来看,在OpenAI眼中还是:实验>ALL。
这个结果也在一定程度上解释了为什么它被外界广泛报道2024年严重亏损。
毕竟当年营收37亿美元,却花了50亿美元研发支出的一大部分用于背后的“不露脸实验”。
所以为什么AI公司都在搞算力?
谁掌控算力,谁就掌控AI
目前为止,OpenAI已经达成了近万亿的算力交易,除了租用云服务,更大额的投资砸在了自建数据中心上。
钱都花在了算力上。为什么?
AI芯片公司Groq的创始人Jonathan Ross在最新的访谈中也提到了AI公司自建数据中心这一趋势。

他认为,如果供给OpenAI或者Anthropic这类公司的算力能够翻倍,那么他们的收入也会同步翻倍。
而就目前的形势来看,AI的发展对于算力的需求是没有上限的。
谁掌控算力,谁就掌控AI。
Jonathan Ross还打了个比方:就算你的模型比OpenAI的聪明十倍,只要OpenAI的算力多你十倍,OpenAI的实际效果就会更好。
于是,为了防止被算力卡脖子,OpenAI如今也开始自建数据中心。
在拥有大量算力资源之后,OpenAI又会“实验”出怎样的产品呢?
参考链接:https://epoch.ai/data-insights/openai-compute-spend
Jonathan Ross完整访谈:https://www.youtube.com/watch?v=VfIK5LFGnlk
文章来自于微信公众号 “量子位”,作者 “量子位”















