

机器之心报道
机器之心编辑部
引入「交错生成」功能,增强模型在世界知识和创意解释方面的能力。
香蕉也能变礼服?Google 真的做到了!
在最新一期谷歌开发者节目里,Google DeepMind 团队首次全面展示了 Gemini 2.5 Flash Image —— 一款拥有原生图像生成与编辑能力的最新模型。
它不仅能快速生成高质量图像,还能在多轮对话中保持场景一致,带来了前所未有的互动体验,堪称 SOTA 级图像生成革命。
背后的研发和产品团队,也首次亮相。
起底背后团队
Logan Kilpatrick

Logan Kilpatrick 是 Google DeepMind 的高级产品经理,负责领导 Google AI Studio 和 Gemini API 的产品开发工作。
他在 AI 开发者社区中享有盛誉,曾在 OpenAI 担任开发者关系负责人,广为人知的昵称是 「LoganGPT」 。在加入 Google 之前,他曾在 Apple 担任机器学习工程师,并在 NASA 担任开源政策顾问 。
在 Google,Kilpatrick 领导了 Gemini 2.0 Flash 的本地图像生成功能的推出,使开发者能够通过自然语言提示生成和编辑图像。这一功能的亮点包括多轮对话式图像编辑、图像和文本的交替生成,以及基于世界知识的图像生成 。
Kilpatrick 还定期在 X 上分享产品更新和开发者资源,成为 Google AI 的非正式代言人 。
他毕业于哈佛大学和牛津大学,早期在 NASA 开发月球车软件,并在 Apple 训练机器学习模型 。他对 Julia 编程语言持积极态度,并曾在 2024 年表示,直接迈向人工超智能(ASI)而不关注中间阶段的做法「越来越可能」。

Kaushik Shivakumar

Kaushik Shivakumar 是 Google DeepMind 的研究工程师,专注于机器人技术、人工智能和多模态学习的研究与应用 。
他在加利福尼亚大学伯克利分校获得了计算机科学学士学位,并在该校的 AUTOLab 实验室攻读硕士学位,师从 Ken Goldberg 教授 。在研究生阶段,他主要从事与可变形物体操作、语言模型和强化学习相关的机器人研究。
在加入 DeepMind 之前,Kaushik 曾在 Google Brain 团队担任软件工程实习生,研究深度神经网络的不确定性估计方法 。他还在 UC Berkeley 的 RISE Lab 和 Snorkel AI 等机构担任研究员和实习生,参与了多项与机器人、机器学习和弱监督学习相关的项目 。
在 DeepMind,Kaushik 参与了多个重要项目,包括 Gemini 2.5 模型的开发,该模型在推理能力、多模态理解和长上下文处理方面取得了显著进展 。此外,他还在机器人操作、物体追踪和语义搜索等领域发表了多篇研究论文 。
Robert Riachi

Robert Riachi 是 Google DeepMind 的研究工程师,专注于多模态 AI 模型的开发与应用,尤其在图像生成和编辑领域具有显著贡献。
他在大学期间主修计算机科学和统计学,毕业于加拿大滑铁卢大学。

在 DeepMind,Riachi 参与了多个重要项目,包括 Gemini 2.0 和 Gemini 2.5 系列模型的研发工作,致力于将图像生成能力与对话式 AI 相结合,使用户能够通过自然语言提示进行精细的图像编辑。
在加入 DeepMind 之前,Riachi 曾在 Splunk、Bloomberg、SAP 和 Deloitte 等公司担任软件工程师和机器学习工程师。
Nicole Brichtova

Nicole Brichtova 本科和研究生分别毕业于美国乔治敦大学和美国杜克大学富卡商学院,目前担任 Google DeepMind 的视觉生成产品负责人,专注于构建生成模型,推动 Gemini 应用、Google Ads 和 Google Cloud 等产品的发展。
在加入 DeepMind 之前,Nicole 曾在 Google 的消费产品团队担任产品和市场战略工作,参与了多个项目的规划和推广。此外,她还在德勤咨询公司担任顾问,为财富 500 强的科技公司提供创新和增长方面的建议。

Nicole 特别关注生成式人工智能如何支持创意、设计以及与技术互动的新方式。她在多个公开场合分享了 DeepMind 在视觉生成领域的最新进展,强调模型在理解复杂指令和生成高质量图像方面的能力。
Mostafa Dehghani

Mostafa Dehghani 是 Google DeepMind 的研究科学家,主要从事机器学习,特别是深度学习方面的工作。他的研究兴趣包括自监督学习、生成模型、大模型训练和序列建模。
在加入谷歌前,他在阿姆斯特丹大学攻读博士学位,博士研究聚焦于改进在不完备监督下的学习过程。他探索了将归纳偏置引入算法、融入先验知识以及使用数据本身进行元学习的思想,旨在帮助学习算法更好地从噪声或有限数据中学习。
他于 2020 年加入 Google DeepMind,参与了多个重要项目,包括开发多模态视觉语言模型 PaLI-X、构建 220 亿参数的 Vision Transformer(ViT22B)以及提出 DSI++(Differentiable Search Indices),这是一种用于文档增量更新的检索增强学习方法 。
Nano Banana 有哪些技术亮点?
在节目一开始,研究人员就演展示了这款 P 图神器的几个亮点。
图像编辑与场景一致性:
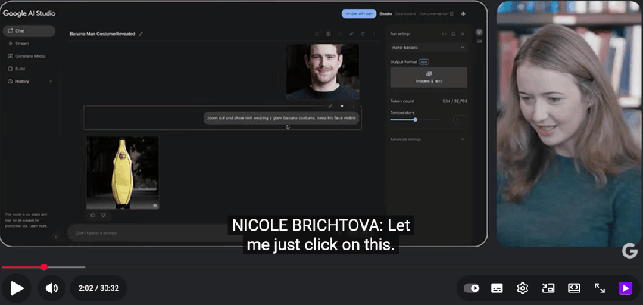
让 AI 给 Logan 「穿上一件巨大的香蕉服」。生成只花了十几秒,结果既保留了 Logan 的脸部特征,还加上了芝加哥街头的背景。
创意解读与模糊指令处理:
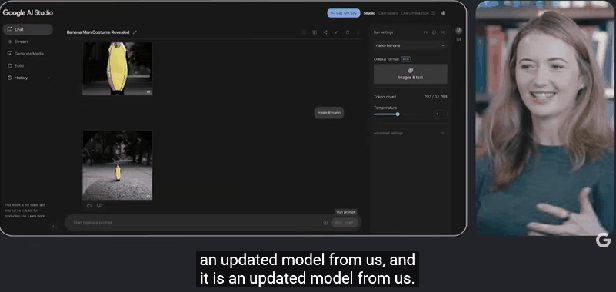
当提示「让它变成纳米(Nano)」时,模型居然生成了 Logan 的「迷你 Q 版」形象,依旧保持了香蕉服的设定。
模型能够通过自然语言指令进行多轮互动,且在多次编辑中保持场景一致性,无需输入冗长提示词。
过去图像生成 AI 最大的槽点是「写字像外星文」。而这次,Gemini 2.5 Flash Image 已经能在图中正确生成简短的文字,比如「Gemini Nano」。

团队甚至把文本渲染能力当作模型评估的新指标,因为它能反映模型生成图像「结构」的能力,并作为衡量整体图像质量的信号,有助于指导模型改进。
他们通过追踪此指标,避免了模型退步。虽然目前仍有文本渲染方面的不足,但团队正努力改进。
而且,Gemini 2.5 Flash Image 不只是「画图机器」,它的核心魅力还在于「看懂图片」。
团队介绍,这款模型在原生图像生成与多模态理解方面实现了紧密结合:图像理解为生成提供信息,生成又反过来强化理解,两者相辅相成。
通过图像、视频甚至音频,Gemini 能从世界中学习额外知识,从而提升文本理解与生成能力 —— 视觉信号成为理解世界的捷径。
在操作体验上,模型引入了「交错生成机制(interleaved generation)」。
面对复杂、多点修改的任务,它会将一次性指令拆解成多轮操作,逐步生成与编辑图像,实现「像素级别的完美编辑」。用户只需用自然语言下达指令,即便提示模糊,Gemini 也能创意解读,并保持场景一致性。
无论是角色动作、服装,还是背景环境,修改与生成都能在多轮中保持连贯。
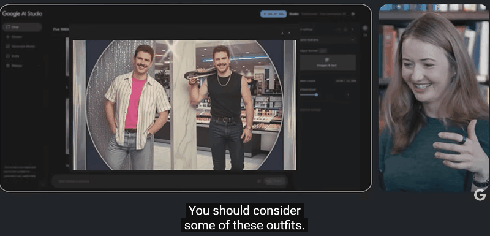
用 1980 年代美国魅力购物中心风格生成多张图片,每张图都保持风格一致且具上下文关联。模型会利用多模态上下文,参考先前的图像来生成修改。
因此,除了娱乐搞怪,Gemini 2.5 Flash Image 在实际应用场景中也大有用武之地。家居设计中,用户可以快速查看多种方案。如房间不同窗帘效果可视化,模型能精准修改而不破坏整体环境。
人物 OOTD,无论是换衣服、变角度,还是生成 80 年代复古风形象,人物的面部和身份一致性都能保持稳定。生成一张图只需十几秒,失败了也能迅速重试,极大提升了创作效率。
那么,在实际应用中,开发者应该如何在 Imagen 和 Gemini 之间做选择?
Nicole Brichtova 表示,Gemini 的终极目标,是整合所有模态,向 AGI(通用人工智能)方向迈进。这意味着 Gemini 不只是一个图像生成工具,而是一个能够利用「知识转移」,在跨模态的复杂任务中发挥作用的系统。
相比之下,Imagen 专注文本到图像任务,在 Vertex 平台中提供多种变体,针对特定需求进行了优化,例如单张图像的高质量生成、快速输出、以及成本效益等方面。
简而言之,如果任务目标明确、追求速度和性价比,Imagen 仍然是理想选择。
在复杂多模态工作流中,Gemini 的优势则更加突出。它适合复杂多模态任务,支持生成 + 编辑、多轮创意迭代,能理解模糊指令。
Gemini 能利用世界知识理解模糊提示,适合创意场景。Nicole 还补充道,Gemini 可以直接将参考图像作为风格输入,比 Imagen 的操作更方便。这让它在处理「以某公司风格设计广告牌」之类的任务时,更加自然和高效。
最后,团队成员分享了对未来模型能力的展望。
一个是智能提升。Mostafa Dehghani 期待模型能展现出「智能」,即使不完全遵循指令,也能生成「比我实际描述的更好」的结果,让使用者感受到与一个更聪明的系统互动。
另一个是事实性与功能性。Nicole Brichtova 对「事实性」感到非常兴奋,希望未来的模型能够生成既美观又具功能性且准确无误的图表或信息图,甚至能自动制作工作简报,她认为这只是这些模型能做到的一小部分。
参考链接:
https://www.youtube.com/watch?v=H6ZXujE1qBA
https://www.linkedin.com/in/logankilpatrick/details/experience/
https://www.linkedin.com/in/kaushik-shivakumar/
https://www.linkedin.com/in/robertjrriachi/
https://www.linkedin.com/in/nicolebrichtova/
https://www.linkedin.com/in/dehghani-mostafa/














