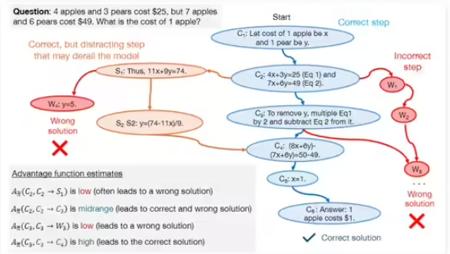
谷歌新研究:合成数据助力大模型,数学推理能力提升八倍 近期,谷歌、卡内基梅隆大学与 MultiOn 的研究团队联合发布了一项关于合成数据在大模型训练中应用的新研究。根据 AI 发展科研机构 Epoch AI 的报告,目前人类公开的高质量文本训练数据大约有300万亿 tokens,但随着大型模型如 ChatGPT 的快速发展,对训练数据的需求正以指数级增长,预计在2026年前这些数据将被消耗殆尽,因此合成数据逐渐成为重要的替代方案。研究人员探索了合成数 AI热点 2周前 0 点赞 0 评论 113 浏览
谷歌研究揭示:合成数据提升大模型逻辑推理能力八倍 在最新的研究中,谷歌与卡内基梅隆大学及 MultiOn 团队联手,探讨了合成数据对大型模型的训练效果。他们发现,合成数据能够显著提升大模型在逻辑推理方面的表现,尤其是在数学问题的解决能力上,提升幅度达到了惊人的八倍。这一发现对于当前训练数据日益匮乏的现状具有重要的意义。目前,全球可用的高质量文本训练数据约为300万亿条,但随着像 ChatGPT 这样的模型日益普及,对训练数据的需求急剧增加,预计到 AI热点 2周前 0 点赞 0 评论 193 浏览