

从技术原理到实际使用,大模型的“幻觉”问题始终绕不开:它不仅影响输出准确性,更关系到业务决策与风险控制。本文将深入剖析AI幻觉的形成原因,探讨应对路径与工程优化思路,并从使用者视角出发,提出如何“和幻觉共处”的实践建议。

写这一篇的缘由一是因为我也在摸索如何降低 AI 幻觉提升 AI 工具使用效率,二是因为前两周在MIT学习时老师讲的一节课,刚好也解释了这个问题,所以一并做个总结,分享给大家。
近几年,大型语言模型(LLM)如 ChatGPT、Claude、Gemini 等快速走进公众视野。它们能生成结构完整、逻辑清晰的长文本,甚至可以进行代码编写、法律文书撰写、医学咨询等高难度任务。然而,我们也越来越频繁地听到一个术语:AI幻觉。
简单说,它指的是模型“说得像真的,但其实是错的”。
本文将尝试解释三个问题:
- 什么是AI幻觉?为什么语言模型会产生幻觉?
- GPT-4等新一代模型是否真的减少了幻觉?
- 如何尽可能减少幻觉带来的误导?
一、语言模型不是在“理解”,而是在“预测”
GPT 的全称是Generative Pre-trained Transformer,其核心任务是:给定一段输入,预测下一个最可能出现的词(token)。这种机制的本质是统计语言模式,而不是基于事实的知识回忆或理解。
举个例子,输入“乔布斯和马斯克在球场上”,模型会续写出“展开了一场激烈的篮球比赛”,尽管这从未真实发生。这不是模型有意捏造,而是它识别出“人名 + 球场”常出现在比赛语境中,于是生成符合语言习惯的句子。
这类“幻觉”即来自其构建方式:模型的目标不是还原事实,而是生成“在训练语料中最常见或最自然”的文本。也就是说,它输出的是“语言上的合理”,而非“世界中的真实”。
这也是幻觉的来源:在不知道答案时,模型仍然会“给出一个听起来合理的回答”。
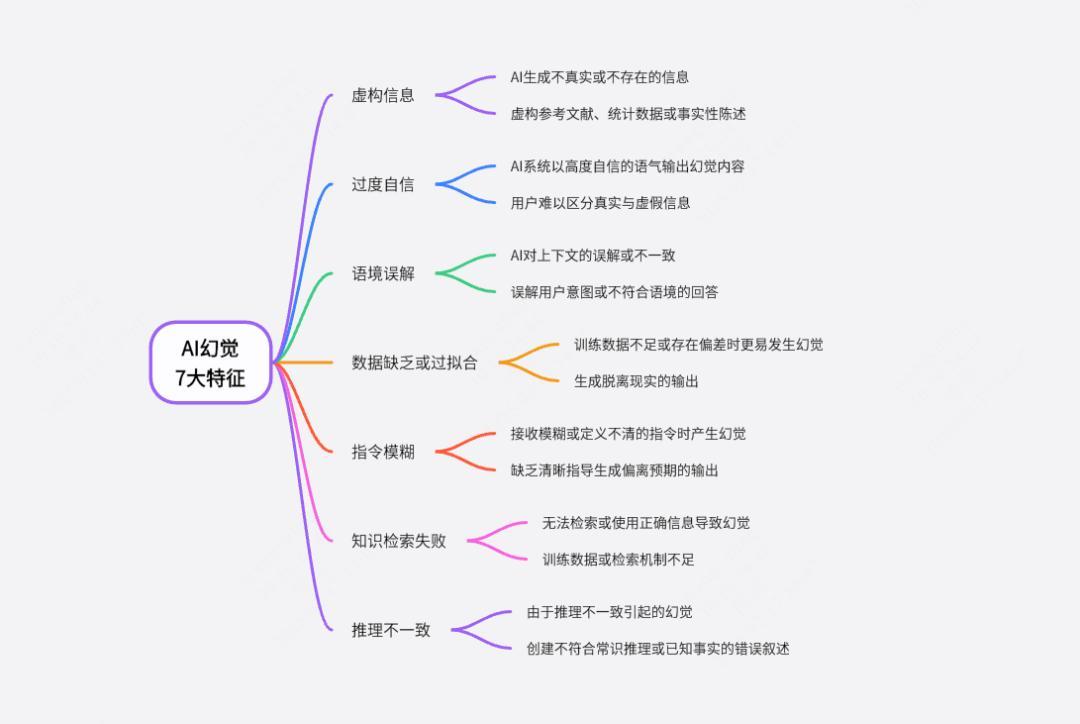
二、幻觉的技术根源:训练机制、知识覆盖与任务设定
- 训练机制决定幻觉倾向:GPT采用的是无监督学习方法,即在大规模互联网文本上训练模型,其唯一目标是最大化下一个词出现的概率,而不是核查事实。这种机制天然就倾向于生成“似是而非”的内容。
- 语料中的事实不等于知识库:模型并不保存某种结构化知识图谱或数据库,它记住的是“什么词经常和什么词一起出现”,而不是“谁获得了2022年冬奥会金牌”这种事实信息。
在 MIT 的课上,教授举了一个例子:
“问 GPT 3.5:‘谁赢得了 2022 年冬奥会冰壶金牌?’——模型回答错误,称韩国女队获胜,而实际上是英国队。”
原因在于:GPT 3.5 的训练数据截止于 2021 年,不包含 2022 年的事实。因此只能“模仿出一个合理答案”,而不是“查找真实答案”。
- Prompt的诱导效应:用户的提问方式对模型结果有很强导向性。例如:“请写一篇关于爱因斯坦和马斯克辩论环保问题的稿件”,这个语句默认了事件的真实性,模型不会去验证事实,只会按“剧本”生成。
- 缺乏世界建模能力:GPT不理解时间、空间或因果关系。即便在逻辑上存在冲突,模型也不会主动识别,而是依赖文本连贯性生成语言。
三、GPT-4 相较 GPT-3.5 幻觉减少了吗?为什么?
整体来看,GPT-4 的幻觉率相较 GPT-3.5 有所下降,背后有以下几点改进:
(来源:OpenAI. :GPT-4 Technical Report. 2023)
- 更大的训练数据集:覆盖更多领域与长尾知识,减少“知识空白”导致的猜测;
- 更强的上下文理解能力:GPT-4 的 context window 扩大至 32k token,使其能记住更多上下文,减少断章取义和语义漂移;
- 引入人类反馈强化学习(RLHF):在模型微调阶段,使用人类标注反馈强化“承认不知道”优于“胡编乱造”的行为;
- 微调策略优化:特别针对幻觉问题,引入了对输出置信度的判断机制,使模型在低置信度时更倾向于给出模糊或保守的回答。
不过,即使如此,幻觉依然存在,尤其在以下场景更容易触发:
- 冷门专业领域(如罕见病、边缘法律问题);
- 问题提示模糊或含有虚构前提;
- 用户询问的是未来或最新事件;
四、如何最大限度减少 AI 幻觉?用户与系统端的协同策略
1. 用户端优化
“如果你不知道,就说不知道”
“基于我上传的文档回答”
- 使用结构化Prompt限制模型的自由发挥范围,如“请分三点说明”“用表格列出”;
- 避免诱导性或假设前提问题,尤其是在高风险领域;
2. 系统端优化
- 检索增强生成(RAG):给模型增加一个“查资料”模块,让它回答前先查外部数据库或网页;
- 插件与联网设计:如WolframAlpha(做计算)和BingSearch插件(查新闻)已集成至GPT产品中,提升事实查验能力;
- 多阶段生成机制:将“任务理解、信息检索、生成内容”分阶段执行,避免一次性完成的单步误导;
- 专业模型精调:在医学、金融、法律等专业领域,训练专门子模型来提供更安全、准确的答案。
最后:语言的流畅,不等于事实的可靠
幻觉是当前大型语言模型的结构性副产物,它既不是“错误”,也不是“欺骗”,而是模型生成机制与真实世界之间的落差,是语言模型当前能力边界的自然结果。
理解这一点,是我们理性使用 GPT 和类 AI 工具的基础,也提醒我们:生成式语言的“像真度”,并不等于它的真实性。
未来,随着外部工具接入、Agent 机制完善、责任机制明确,幻觉问题会被进一步缓解。但在那之前,任何看起来“说得头头是道”的 AI 回答,我们都应保留验证的习惯。
作者:张艾拉 公众号:Fun AI Everyday
本文由 @张艾拉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Pixabay,基于CC0协议













