

智东西
作者 | ZeR0
编辑 | 漠影
智东西8月12日报道,今日,华为推出AI推理创新技术——推理记忆数据管理器UCM,通过多级缓存显著优化AI推理体验与性价比。

UCM是一款以KV Cache和记忆管理为中心的推理加速套件,提供全场景系列化推理加速方案,通过推理框架、算力、存储三层协同,优化Tokens在各业务环节中流转的效率,以实现AI推理的更优体验、更低成本。
其三大组件包括对接不同引擎与算力的推理引擎插件(Connector)、支持多级KV Cache管理及加速算法的功能库(Accelerator)、高性能KV Cache存取适配器(Adapter),并通过开放统一的南北向接口,可适配多类型推理引擎框架、算力及存储系统。
经大量测试验证,UCM可将首Token时延最高降低90%,系统吞吐最大提升22倍,实现10倍级上下文窗口扩展。
华为计划在今年9月正式开源UCM,届时将在魔擎社区首发,后续逐步贡献给业界主流推理引擎社区,希望通过开放开源的方式,让业界共享这一成果,共同推动AI推理生态的繁荣发展。

同时,华为与中国银联率先在金融典型场景开展UCM技术试点应用,并联合发布智慧金融AI推理加速方案应用成果。
会后,华为数据存储产品线副总裁、闪存领域总裁谢黎明,华为数据存储产品线AI存储首席架构师李国杰,与智东西等媒体进行深入交流。
李国杰强调,用AI处理更高级别的问题,信息量和数据输出会更大,UCM则能够大幅优化成本。今天发布的UCM,是华为第一次提供如此完整的全流程、全场景且可演进的系统性方案。从单点算力模组转向系统级优化,是一个大的变化和趋势。业界有很多开源方案有类似的方向,有的是做了其中某一层或某一些组件,但是并未看到可商用的端到端完整方案。
谢黎明谈道,开源UCM与业界思路是一致的,华为希望通过开放这些成果,为推理体验、生态、成本贡献一份力量,进一步促进框架、存储、GPU厂商共建和成熟化整套机制,真正解决AI行业化落地的效率和成本问题。
一、优化AI推理体验:10倍级上下文窗口扩展,TTFT最高降低90%,Token经济性提升2倍+
华为公司副总裁、数据存储产品线总裁周跃峰谈道,AI在金融行业大规模使用,推理效率与体验是关键。AI时代,模型训练、推理效率与体验的量纲都以Token数为表征,Token经济时代到来。
AI推理应用落地过程中面临三大挑战:
- 推不动(输入超出模型上下文窗口)
- 推得慢(美国大模型推理首Token时延=中国大模型的1/2)
- 推得贵(美国大模型推理吞吐率大约是中国大模型的10倍)
对此,华为推出UCM推理记忆数据管理器(Unified Cache Manager),通过多级缓存解决AI推理体验与成本问题。

整个AI推理系统中的记忆有三部分:高带宽内存HBM、DRAM都在智算服务器中,可以充分利用但过去没有利用起来的是下面的专业共享存储。

通过一系列算法,UCM把推理过程中有不同延时要求的数据放在不同的记忆体中,实时记忆数据即热放在HBM中,短期记忆数据放在DRAM,其他放在共享专业存储中,通过这样的按需流动来提升整个系统的效率。
UCM主要分为三部分:顶层是推理引擎插件(Connector),与业界多样引擎与多元算力灵活对接,会连接MindIE、SGLang等一些主流推理引擎框架;中间是对缓存记忆数据进行分级管理的一些创新加速算法,运行在智算服务器中;另一部分是与专业共享存储相结合的存取适配器,能提升专业存储的直通效率和降低时延,可以让三级存储更好协同。

通过大量测试,UCM能给推理系统的效率、体验、成本提升带来明显进步。
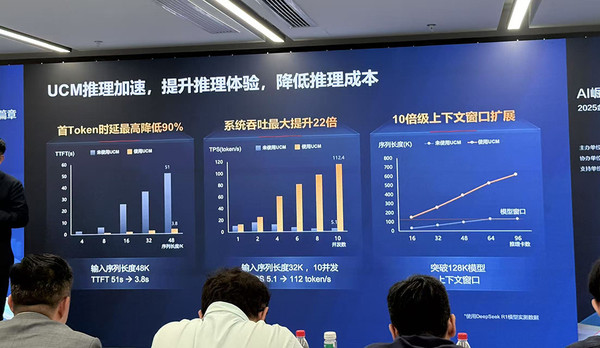
(1)更快的推理响应:依托UCM层级化自适应的全局前缀缓存技术,可实现任意物理位置、任意输入组合上的KV前缀缓存重用,在多轮对话、RAG知识检索等场景中直接调用KV缓存数据,避免重复计算,使首Token时延最大降低90%、Token经济性提升2倍+。

(2)更长的推理序列:通过动态KV逐层卸载、位置编码扩展、Prefill稀疏等组合技术,将超长序列Cache分层卸载至外置专业存储,通过算法创新突破模型和资源限制,实现10倍级推理上下文窗口扩展,满足长文本处理需求。

(3)更低的推理成本:具备智能分级缓存能力,可根据记忆热度在HBM、DRAM、SSD等存储介质中自动分级缓存,同时融合多种稀疏注意力算法,实现存算深度协同,使长序列场景下TPS(每秒处理token数)提升2-22倍,降低每Token推理成本。
UCM受打字输入法联想的启发,提供一套基于后缀检索的预测联想算法,将行业私域数据和用户习惯构建token级的后缀索引,突破自回归的联想限制,可以一次输出多词,并且存得越多推得越快,比传统MTP预测加速效果更好、更适用于企业场景。

二、面向开源设计,适配多类推理引擎框架、算力、存储系统
KV Cache与记忆数据管理是大语言模型推理中优化性能、降低计算成本的核心技术。但国内AI推理生态中尚未形成以其为核心的完整加速软件体系,相关技术布局存在短板。
随着迈入Agentic AI时代,模型规模化扩张、长序列需求激增以及推理任务并发量增长,AI推理的KV Cache容量增长已超出HBM的承载能力,需要构建“软件优化+硬件创新+存算协同”的架构。
UCM可根据数据冷热分级存储到不同介质中,使KV Cache容量从GB级增长至PB级,是一种更经济、更易用的推理加速方案。
其设计理念是通过开放统一的框架和接口,北向支持多样化的推理引擎连接,南向接入多样化的存储系统,中间在推理加速算法配置方面,开放并呼吁更多的开源和生态伙伴共建丰富的加速算法库。
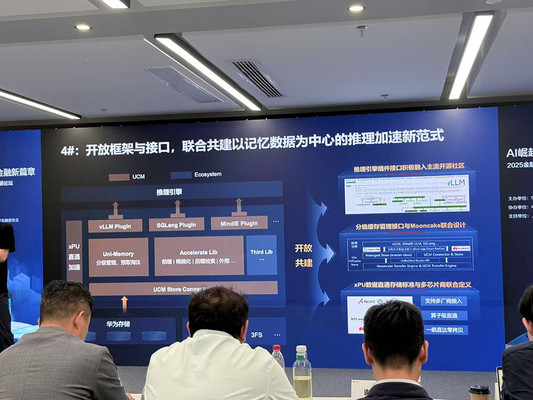
UCM面向开源设计,上层推理引擎插件接口积极融入主流的开源社区,中间层分级缓存管理接口与Mooncake联合设计,在端到端的XPU直通存储的存储标准和产业接口的定义上与多家芯片厂商进行联合定义。
华为希望联合产业界的力量,共建共创以记忆数据管理为中心的推理加速新范式。
AI技术迭代飞速,因此UCM着眼于未来设计,从KV Cache分层管理走向Agentic AI原生记忆管理与应用加速,除了今年发布的推理加速套件(下图黄色部分)之外,还会持续构建和发布面向Agent知识感知的多模检索加速能力以及未来Agent原生记忆的管理和加速能力。

据李国杰透露,UCM大概从去年6-7月份开始孵化,至今差不多一年,仅是算法方面就有百人级团队投入,未来会面向Agentic AI做更深演进,可能会继续增加投入。
谈到UCM与其他分级缓存管理的差别,李国杰总结了三点:
首先是纳入专业存储。很多分级缓存管理是管理一些裸金属资源,效率不太能满足商用客户要求。纳入专业存储后,华为做了大量软硬系统和卸载的事情,比如直通加速、KV Cache生命周期管理等。
第二,业界现有方案在算法加速库方面几乎只有传统的Prefix Cache一种技术,并没有像UCM这样商用全流程稀疏算法、后缀检索算法及其他算法。相较业界,华为贡献了一些更加丰富、可靠的或加速效果更好的算法,这个算法库还在持续增加中。
第三,推理场景非常丰富,请求输入输出变化多端,各场景下没有一套框架、一套加速机制、一套算法是可以普适的,所以需要一套完整、丝滑、能在各场景、各种长短序列、各种请求下做自动切换和自动适应的方案,只有像UCM这样真正跟客户场景贴身联创和迭代的技术才有这样的能力。
三、技术价值已在智慧金融场景得到验证
在与中国银联的联合创新技术试点中,UCM的技术价值得到验证。
在中国银联“客户之声”业务场景下,借助UCM技术及工程化手段,大模型推理速度提升125倍,仅需10秒即可精准识别客户高频问题,促进服务质量提升。

未来,中国银联计划依托国家人工智能应用中试基地,联合华为等生态伙伴共建“AI+金融”示范应用,推动技术成果从“实验室验证”走向“规模化应用”。
会上,中国信通院人工智能研究所平台与工程化部主任曹峰分享了大模型推理优化的4个主要趋势:
(1)大模型落地重心从训练转向推理,应用从ToC到ToB加速成熟;
(2)推理目标从单点优化和功能完备转向“成本-性能-效果”三目标协同优化;
(3)系统级架构优化将成主流,头部厂商2025年陆续推出推理系统级优化方案,未来结合“模型-场景-架构”的推理架构设计是技术、产业的发展重点;
(4)KV Cache是架构优化焦点,以KV Cache为核心的推理方案迭出,其背后依赖的高性能存储、先进调度策略的重要性将愈发显现。
结语:应对AI推理多重性能挑战,UCM能有效缓解资源瓶颈
推理已成为AI下一阶段的发展重心,直接关联用户满意度、商业可行性等,重要性愈发凸显。
AI推理从生成式AI时代的简单推理任务,逐渐向Agentic AI时代的复杂长程推理任务发展,带来了对算力计算量、内存访问效率、超长上下文处理、Multi-agent状态共享等方面的性能挑战。
UCM可通过复用已计算结果、上下文窗口扩展、长记忆保持与共享等技术,减少重复计算与低效内存访问,有效缓解复杂任务产生的资源瓶颈和性能挑战。
通过融合多类型缓存加速算法工具,UCM能够更大程度释放KV Cache与推理框架的性能潜力,实现推理效率的显著提升,并通过开源开放进一步加速探索优化商用AI推理方案的高效路径。
















