
长上下文能力曾被视为大模型的“质变突破”,但它真的如我们想象中那样有效吗?本篇文章将从技术原理、产品实践与用户体验三个维度,拆解长上下文的失效机制,揭示其在真实场景中的边界与误区,并提出更具现实感的产品思考路径。

随着前沿模型的上下文窗口不断扩大,长上下文支持多达100万个标记,我看到许多令人兴奋的讨论,探讨长上下文窗口将如何解锁我们梦寐以求的智能体。毕竟,有了足够大的窗口,你只需将所有可能需要的东西——工具、文档、指令等等——都放入提示中,然后让模型处理其余的事情。
长上下文激发了RAG的热情(当你可以把所有内容都放在提示符中时,不需要找到最好的文档!),启用了MCP炒作(连接到每个工具和模型都可以做任何工作!),并激发了对代理的热情。
但实际上,更长的上下文并不一定能生成更好的响应。上下文过载可能会导致你的智能体和应用程序以意想不到的方式出现故障。上下文可能会被污染、分散注意力、造成混淆或产生冲突。这对依赖上下文来收集信息、综合研究结果和协调行动的智能体来说尤其成问题。
让我们梳理一下上下文可能失控的情况,然后回顾减轻或完全避免上下文失败的方法。
上下文失败的几种可能:
- 上下文中毒:当幻觉进入上下文时
- 上下文干扰:当上下文淹没训练时
- 上下文混淆:当多余的上下文影响响应时
- 上下文冲突:当上下文的部分内容不一致时
上下文中毒
上下文中毒是指幻觉或其他错误进入上下文,并在其中被反复引用的情况。
Deep Mind团队在《Gemini 2.5技术报告》中指出了上下文中毒的问题,我们上周已经对此进行了剖析。在玩《宝可梦》时,Gemini智能体偶尔会在游戏过程中产生幻觉,从而污染其上下文:
这种问题的一种特别严重的形式可能会在“上下文中毒”中出现——即上下文中的许多部分(目标、摘要)被有关游戏状态的虚假信息“污染”,而消除这些虚假信息往往需要很长时间。结果,模型可能会执着于实现不可能或不相关的目标。
如果其上下文的“目标”部分被污染,智能体就会制定出毫无意义的策略,并重复行为以追求一个无法实现的目标。
上下文干扰
上下文干扰是指当上下文变得过长时,模型会过度关注上下文,而忽略了它在训练过程中所学的内容。
在自主工作流程中,随着上下文的不断增加(即模型收集更多信息并积累历史),这种积累的上下文可能会变得分散注意力,而不是有所帮助。玩宝可梦的双子座智能体清楚地展示了这个问题:
虽然Gemini 2.5 Pro支持100万个以上的token上下文,但如何让智能体有效利用这一特性,是一个新的研究前沿。在这个智能体设置中,观察发现,当上下文显著超过10万个token时,智能体倾向于从其庞大的历史记录中重复行动,而不是生成新的计划。这一现象虽然只是个例,但凸显了用于检索的长上下文和用于多步骤生成推理的长上下文之间的重要区别。
该智能体没有利用其训练来制定新策略,而是执着于重复其广泛上下文历史中的过往行动。
对于较小的模型,分心上限要低得多。Databricks的一项研究发现,Llama 3.1 405b的模型正确性在约32k时开始下降,而较小模型的下降时间更早。
如果模型在上下文窗口填满之前很久就开始表现失常,那么超大上下文窗口的意义何在?简而言之:总结长上下文为何失败事实检索。如果你不做这两件事,就要警惕所选模型的分心上限。
上下文混淆
上下文混淆是指模型使用上下文中多余的内容来生成低质量的响应。
有那么一会儿,感觉真的就像每个人都要推出一个多模态计算平台(MCP)。一个强大的模型,连接到所有你的服务和各种东西,完成所有琐碎任务的梦想似乎触手可及。只需把所有工具描述都放进提示词里,然后点击执行。克劳德(Claude)的系统提示词为我们指明了方向,因为它主要是工具定义或使用工具的说明。
但即便整合与竞争不会减缓MCP的发展,上下文混淆也会。事实证明,工具太多也会有问题。
《伯克利函数调用排行榜》是一个工具使用基准,评估模型有效使用工具响应提示的能力。现在已经是第三个版本了,排行榜显示,当提供多个工具时,每个模型的表现都更差长上下文是如何失败的此外,伯克利团队“设计了提供的函数都不相关的场景……我们期望模型的输出是没有函数调用的。”然而,所有模型偶尔都会调用不相关的工具。
浏览函数调用排行榜时,你会发现随着模型变小,问题变得更严重:
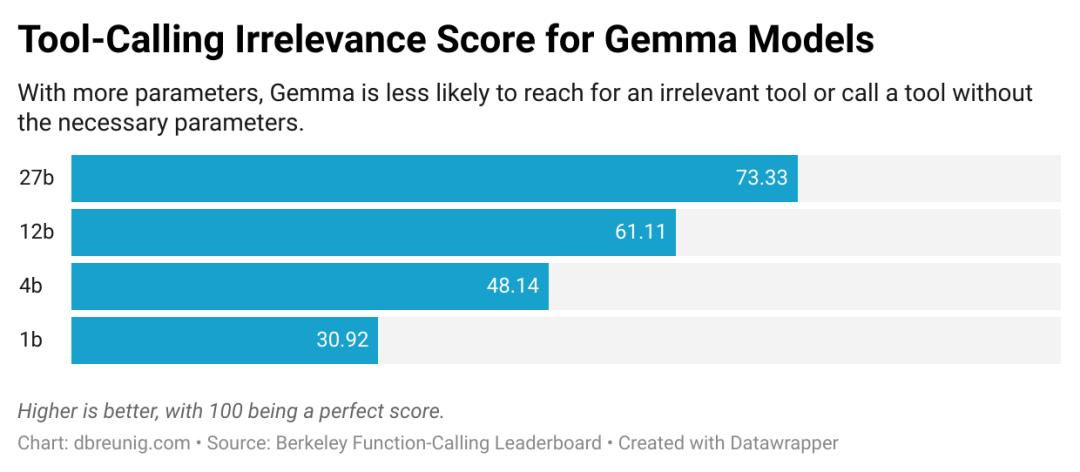
上下文混淆的一个显著例子可见于最近的一篇论文,该论文评估了小模型在GeoEngine基准测试中的性能,这是一项包含46种不同工具的试验。当团队向量化(压缩)的Llama 3.1 8b模型提供包含所有46种工具的查询时,它失败了,尽管上下文完全在16k的上下文窗口内。但当他们只给模型19种工具时,它成功了。
问题在于:如果你把某些内容置于上下文中,模型就必须关注它。这可能是无关信息或不必要的工具定义,但模型会将其考虑在内。大型模型,尤其是推理模型,在忽略或舍弃多余上下文方面越来越出色,但我们仍不断看到无用信息让智能体犯错。更长的上下文让我们能塞进更多信息,但这种能力也有弊端。
上下文冲突
上下文冲突是指在你的上下文中积累了与上下文中其他信息相冲突的新信息和工具。
这是_上下文混淆_的一个更具问题的版本:这里的错误上下文并非无关紧要,而是直接与提示中的其他信息相冲突。
微软和Salesforce的一个团队在最近的一篇论文中出色地记录了这一点。该团队从多个基准测试中提取提示,并将信息 “分片” 到多个提示中。可以这样理解:有时,你可能会坐下来,在按下回车键之前,先在ChatGPT或Claude中输入段落,仔细考虑每一个必要的细节。其他时候,你可能先输入一个简单的提示,然后在聊天机器人的回答不令人满意时再添加更多细节。微软/Salesforce团队对基准测试提示进行了修改,使其看起来像这些多步骤的交流:

左侧提示中的所有信息都包含在右侧的多条消息中,这些消息将在多轮聊天中依次呈现。
分片提示产生的结果明显更差,平均下降了39%。该团队测试了一系列模型——OpenAI备受赞誉的o3的得分从98.1降至64.1。
发生了什么?为什么分阶段收集信息时模型的表现比一次性收集时更差?
答案是“上下文混淆”:包含整个聊天交流内容的组合上下文,包含了模型在“尚未掌握所有信息”时对挑战的早期回答尝试。这些错误答案仍然存在于上下文中,并在模型生成最终答案时对其产生影响。团队写道:
我们发现,大语言模型(LLMs)常常在对话早期就做出假设,并过早地尝试生成最终解决方案,且过度依赖这些方案。简单来说,我们发现当大语言模型在对话中走错方向时,它们就会迷失方向,无法恢复。
这对智能体构建者来说可不是个好兆头。智能体从文档、工具调用以及处理子问题的其他模型中收集上下文。所有这些从不同来源收集的上下文,都有可能相互矛盾。此外,当你连接到非自己创建的MCP工具时,这些工具的描述和说明与你其他提示内容发生冲突的可能性更大。
百万令牌上下文窗口的出现,感觉具有变革性。将智能体可能需要的一切都纳入提示的能力,激发了人们对超级智能助手的想象,这些助手可以访问任何文档、连接到所有工具,并保持完美的记忆。
但正如我们所看到的,更大的上下文会产生新的失败模式。上下文污染会嵌入随着时间推移而累积的错误。上下文干扰会导致智能体过度依赖其上下文,重复过去的行动而不是向前推进。上下文混淆会导致使用不相关的工具或文档。上下文冲突会造成内部矛盾,从而破坏推理过程。
这些失败对智能体的影响最为严重,因为智能体恰恰是在上下文急剧膨胀的场景中运行的:从多个来源收集信息、进行顺序性的工具调用、参与多轮推理,以及积累大量的历史记录。
幸运的是,有解决办法!在即将发布的文章中,我们将介绍减轻或避免这些问题的技术,从动态加载工具的方法到启动上下文隔离区。
阅读后续文章“如何修复你的上下文”
文章来源:
https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html#fnref:live
本文由 @yan 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务














