
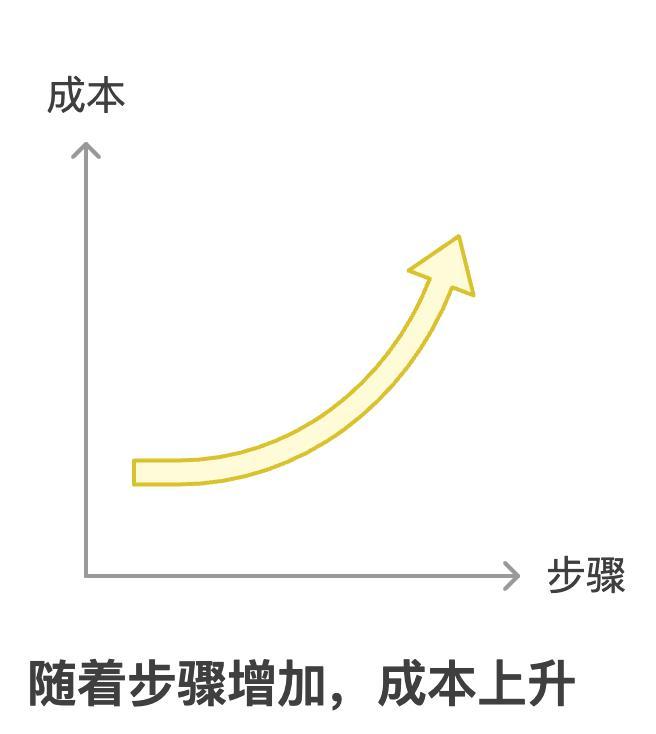
价格会周期性下调,但账单主要被“每次任务要走几步”决定。把平均推理步数少掉 1 步,往往立竿见影;在不少业务里,其效应大于同型号单价再降 10%。
步数,才是成本的主变量
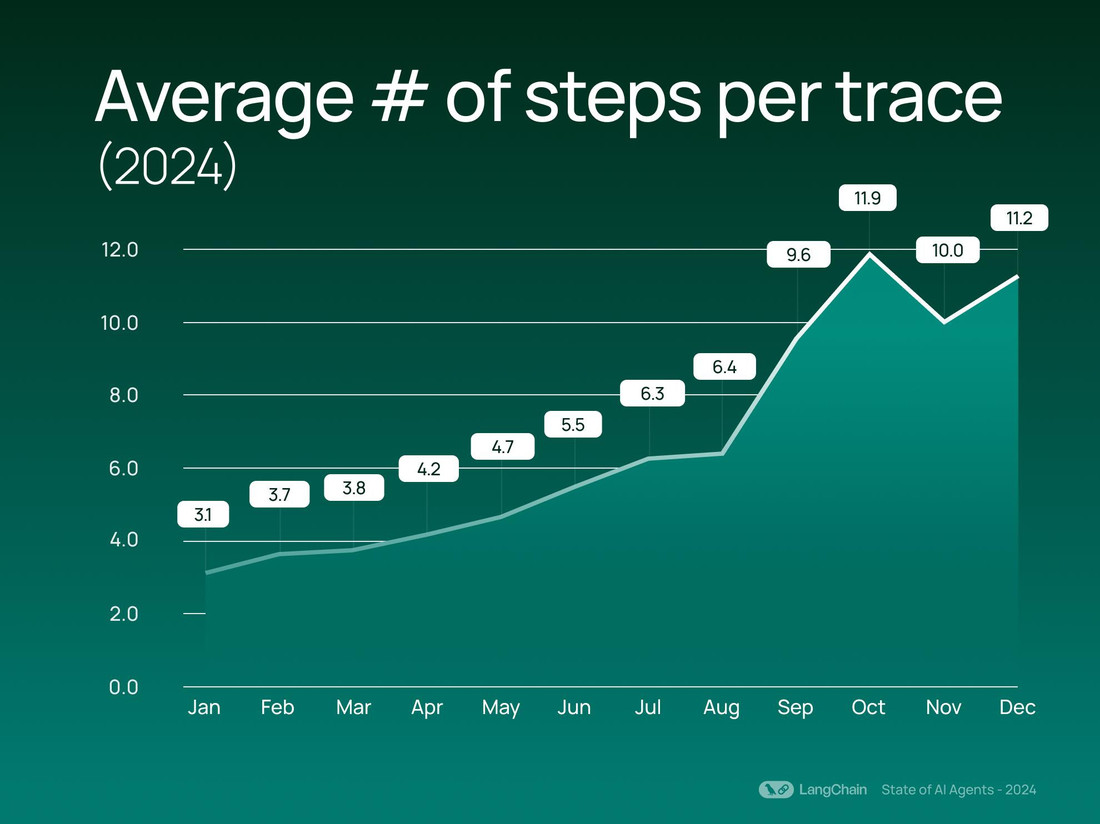
一套能跑通的 AI 工作流,真实样貌越来越像“多级流水线”:检索、重排、压缩、调用、复查,再决定要不要加做一步。步数一多,哪怕单价便宜,账单也会被放大。这不是直觉,是近年的产品数据在提醒我们:2024 年围绕 agent 的实践里,平均每条 trace 的步骤数从 2.8 涨到 7.7;工具调用的占比也显著抬升。说明大家都在用“多步”换效果,但也在用“多步”放大成本弹性。所以先盯步数,而不是盯牌价。
具体到每一步,常见的“隐形重复”来自于上下文复用不充分。2024–2025 年,厂商在这件事上给出直接筹码:比如 Anthropic 推出提示缓存,把“已缓存的输入”按 ≤原价 1/10计费,读写分开,提示模板和文档可跨轮复用;不少企业把系统提示与常用知识块缓存后,每轮对话的固定成本立刻下降。这类“少一复制步”的收益,往往超过单价再小幅下调。
更要命的是,步数会相互连锁。你在上游多取 2 篇文档,下游就多压缩一次、重排一次;一旦采用“多轮自我反思”,思考 tokens 又会滚上来。与其死抠型号差价,不如给“是否需要下一步”先装一只闸门。这只闸门,才是账单的主旋钮。——把贵脑力只留给难题,能少跑一轮校验就少跑一轮。
少检索一次,真的比降价 10% 更有用吗?
很多 RAG 实战里,top-k设得偏大,是因为大家不愿意错过关键信息。但当 k 从 8 减到 4、6,检索质量不会线性崩,延迟和输入 token却能明显回落;再搭配“先用 BM25 过滤、再向量召回”,你会发现少一次检索重排,比“盯住模型降价 10%”更灵。实务建议是先把 k 缩到 4–6 做盲测,统计质量回落是否可接受;大多数 FAQ、客服、内部知识库场景,能接受。
还有一类“检索步”躲在内置 Web 搜索里。2025 年 OpenAI 把 Web Search 做成内置工具,4o/4.1 系列按$25/1K 次计,且“搜索内容 tokens”打包计价;但 o3 / o4-mini 则会按模型费率继续计这批“搜索内容 tokens”。如果任务确实要搜,一是减少一次搜索调用直接省一笔,二是换到包含型定价的型号避免双边计费。对“每会话搜 1–2 次”的常见用法,少 1 次的单位降幅,往往就超过“型号再降 10%”。
一个开发者给出过更直观的账单教训:在 LangChain 的“refine 链”默认策略下,同一个问答被拆成多次 LLM 调用,总 tokens 直接翻倍,两次实验账单相差2.7×。这里并没有换更贵的模型,只是多跑了几步。
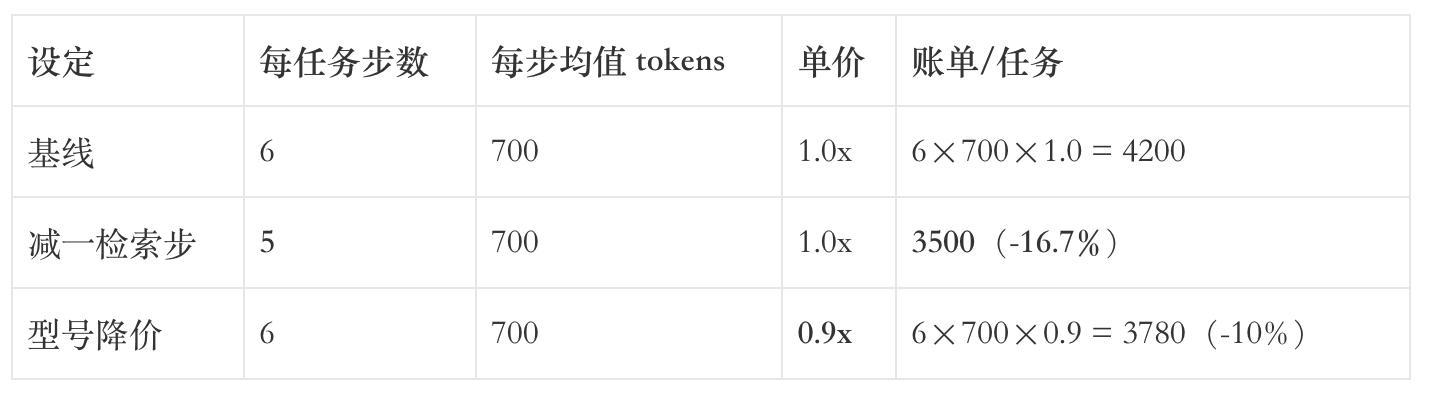
在步数≥5 的业务里,“少一检索/重排/审校步”,往往就是 >10%的确定性降幅。
35% 与 50%:两种省钱的确定性
思考 tokens是新账单大头。2025 年 AWS 团队用 DeepSeek-R1 做演示,靠提示优化把“思考 token”平均压缩 ~35%,并保持正确率不降——等价于把“多想一步”的习惯从系统里拔掉。
另一种是把慢活改成批处理。OpenAI 的Batch API把输入与输出直接打对折(-50%),前提是你接受最长 24 小时回执。很多日报、离线归档、模板生成都能迁到批通道,把“可等的步”从在线链路拆出来,在线链路的步数自然变短,每任务账单双向下降。
数字不需要花哨。一个客服日报,如果在线链路原本 6 步,迁出其中 2 步到 Batch 通道,在线只剩 4 步,线下那 2 步再打五折。这种“结构性少两步 + 结构性半价”的组合拳,远大于盯着型号价格再抠 10%。你不必等厂商降价,自己就能把账单切半。

对照案例:
- 2023–2024 年,微软研究的 LLMLingua/LongLLMLingua展示了4×–20×的提示压缩能力,常见长上下文任务能做到成本降幅 50%+而精度持平或更好;背后机理就是减少无效读写步。
- 2024–2025 年,企业把缓存 + 批处理一起用:模板与系统提示走缓存、日报走批通道。经验是两者可叠加,而不是二选一。
像换挡:把慢活丢进慢队列
你不必一次性“降维打击”所有步骤。更稳的方式是给每一步标注时间敏感度,能等的进慢队列,不能等的留在线。推理步数的本质是把“任务单位”拆成可以选择的段,随后对每段单独计价和单独降本。
两种常被忽视的降步法:
其一,推理前压缩。把多轮历史、示例、长文档先过一遍轻模型压缩,把“读上下文”这一步交给便宜的模块;主模型只读“浓缩后的信息”。微软的 LongLLMLingua 在长上下文下给出的实测是:4× 更短输入+ 质量反升(NQ 提升 21.4 个点的 case),对在线延迟也有 1.4×–2.6× 的加速——就是在主链上少了一步“读冗余”。
其二,自托管或大规模并发时的“推测解码/投机采样”。工程侧把“每步生成的计算量”降下来:Snowflake 在 Copilot 里用投机解码做了延迟与吞吐的 4× 级提升——在自建或专有 GPU场景,吞吐×速度≈成本弹性;本质是在每步里少算。
一个小流程,把“步数治理”变成日常:
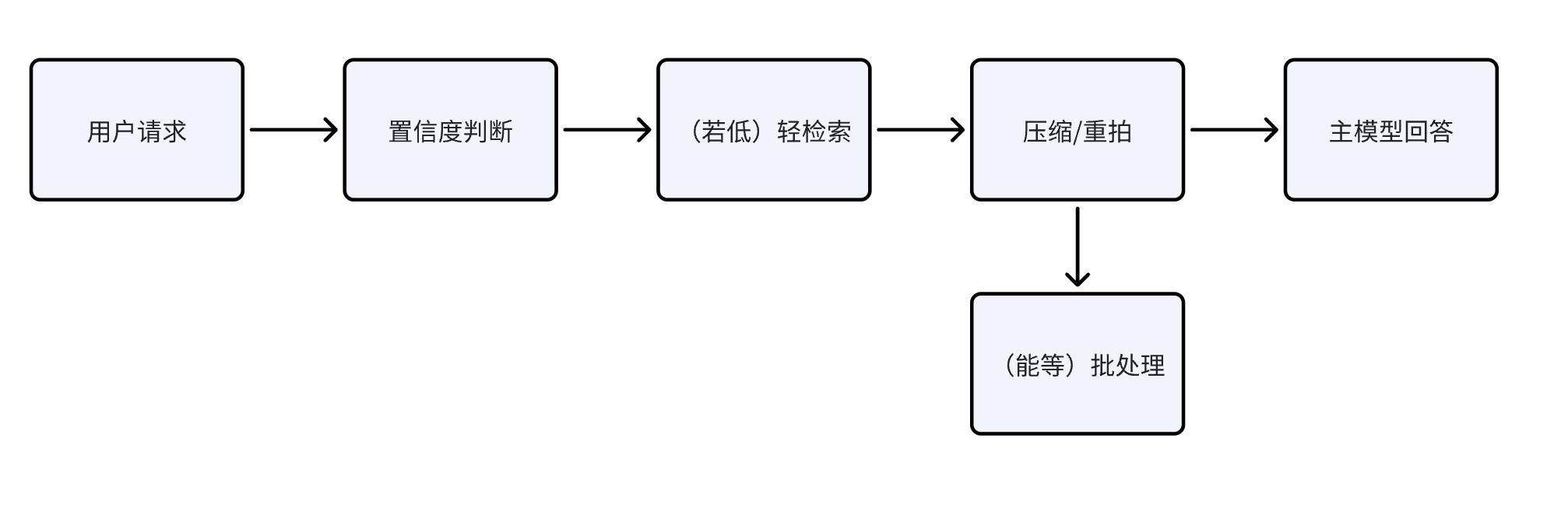
这条链子只做一件事:每过一关先问一句“非做不可吗?”。能等,就进慢队列;能省,就用压缩;能并行,就别串行。你会发现,价格表保持不变,每单成本也能肉眼可见地往下走。
接下来 12 个月:先装闸门
给“多想一步”设预算。面对 o1/o3/DeepSeek-R1 这类会“长考”的模型,先在提示里明确思考上限与输出规范,AWS 的演示给出过一个可复用的门槛:在 HLE 子集上,用 Prompt Optimization 把平均“思考 token”从 3,063 压到 1,898,完成率从 80% 提到 90%。
为“按次计费的工具”装止回阀。Responses/Assistants 的File Search按$2.50/1K 次计,Code Interpreter 按每会话 $0.03 计,Web 搜索还有“搜索内容 tokens”的型号差异。默认全开,就等于默认多走几步。把“何时调用工具”做成条件触发,每少一次工具步,都不是小钱。
把“能等的步”一律下沉到 Batch。你会很快发现,50% 折扣叠加缓存 90% 折价,带来的单位降幅,几乎不可能被“型号再降 10%”追上。
再回头看“模型单价”。当然要比,但把它放到最后一步。先把步数减掉 1,再去比型号、谈折扣,次序反过来,账单才会真的往下走。
收官:这几条路更稳
先简单收束:同一型号的“少一步”,往往胜于“再便宜 10%”。把“步数治理”当作产品设计的一部分,才是更可复制的做法。
- 先装闸门,再加油门(风险防御向):对“思考tokens”“工具调用”“外部检索”设显式预算与触发条件;默认不开,命中才开。坏答案可以回退,失控的步数很难回头。
- 把能等的任务排队(经营结构向):把“日报/归档/模板化生成”强制进Batch;在线链路只留决策步与呈现步,离线链路吃50%折扣——慢就是便宜。
- 让压缩成为默认(架构向):在主模型前放提示压缩/历史裁剪的轻模块,先把上下文变瘦,再让大模型动手;典型长文任务能拿到4×以上的输入收缩。
- 按次计费要可见(治理向):对FileSearch、WebSearch、CodeInterpreter做显式计数器与用户可见的开关,用UI告诉用户“这一步会花钱”,自然就少走一步。
- 给深研装白名单(增长向):把“多查一步/多想一轮”做成可申领的高级能力,在高客单价场景放开,用“体验差异”换取愿付溢价;其它场景保持克制。
- 定价即治理(产品向):把“高频轻量”和“低频重度”拆开卖——周内轻用走mini/缓存价,月末重算走big+Batch;让步数结构而不是型号名字,成为你的价格锚点。
删掉多余的那一步!
世界会继续降价,账单未必会。真正让人睡得着的,不是下一次促销,而是把多余的一步删掉后的安静。我们对冲不确定性的方式,从来不是把眼睛盯在价目表上,而是把流程的选择权拿回手里——先问一句“非做不可吗”,然后把能等的放慢,把能省的省掉。
当系统少想一会儿、队列慢一下、检索轻一点,产品的质地并不会塌,反而更清澈。省下来的不是几分钱,而是团队的专注、机器的喘息、用户的耐心。愿每一次“算了,这步先不做”的克制,都能换来一次更长久的奔跑。明天第一单开始,少走一小步,让账单也往后退半格。
专栏作家
言成,人人都是产品经理专栏作家。悉尼大学的IT & itm双学位硕士;始终关注AI与各产业的数字化转型,以及AI如何赋能产品经理的工作流程。
本文原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。














