
30.5K星!这个AI工具设计宝藏,凭啥让开发者“疯传”?
GitHub上一款名为“system-prompts-and-models-of-ai-tools”的开源项目引发广泛关注,累计获得30.5K星,成为AI开发者与研究者的热门资源。据AIbase了解,该项目汇集了9款主流AI工具的系统提示词与模型配置,包含6500+行内容,覆盖v0、Cursor、Manus、Same.dev、Lovable、Devin、Replit Agent、Windsurf

全球首部AI生成电影《海上女王郑一嫂》上映 时长70分钟
近日,由新加坡影视制作公司FizzDragon出品的70分钟华语AIGC(人工智能生成内容)电影《海上女王郑一嫂》正式在新加坡院线上映,成为全球首部进入商业院线公映的AI技术长片。该片以18世纪中国传奇女海盗郑一嫂为原型,其人物形象曾启发《加勒比海盗》系列中“清夫人”一角的创作。与传统影视制作相比,AI技术在本片中的应用显著降低了创作门槛。FizzDragon团队表示,AI工具无需考虑天气、演员档
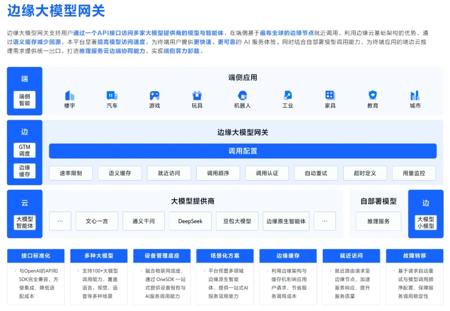
豆包 1.5 · 深度思考模型上线边缘大模型网关 可免费领百万Tokens
4月25日,字节跳动旗下的火山引擎宣布,其最新发布的豆包1.5·深度思考模型已全面上线边缘大模型网关,并为用户提供高达500万tokens的免费使用额度,这一举措在AI领域引起了广泛关注。豆包1.5·深度思考模型是火山引擎推出的高性能AI模型,它在数学、代码和科学等专业领域的推理任务中表现卓越,已达到或接近全球顶尖水平。该模型不仅在推理任务中表现出色,在创意写作等非推理任务中也展现出强大的泛化能力

GPT-image-1 – OpenAI 推出的最新图像生成模型
GPT-image-1是什么GPT-image-1是OpenAI推出的原生多模态图像生成模型,基于API向开发者开放使用。模型根据文本提示和图像生成高质量、专业级的图像,支持多种风格和自定义功能,如图像质量、尺寸、格式、压缩程度等。模型广泛应用在创意设计、电商、教育、营销等领域,例如将草图转化为图形、生成产品展示图、创建品牌视觉资产等。目前已经被包括 Adobe、Figma 在内等主流创意平台
Flex.2-preview – Ostris 推出的文本到图像扩散模型
Flex.2-preview是什么Flex.2-preview 是Ostris开源的 80 亿参数文本到图像扩散模型,支持通用控制输入(如线条、姿态、深度)和内置修复功能。模型基于一个模型满足多种创意需求,支持长文本输入(512 个 token),支持基于 ComfyUI 或 Diffusers 库轻松使用。Flex.2-preview目前处于早期预览阶段,展现出强大的灵活性和潜力,适合创意生
LongPort MCP – 长桥集团推出的证券业首个券商MCP
LongPort MCP是什么LongPort MCP(Model Context Protocol)是长桥集团推出的证券行业首个券商MCP。基于 LongPort MCP,AI 能快速调用证券行情数据、执行股票交易、管理资产组合等核心金融服务。LongPort MCP支持自然语言交互,显著降低专业投资者使用券商 API 的门槛,极大提升效率,实现 AI 与证券核心服务的无缝连接。Long

Suna – 全球首款开源的通用 AI Agent
Suna是什么Suna 是全球首款开源的通用 AI Agent,支持高效解决现实场景中的各类任务。基于自然流畅的对话交互,Suna 支持智能辅助研究分析、数据处理及日常事务,化身专属数字伙伴。Suna 具备强大的功能,包括浏览器自动化、文件管理、网络爬虫、命令行执行、网站部署及与多种API的集成。Suna 结合直观的界面和强大的工具集,解决复杂问题并自动化工作流程。支持用户自托管Suna,用简
MAGI-1 – Sand AI 开源的首个自回归视频生成模型
MAGI-1是什么MAGI-1 是 Sand AI 开源的全球首个自回归视频生成大模型,采用自回归架构,通过逐块预测视频序列生成流畅自然的视频,支持无限扩展和一镜到底的长视频生成。模型原生分辨率可达 1440×2568,生成的视频动作流畅且细节逼真,具备可控生成能力,可通过分块提示实现平滑场景转换和细粒度控制。MAGI-1的主要功能高效视频生成:MAGI-1 能在短时间内生成高质量视频
Yuxi-Know – 基于大模型 RAG 知识库的 AI 知识图谱问答平台
Yuxi-Know是什么Yuxi-Know(语析)是基于大模型RAG知识库与知识图谱技术构建的智能问答平台。Yuxi-Know支持多种知识库文件格式(如PDF、TXT、MD、Docx),支持将文件内容转换为向量存储,便于快速检索。Yuxi-Know集成基于Neo4j的知识图谱问答能力,能处理复杂的知识关系查询。平台支持多模型适配,包括OpenAI、国内主流大模型及本地部署的vllm、ollam
SimpleAR – 复旦大学联合字节 Seed 团队推出的图像生成模型
SimpleAR是什么SimpleAR 是复旦大学视觉与学习实验室和字节 Seed 团队联合推出的纯自回归图像生成模型。采用简洁的自回归架构,通过优化训练和推理过程,实现了高质量的图像生成。SimpleAR 仅用 5 亿参数即可生成 1024×1024 分辨率的图像,在 GenEval 等基准测试中取得了优异成绩。训练采用“预训练 – 有监督微调 – 强化学习”的三阶段方法,显著提升了文本跟随
Aether – 上海 AI Lab 开源的生成式世界模型
Aether是什么Aether 是上海AI Lab开源的生成式世界模型,完全基于合成数据训练。Aether 首次将三维时空建模与生成式建模深度融合,具备 4D 动态重建、动作条件视频预测和目标导向视觉规划三大核心能力。Aether 能感知环境、理解物体位置和运动关系,做出智能决策。Aether 在真实世界中展现出强大的零样本泛化能力,使用虚拟数据训练完成高效完成复杂任务,为具身智能系统提供强大
ChatTS-14B – 字节开源的时间序列理解和推理大模型
ChatTS-14B是什么ChatTS-14B 是字节跳动研究团队开源的专注于时间序列理解和推理的大型语言模型,参数量达 140 亿。基于 Qwen2.5-14B-Instruct 微调而成,通过合成数据对齐技术显著提升了在时间序列任务中的表现。模型支持自然语言交互,用户可以通过简单的指令完成对时间序列数据的分析、预测和推理,例如金融市场趋势分析、天气预测或工业流程优化等任务。ChatTS-1
Infinite Mobility – 上海 AI Lab 推出的可交互物体生成模型
Infinite Mobility是什么Infinite Mobility 是上海AI Lab推出的可交互物体生成模型,基于程序化生成技术,高效生成高质量的可交互物体数据资产。Infinite Mobility支持22类常见可交互物体的生成,单个物体生成仅需约1秒,生成数量无上限。相比传统数据集(如PartNet-Mobility),Infinite Mobility生成的物体结构复杂度更高、

告别 AI 数据盲区!Relyance AI 新平台实现端到端流向可视化
数据治理平台提供商 Relyance AI 在去年10月获得3210万美元 B 轮融资后,推出了全新的 Data Journeys 平台,旨在解决企业采用 AI 时面临的关键挑战:准确了解数据在复杂系统中的流转。该平台能够追踪数据在应用程序、云服务和第三方系统中的使用方式和原因,填补了传统数据沿袭方法的空白。Relyance AI 首席执行官兼联合创始人 Abhi Sharma 强调,Data J

Nvidia 将首次在美国制造 AI 超级计算机,打造自主供应链
Nvidia 近期宣布,将在美国本土首次制造其 AI 超级计算机。这一举措标志着该公司与一系列制造合作伙伴共同合作,旨在在美国工厂内建造、包装、测试和组装下一代 Blackwell 系统。目前,Blackwell 芯片的生产已经在位于亚利桑那州的 TSMC 半导体制造厂展开,而超级计算机的组装则将在德克萨斯州进行,由富士康在休斯顿和纬创在达拉斯进行扩展。此外,负责包装和测试的安靠和矽品,也在亚利桑

Gartner报告:2027年,任务特定AI使用频率将是通用AI的三倍
根据最新发布的 Gartner 报告,到2027年,企业将使用任务特定的人工智能模型的频率将是通用大语言模型的三倍。报告指出,尽管通用大语言模型在语言处理方面具备强大的能力,但在需要深入理解特定业务领域的任务时,它们的响应准确性会下降。因此,越来越多的企业开始关注能够满足特定需求的定制化模型。图源备注:图片由AI生成,图片授权服务商MidjourneyGartner 副总裁兼分析师 Sumit A