
OpenAI 前研究掌门 Bob McGrew 用一句话点破 2025:预训练红利见顶,真正的机会在“推理”。从 O1 到 O3,短短半年模型学会“先打草稿再回答”,思维链(CoT)让 AI 从黑盒变可解释、可审计、可 Agent。文章拆解四重信号:算力瓶颈、模型黑箱化、机器人窗口期、专有数据价值重估——想在大厂夹缝里活下来,就得把业务翻译成模型能推理的流程,而不是再炼一次通用大模型。

OpenAI 的前研究主管Bob McGrew,他曾主导GPT-3、GPT-4以及内部代号为 o1/o3 的推理模型研发,并首次提出“预训练、后训练、推理”三位一体的模型演化框架。
近来,他接受了红杉资本的采访,传递了很多AI认知,我们必须好好学习一下,这里是原视频:
https://youtu.be/z_-nLK4Ps1Q?si=nSzcdu-Jr6IkIUjG
CoT的爆发
过去几年,预训练解决了“会不会说”、后训练解决了“好不好相处”,真正还没啃透的是“怎么想清楚再回答”,也就是推理。McGrew 的核心观点可以浓缩为四点:
1. 推理正进入爆发年
预训练与后训练仍重要,但边际收益在下降;2025 年的真正增长点在推理。推理是一项“新技术栈”,一旦技术范式新,计算、数据、算法效率都会出现巨大改进空间。
2. 模型缺的不是答案
公开数据大多只有最终结论,没有中间思考过程。
人类回答复杂问题前会“打草稿”,而早期模型(包括 GPT‑3)没有这一步。
推理训练的价值就在于让模型学会自发生成并利用思维链,不再只靠模仿公开的人类推理痕迹。
3. 从 O1 预览到 O3
短短六个月,O1 不能用工具,O3 已能在思考过程中调度工具,这是显而易见却实现困难的“易取突破”。
随着这些明显改进逐步完成,后续提升会更艰难,速度会放缓。
4. 研发进入深水区
如今顶尖公司内部在推理上投入剧烈,很多关键进展不会再在学术圈公开。
外部研究者可能只能看到“大厂几年前已经摸索过的路”。也就是说,推理研究的“黑箱化”趋势会加速。
PS:这里我反而不太认同了,因为当前国内外模型依旧在角力,很多隐藏的秘密,总是会被好事者暴露出来,CoT就是最好的例证
以下是我对McGrew推理一块观点的一些思考:
关于CoT的思考
过去的大模型是直觉型选手:直接输出答案,但思考过程不可见、不可控,但是他又经常出现幻觉,这对AI应用来说就是巨大黑盒!
在这个基础上,DeepSeek-R1首先暴露了Cot技术,让模型从“报答案”升级为“写解题步骤”,以下是个简单示例:
# 传统模式
输入:
“1250×18+3300÷6=?”
输出:
“22500” ❌(无法验证对错)
# CoT
步骤1:计算1250×18=22500
步骤2:计算3300÷6=550
步骤3:22500+550=23050 ✅
Cot对AI应用带来了巨大的意义:首先是可解释性,人类可以直接看到思维链,有利于发现漏洞,这对于医疗、金融等严肃领域尤为重要;其次是可靠性,将大题拆小,减少拍脑袋式幻觉,这也让检查便简单了;然后是知识引入,思维链可嵌入调用 API → 读结果 → 再思考循环,形成真正的Agent工作流,比如医疗问题,便可以直接植入临床指南,可信度大幅提升;
Cot可以说是DeepSeek的巨大贡献。
而后3月,ChatGPT也不得不跟进,紧急上线Toolformer,不情不愿的打开自己的黑匣子。
4月,Google Gemini 1.5集成ReAct引擎,官方大方承认受DeepSeek启发。
至此,Cot几乎成为了模型标配,而他真正的意义是在AI应用前端。比如以下案例:深夜2点,一笔境外珠宝消费触发了银行风控警报。
这里AI会有自己的逻辑链:用户历史消费均在本地 → 此次境外交易异常1小时前刚在本市加油→ 地理跳跃不合理触发“深夜+高额+陌生品类”规则→ 自动发起短信验证用户未回复验证码→ 最终拒绝
AI将决策拆解为可验证的步骤流,如同程序员写下代码注释,这在每个行业都适用,比如:医疗诊断:嵌入临床指南思维链。症状A+检测B→对照标准C→输出结论,误诊可追溯至具体环节;教育评分:作文评价展示“扣分轨迹”。“语法错误×3+逻辑断层×1” → 学生针对性改进;
预训练的瓶颈
关于预训练McGrew的核心观点是:预训练不会消失,但已进入收益递减期:智能提升≈对数,算力投入≈指数。训练下一代模型不只是加班加点,而是等新数据中心、等多年级别的基础设施升级。2025 年预训练的真正价值在于改进架构(更长上下文、更高效利用上下文等)。即便主攻推理,你也得用新架构从头再预训练一遍,再接着做推理阶段的优化。
2年前,很多团队还谈自己训练基础模型。如今算力瓶颈与资金门槛把这条路基本封死。
真正落地应用的人普遍转向 拼装现成模块 + 轻量化微调,甚至微调的人也越来越少了,多数人就一套RAG了事,大家的关注点都逐渐转向了数据工程。
只有这些了?
McGrew认为,“三大支柱”之外基本没有新的基础概念了。
到 2035 年回看,我们今天已经把强 AI 的底层拼图找齐:Transformer 架构的语言模型、可扩展的大规模预训练、推理技术,以及贯穿始终的多模态能力。
未来更多是把这些砖块砌得更高,而不是再发现全新砖块。
2020 年 GPT‑3 训练完成时,OpenAI 内部就看清了路线图:继续扩大预训练规模,从 GPT‑3 升级到 GPT‑4;增强多模态;让模型能操作计算机;让模型回答前先“花时间思考”(推理/COT);
这些方向在 Anthropic 分家前就一起探索:有的人去了 Anthropic 做“电脑操作”,有的人留在 OpenAI 做 Operator。只是多模态等能力成熟需要时间。
结合McGrew所述,OpenAI已经对AI应用的发展做过预测,并且他认为10年左右就会实现:
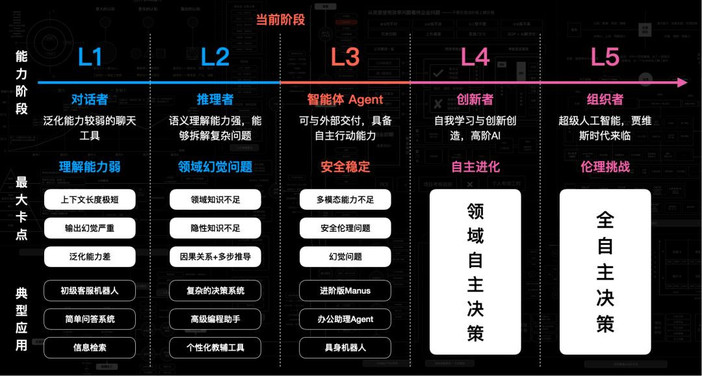
这里可以回归此框架:
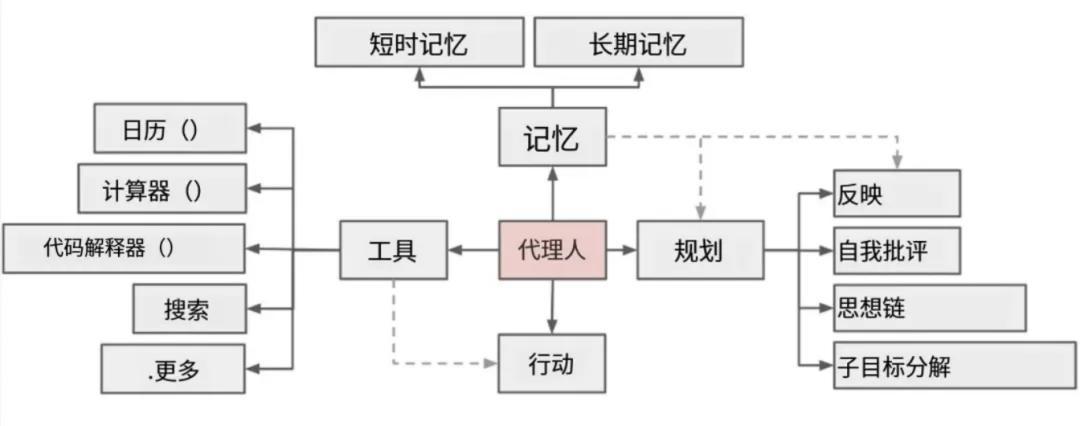
大模型解决规划与调度问题,Manus能爆发的核心原因就是模型能力大幅增强;RAG解决幻觉问题,当前模型的发展趋势来说,模型上下文破百万是早晚的事,如何让模型聊得像人,体验好的AI分身这类应用,将在这两年诞生;工具链解决多模态问题,包括最近很火的MCP、Computer Use其实都算是AI多模态能力的延伸,要的就是解决AI各种“不行”的问题,这里包括了听觉、视觉、触觉等;
如今我们已经进入L2.5时代,模型本身能力虽然还在发展,但更多是两个点:第一是上下文的长度,这个是为了解决记忆问题;第二是模型的理解能力进一步提升,这个其实当前做得很好了,只不过更垂直领域知识不足;
综上,模型需要富贵的能力范围清单已经出现了,比如:
记忆模块现在用的是RAG技术,但这个能力大概率会被模型内置,现在大家还熟知的向量库什么的,我认为在接下来1、2年会成为历史。
模型会留出合适的接口,让我们可以更好的注入领域知识,毕竟现在模型上下文已经轻易过10万了。
我这里有表达的是,模型的底层发展不会总是盯着理解与泛化能力出发,他们要切实的解决工程应用的问题,这包括了记忆与各种多模态技术,比如:语音相关、视频相关、什么图生文、文生图,视频语音什么的…
Agent的机会
McGrew 认为,Agent 再强也会被激烈竞争逼到“算力成本+微利”。
别用“人类这活儿值多少钱”来给 Agent 定价。模型量产后,原本靠稀缺人力支撑的高价会迅速塌陷。
模型层同质化严重,训练只是为巨头抢占应用入口(如 ChatGPT、编程助手)提供资格;要赚钱,仍得靠传统壁垒:网络效应、品牌、规模经济,而不是“我也接了个大模型”。
这里对我们这些创业公司来说必须重划任务边界。
把业务拆成可推理、可闭环的数据流;从单人效率跳到多人协作;用产品语言讲清“风险谁担、流程如何审计”。
当大家都能调用同样的大脑,你要构建的是身体、制度和持续学习的循环。
AI的机会不在模型
McGrew 说,若想找大厂还没深耕、但正要起飞的方向,他会押注机器人。
不是因为巨头不做,而是它们的重心还在别处,节奏较慢;而机器人正从科研挑战迈向商业落地的临界点,可能几个月到一两年内就能跑出真正的生意。
为什么是现在?过去他在 OpenAI 做机器人(比如教机械臂解魔方)更多是“秀肌肉”,离商业很远。今天情况变了:大语言模型成了机器人的自然语言接口,用极低成本就能描述复杂任务;视觉理解与通用智能结合,机器人不再只能“死磕一个动作”,而是能快速泛化到一批通用任务(折衣服、拆纸箱、装蛋盒等);过去十年的算法、模型和数据基础已足够厚,新创公司可以直接“站在堆栈顶端”开发产品。
因此,现在正是成立 Physical Intelligence、Skild 那样的机器人公司的好时机:技术准备度已高,商业化窗口刚刚打开。
这里需要补充一句,我近来和很多做硬件的公司有接触无论是无人机还是机器人,其壁垒是比较深的,要进入市场需要花5年以上的世界,而这不是搞模型的公司应该轻易入场的地方,大家各有擅长。
AI时代的安全区
顶尖 AI 公司能在应用层拿走多少?McGrew 并没正面算份额,而是换了个问法:创业公司哪里安全,哪里会被碾压?
他给出的答案是:去做“模型之外”的深水区。
巨头习惯把问题抽象成“再训练一个模型”,而企业真实世界里充满了流程、监管、脏数据和人际协作,这些零碎、小而杂的场景不值得 OpenAI/Anthropic 为每个单独训练模型。
Palantir 的 AIP、他顾问的 Distil 都在干这件事:围绕模型搭建系统,把企业内部背景信息“捞”出来、结构化,再喂回模型,让模型能真正参与决策。
机会的两层:受监管、流程标准化的行业(如医疗理赔):通过一层“转译”就能让 AI 安全介入。非监管、流程混沌的行业:先把“说不清的工作”变成可描述的流程。Distil 就用 AI 访谈员工、整理历史数据,把隐性知识显性化,才有自动化的可能。
这正是“模型需要深入各行业”的现实案例:价值在模型周边,在把业务世界翻译成模型能推理的语言里。
AI时代,什么还值钱
几年前,“垂直行业大模型”一度风行:金融、医疗等公司坚信,凭借多年积累的专有数据,在 GPT、LLaMA 之上再训一个行业模型,就能获得独到优势。
McGrew 的观察却很残酷:这些模型几乎都被下一代通用模型轻松超越。
原因很简单:真正决定上限的是模型的综合智能与吸收新信息的能力,而不是对既有材料的死记硬背。
换个角度看所谓“专有数据”:它往往只是人类多年的经验堆积,无数客户访谈、案例整理、调查问卷…
可当下的大模型已经能以极低成本复制这类劳动。你完全可以让 AI 主动给客户打电话、发起大规模调研;让它和 O3 这类推理模型长时间对话,把案例研究系统化。
结果是:原本昂贵、稀缺的“人工经验”被快速、廉价地再生产。
这意味着机会不再是“把数据关在自家仓库里训练一个模型”,而是用现成的顶尖模型去自动化采集、提炼、更新你的业务知识,把“专有经验”变成一个持续运转的获取—验证—沉淀循环。
专有数据的壁垒,从静态的“拥有”变成动态的“运营”。当智能供给不再稀缺,真正的壁垒是你能否最快、最系统地把现实世界翻译成模型可执行的知识与流程。
当被问到 Cursor 的开发者数据、特斯拉的自动驾驶数据这类“现实世界专有数据”到底值不值钱时,McGrew 给出的答案很克制:
它们介于中间。量大,但问题也大!一旦把用户数据直接用于训练,模型可能“记住”并在下个用户那里泄露,这是使用专有数据时最现实的风险。
真正有价值的专有数据,不是那种想靠喂给模型来“炼出技能”的历史堆积,而是某个具体客户的私密上下文:财务顾问知道你的资产组合、目标与风险偏好,才能用现有专业能力给出更好的建议。
数据本身不会让顾问更专业,却能让专业真正落地到你身上。换言之:大而泛的社区数据:作用有限且有泄露风险。小而精的客户数据:是决定结果优劣的关键,但要建立在信任和授权之上。
专有数据的价值在“个性化应用”,不在“再训一个模型”。把数据当成让智能对准目标的“瞄准镜”,而不是再造一把枪。
结语
后面的内容感觉没有什么解读必要,大家去这里看看原文吧:
精译 | 红杉专访OpenAI前首席研究官:AI时代什么还值钱?
个人觉得这个文章最有用的观点也就是Cot,但并没有涉及如何使用,我们后面再针对Cot做深入讨论吧…
本文由人人都是产品经理作者【叶小钗】,微信公众号:【叶小钗】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。














