
编辑:KingHZ 桃子
【新智元导读】真正决定AI上限的,已从「模型规模」转为「数据质量」。从Meta押注数据平台到xAI裁员转招「专业AI导师」,全球「数据大战」全面进入下半场。中国玩家里,澳鹏数据独占一档,仅2025年上半年营收达3.06亿元。高质量、可追溯、可工程化的数据生产,正成为AI产业的新壁垒。
2025年,大模型持续高速进化,科技巨头在为「燃料」——高质量数据,展开了激烈的角逐。
数据,不再是幕后的配角,而是直接决定AI成败的核心战场。
如今,全球AI圈的「数据大战」愈演愈烈。
小扎曾豪掷143亿美金,一举挖走Scale AI创始人,并买下49%股权,只为抢占高质量数据的制高点。
这一「世纪联姻」,原本被视为Meta在AI竞赛中的杀手锏,却很快曝出「尴尬裂痕」:
负责下一代模型训练的TBD Labs,因对Scale AI数据质量大失所望,转向Surge AI、Mercor等竞争对手。

风波未平,Anthropic又因涉嫌盗用版权数据训练Claude,被迫支付15亿美元「天价和解金」。
这一惊人的数字,创下美国版权纠纷最高赔偿纪录,更宣告了AI「野蛮攫取」数据时代的终结。

与此同时,马斯克一夜之间,果断挥刀裁掉500名「通用数据标注员」,转而大力招募10倍「专业AI导师」。
重点覆盖了STEM、金融、医学、安全等领域,直指AI从海量数据堆积,向专业化精炼的深刻转型。

这些科技巨头、AI独角兽们的「数据焦虑」,并非孤例,而是AI生态下的普遍镜像——
数据,已然成为AI时代的「新石油」。
在国外,Scale AI、Surge AI、Mercor等新锐,凭借精细化标注和专家资源,成为OpenAI谷歌等巨头的「幕后推手」。
而在中国,这场「数据革命」的先锋——澳鹏数据,正以本土创新和全球视野强势崛起。
鲜有人知,中国十大互联网巨头,十大自动驾驶大厂,450+头部企业背后的高质量数据,全部来自澳鹏的AI数据引擎。
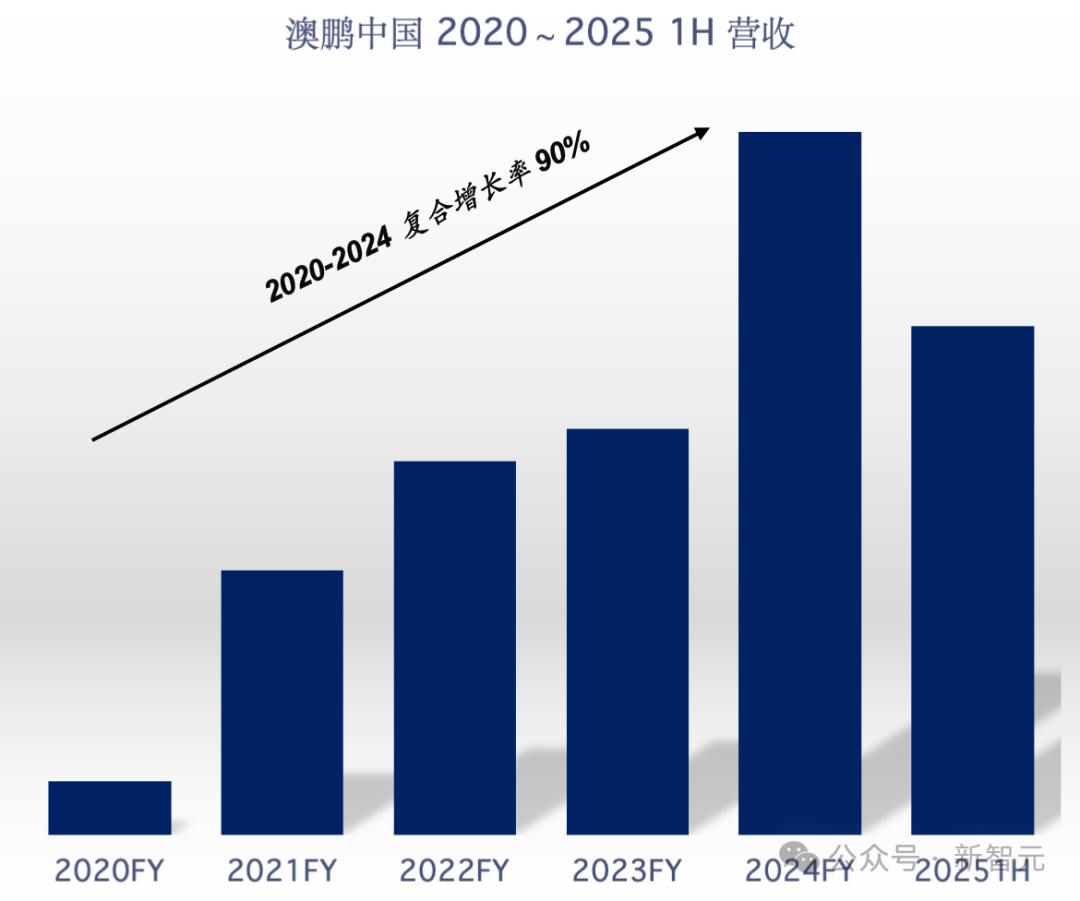
2025年上半年业绩显示,澳鹏中国区创下3.06亿元(RMB)营收新高,堪称行业标杆。
预计,全年将突破7亿大关。
这不仅仅是一个数字,而是过去五年复合增长率90%的强劲证明。
澳鹏全球高级副总裁、大中国区及北亚区总经理田小鹏博士表示:
我们正见证一场根本性的范式转变。
AI最终的竞争壁垒,在于能否构建一个强大的「数据闭环」。它以「数据工程」为引擎,能源源不断地产出稀缺、高质量的数据燃料。
说白了,未来比拼的,不仅仅是算力或模型架构,还有谁能系统性地构造出精准且稀缺的数据。
这正是当前许多行业乱象背后的根源,也为我们指明了AI数据进化的下一个关键方向。

从0跨越,半年爆赚3.06亿元
或许在许多人眼中,这无疑是「中国版的Scale AI」!
没错,但不止于此。更准确地说,澳鹏数据是融合了「Scale AI+Surge AI」双方优势的顶尖存在。
成立于2019年,总部位于上海的澳鹏数据,是Appen在中国投资,由本土管理团队创立并独立运营的领先数据公司。
它既有Scale AI在自动驾驶和多模态数据上的深度布局,又有Surge AI的高质量标注和垂类精细化服务。
比起另两家,澳鹏更深谙中国市场的脉搏,提供全球化资源与本地化交付的无缝衔接。
早在2023年,澳鹏营收就已超越国内业内友商,一骑绝尘成为中国数据服务「黑马王者」。
今年上半年,澳鹏营收已达到3.06亿元人民币,约等于2020年全年的10倍,毫无疑问是国内规模第一大的AI数据服务提供商!

这一「逆袭」并非偶然,而是五年耕耘的厚积薄发。
回顾其增长路径可以看到,澳鹏精准把握了三大关键市场机遇节点:
2020-2021年:智能语音
2022-2023年:自动驾驶
2024-2025年:大模型
2020-2021年,澳鹏数据恰恰抓住了传统AI业务的爆发期。
当时,语音识别、图像标注需求井喷,澳鹏凭借全球资源网络和本土化团队,迅速打下了基础。
其营收从2020年3000+万起步,到21年翻了五倍,达到了约1.6亿元。
到了2022年-2023年,自动驾驶技术的快速崛起,成为澳鹏数据的第二个增长引擎。
通过与中国十大自动驾驶头部公司深度合作,澳鹏营收在此期间持续翻番,2023年达到近2.44亿元。

2024-2025年,澳鹏赶上了大模型的发展,并提早布局了垂类大模型。
从ChatGPT到DeepSeek,大模型不仅重塑了全球AI竞争格局,而且给数据服务行业带来了前所未有的发展机遇。
2024年,澳鹏中国的年增长率达到70%以上,其中大模型和生成式AI相关业务增长率更是高达500%以上。
2025年上半年,乘着国内AI行业爆发的东风,澳鹏数据营收再创新高,背后主要靠五大引擎驱动:
1. 结构性增长红利
产业重心由「模型竞赛」转向「应用落地」,高质量垂类数据需求持续释放、优先级上移。
2. 供应商集中化趋势
在降本增效下,头部客户收敛供应链;具备综合能力的服务商承接高难度、高复杂度、高安全项目,集中度提升。
3. 出海数据服务突破
中国互联网企业加速出海,合规与本地化需求激增。澳鹏依托菲律宾、马来西亚、越南、欧洲等交付网络,海外业务占比近40%,提供多语种、跨文化、合规方案。
4. 冷启动数据产品化机遇
大模型迭代越来越快,成品数据集需求增长。澳鹏把数据做成模块化、可组合的高品质数据产品,大幅缩短客户开发周期并维持较高毛利。
5. 高端数据资源与服务壁垒
前瞻布局高端人才与平台(如医疗专家、专业音乐人、竞赛获奖者等),联动技术平台与十大垂类能力,支撑大模型训练与评估——高质量数据正在决定模型能力上限。
面对这些前所未有的机遇,澳鹏究竟做了哪些事儿,才能在激烈的竞争中脱颖而出?

五大平台,技术行业领先
在技术浪潮之巅,澳鹏始终以前瞻视野构筑长期技术壁垒,用创新驱动行业变革。
国内首创 端到端 通用预标注大模型,结合项目级微调,实现自动化数据标注回环,效率提升25%。
首创采集-标注-质检-交付一体化流程,减少冗余存储,提升数据处理效率30%。
从「第一性原理」出发,澳鹏重构了「数据工程」。
核心是自研的行业级预标注大模型:理解上下文、先行完成高精度初筛。
随后,人类专家只处理「最难的5%」——歧义样本、边界样本与规则冲突。
最终,修正结果回流,再次优化模型参数,形成「预标注—人工修正—模型优化」的闭环。

这一模式将数据标注效率提升数倍,同时极大降低了人力成本与主观误差,实现了效率与精度的双重飞跃。
AI前沿赛道迭起,大模型、具身智能、自动驾驶……
这些领域对数据的要求,更加苛刻:要质、要量、要多维度,全都拉满。通用工具,自然跟不上。
对此,澳鹏重金自研,搭起覆盖多领域的行业级平台矩阵:
MatrixGo、MediGo、RoboGo、AI Agent,以及大模型智能开发平台——各管一摊,又能协同作战。
比如,大模型这条线,提供从多模态数据清洗 → SFT指令微调数据构建 → RLHF偏好标注与评估。

澳鹏大模型智能开发平台
针对具身智能,机器人的「手眼脑」协调训练,需要数据作为「燃料」。
多传感器融合标注、复杂动作轨迹标注、多模态思维链标注……澳鹏RoboGo平台一站式搞定,而Scale AI甚至没有相关业务。
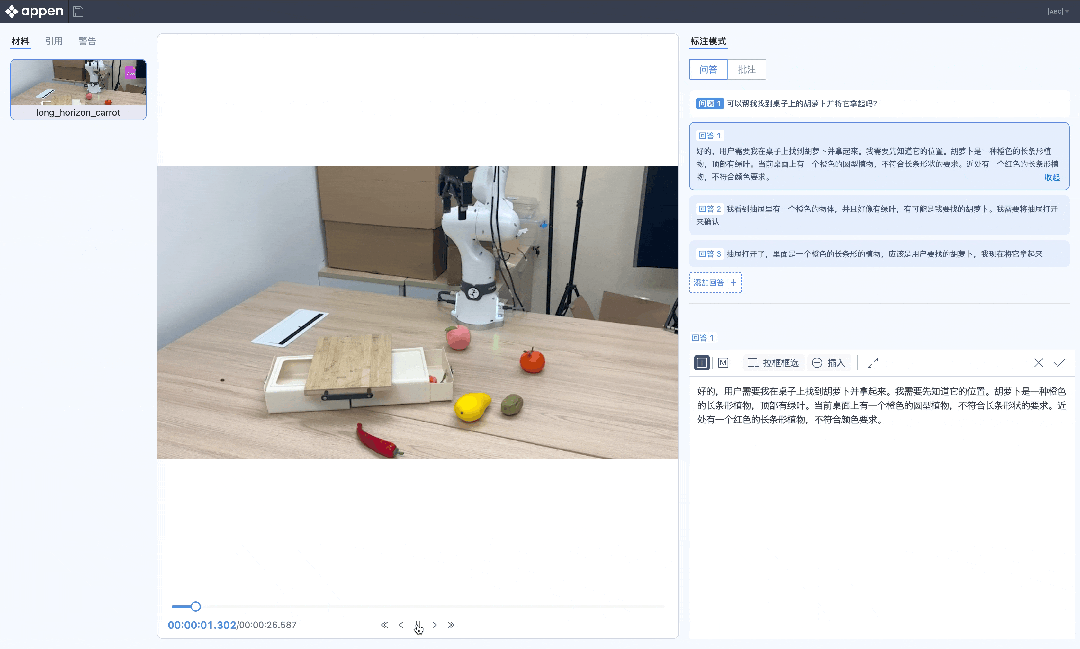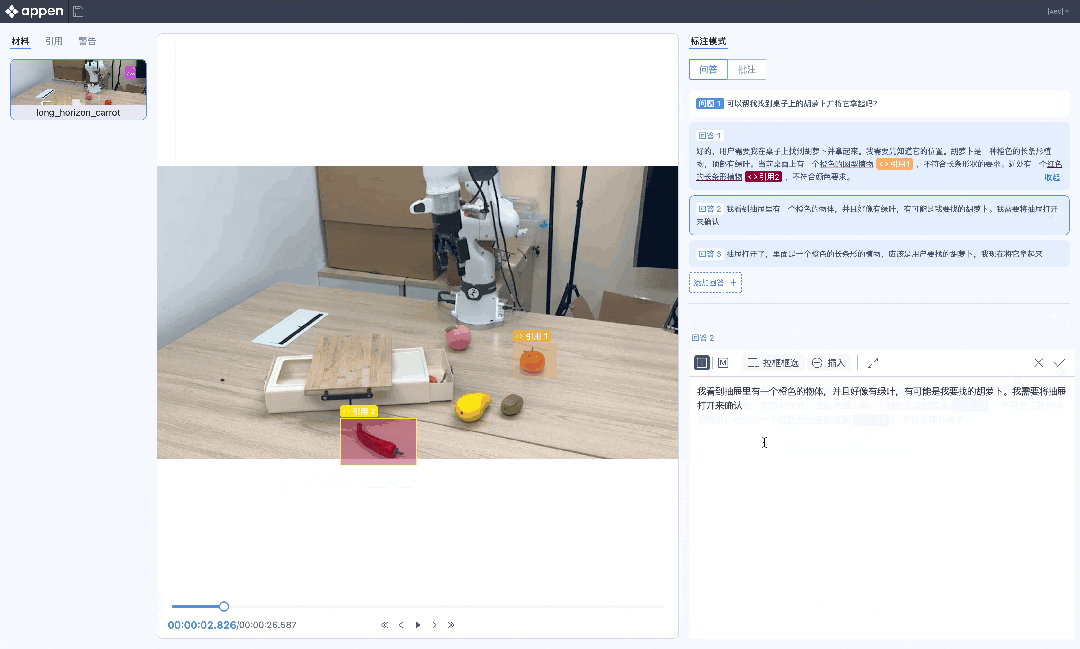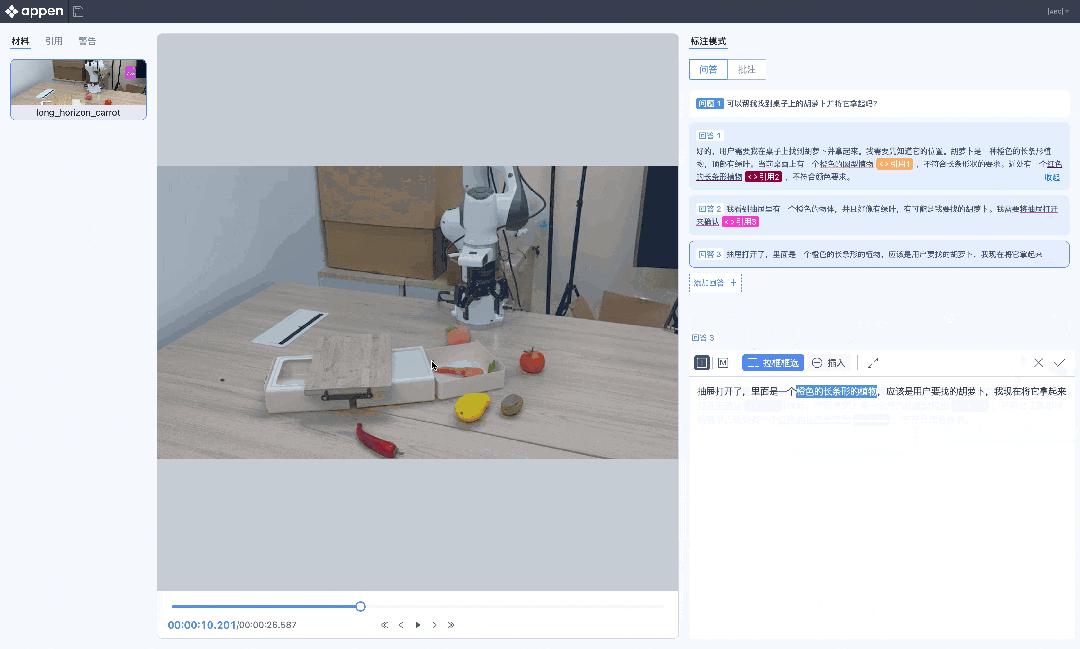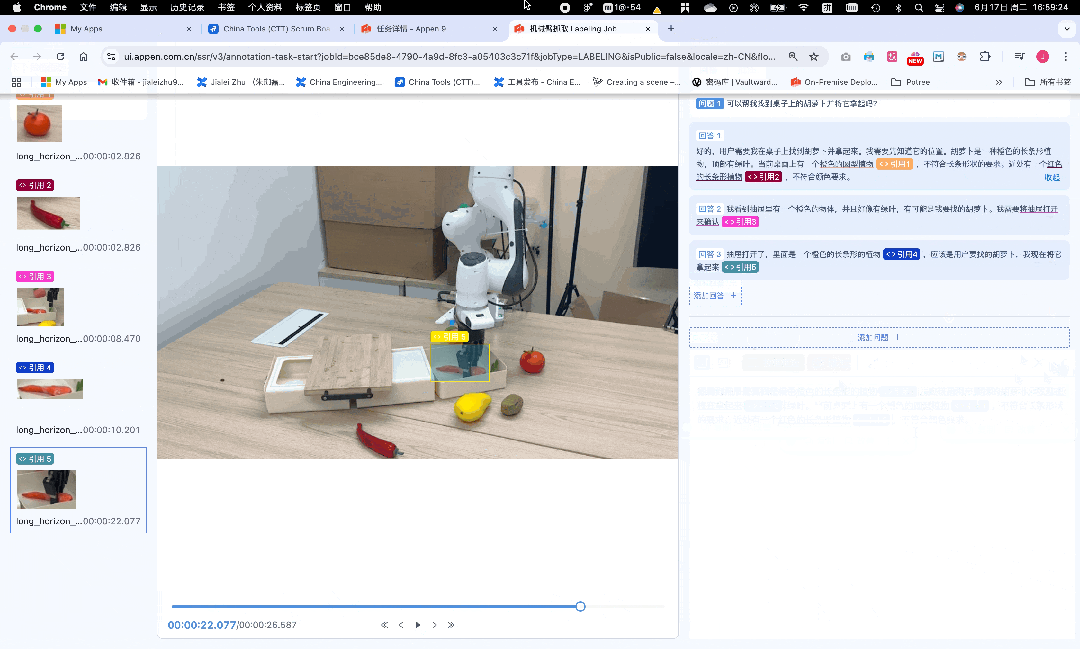
澳鹏RoboGo具身智能数据开发平台
AI+医疗应用场景更加专业。
MediGo平台内置智能标注、多模态融合与私有化部署,为医疗大模型与应用提供高精度、合规、安全的数据底座,覆盖诊疗、问诊/导诊、健康科普等八大核心场景。
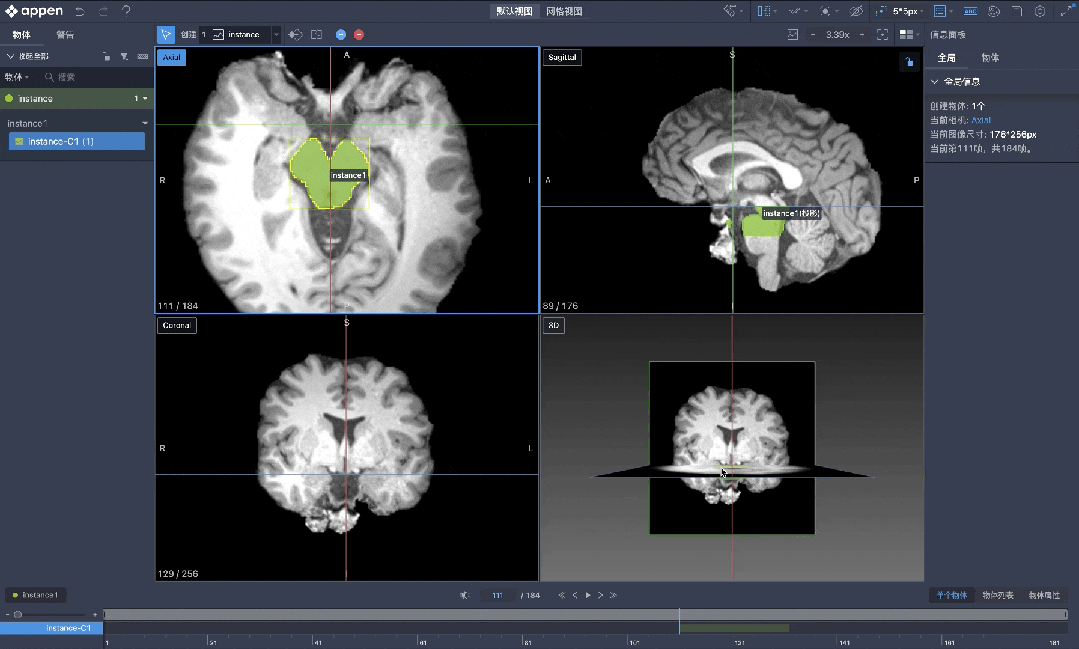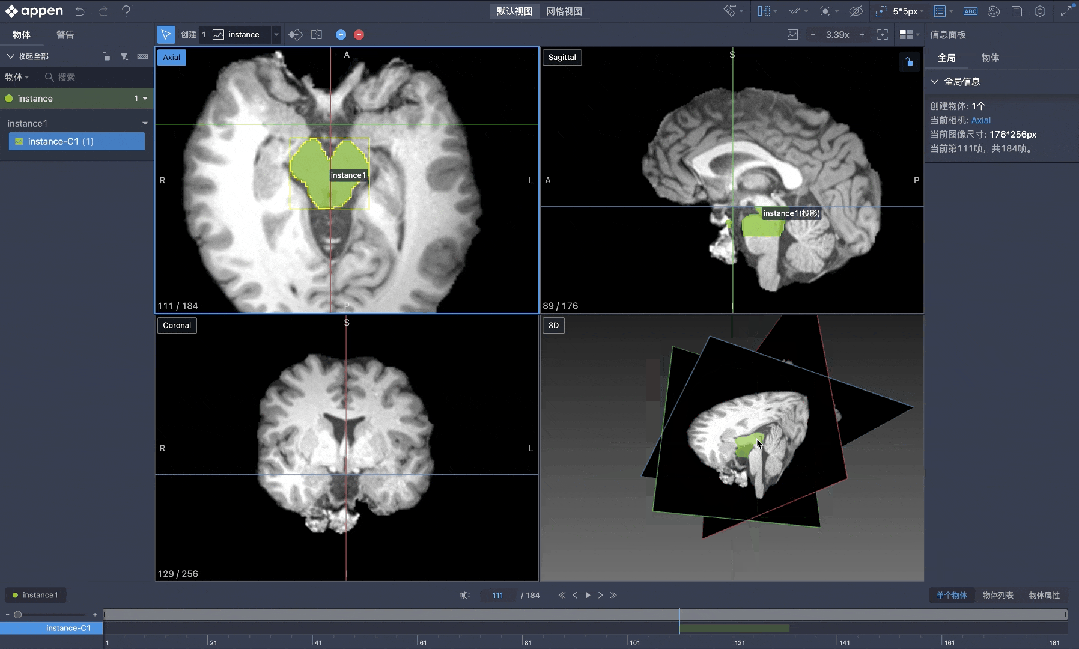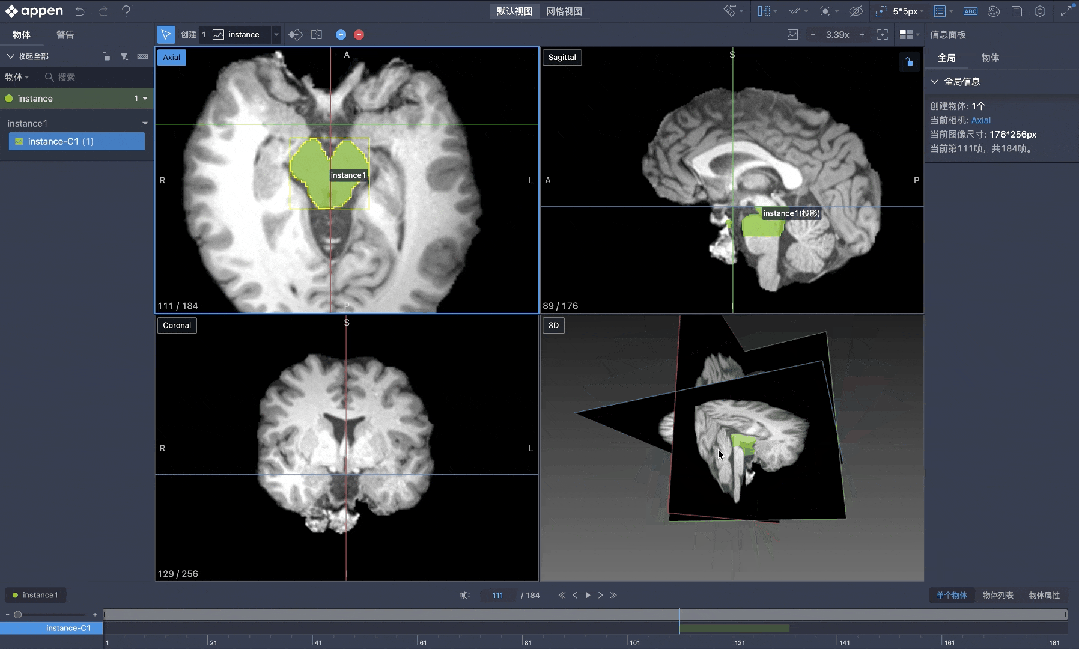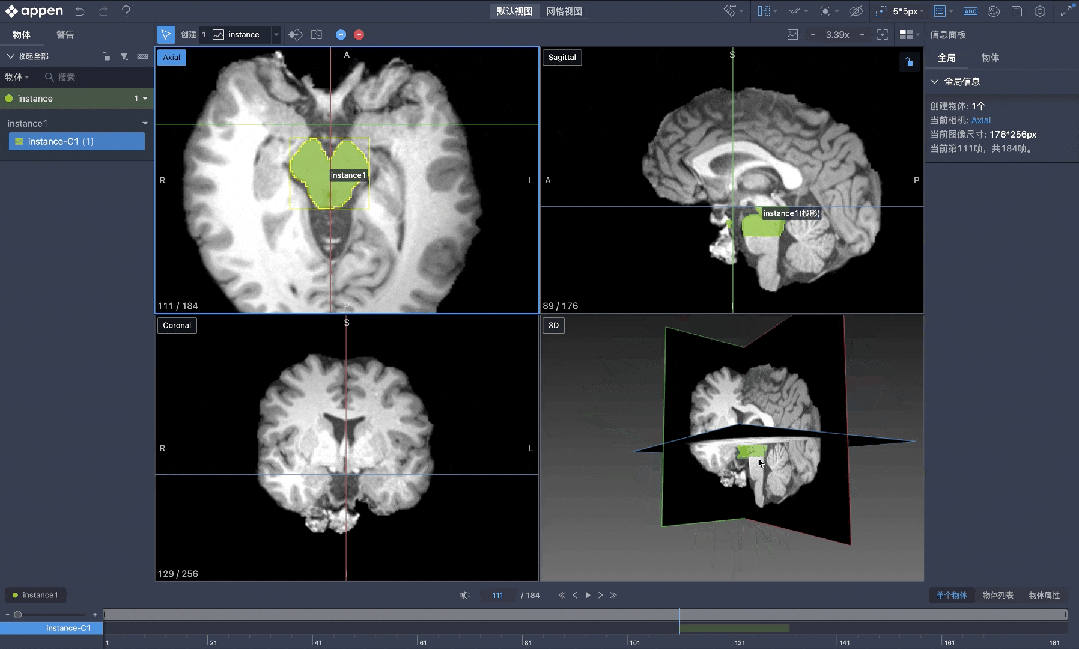
澳鹏MediGo医疗大模型数据开发平台
如今,企业级高精度数据生产平台MatrixGo,已实现一条链打通,加速迭代,稳步优化。
就自动驾驶领域来说,需求更是多样:激光雷达(LiDAR)3D点云、高精地图要素提取、4D时序标注……

澳鹏MatrixGo企业级高精度AI辅助数据生产平台
澳鹏严格对标L4+级安全标准,支撑高阶智驾算法的落地。
不仅如此,他们还正积极研发下一代数据生产智能体,自主进行数据采集、清洗、标注、扩增生成高质量的数据集。
值得一提的是,澳鹏工程团队始终秉持「天下武功,唯快不破」的理念,展现出强大的工程化落地实力:
坚持每周至少迭代更新一次产品;
确保能以最快的速度,将最新的技术成果转化为可用的产品功能。
不难看出,在技术上,澳鹏始终稳居行业前沿。
此外,在成品数据集方面,澳鹏提供800多个专业数据集,包含近10万小时的音频资源、50多万幅图像和超过一亿字/词的文本数据,涵盖80多种语言和方言。
在高难度数据集上,通过庞大的领域专家网络,澳鹏严选了1000+个来自不同细分专业领域的行业专家,构建了超10万条高难度思维链数据集,覆盖数学、计算机、物理、化学、生物、人文科学等学科。
在这些数据的助力下,有客户模型性能较公开数据基线,提升了40%。
这也是他们未来发展的底气所在。
AI下半场:高质量数据是关键
当前,AI产业正处于一个「超级周期」之中,大模型技术如潮水般涌现。
一直以来,Scaling Law并未失效,也并未放缓。
只要肯砸算力,喂给模型足够多的高质量数据,LLM能力随之增强,几乎没有天花板。

据Our World in Data统计,从2010年-2024年10月,AI训练数据量(紫色)约每9-10个月翻倍。
特别是,LLM的训练数据集,自2010年以来每年增长3倍。
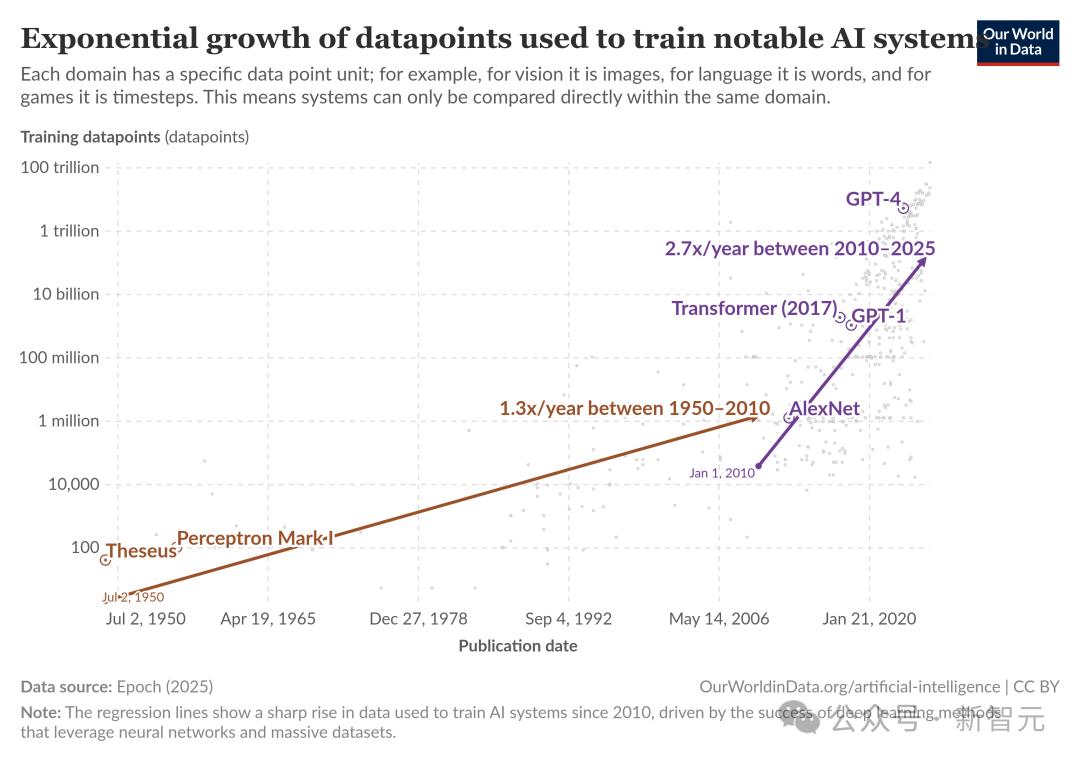
2019年,GPT-2训练大约用了40亿token;2023年,GPT-3则扩展到3000亿token;甚至外界推测,GPT-4用了13万亿token。
可以看到,LLM训练所需的数据规模,早已从传统的TB级跃升至PB级,甚至几乎耗尽了互联网上的公开资源。
统计显示,AI数据中心市场规模,预计到2032年将达789.1亿美元,年复合增长率24.5%。

随着AI竞赛的全面升级,「卖铲子」的三大数据服务商集体迎来「暴富」时刻,估值直线飙升——
- Meta砸143亿收购49%股权后,将Scale AI估值推至290亿美金;
- Surge AI寻求10亿美元融资,目标估值超250亿美元;
- Mercor目前就C轮融资进行谈判,估值超100亿美元。



左右滑动查看
这些鲜活的案例,恰恰凸显了数据,在AI生态中的王者地位。
数据「黑洞」,正无限放大
NeurIPS 2024大会上,Ilya直言,「预训练时代即将结束,互联网数据枯竭,不会继续增长」。
这一预测,曾一度引爆热议。但现实中,AI数据真的枯竭了吗?

显然不是。在澳鹏数据采访中,澳鹏数据田小鹏博士的一句话有力地回击了这一点:
AI缺的不是数据,而是高质量的数据。
现实中,依然存在大量数据未被有效利用。这些数据经过清洗和加工,可进一步作为训练数据,特别是多模态和领域专业数据。
通用AI归根结底,是为人类服务,必须满足不断变化的信息需求。对于普通人而言,近期信息需求远高于远期,这就要求LLM持续接受最新训练数据。
就如同算力一样,AI对数据的需求并未减弱,但行业正迎来转型升级——在规模、质量、复杂度上,发生了巨变。
传统深度学习仅需要GB到TB级的数据,而到了LLM时代,早已达到了PB级数据。
其次,数据质量的要求,也在水涨船高。早期的95%准确率已不足以满足需求,如今在专业领域,如量子力学、医疗健康,标注精度需达到99.5%以上。
此外,多模态数据融合,也成为了主流趋势。
从过去的2D/3D标注扩展到包含时间维度的4D标注,以及文本、图像、音频、视频协同处理,复杂度增加。
这些都对数据服务商的技术能力提出了更高要求。
面对这些新挑战,澳鹏主要采用了三大招:
1. 前瞻性技术布局与产品化能力
2. 高度灵活的智能化平台
3. 专业化人才网络与精准匹配机制
澳鹏提前研发并储备新兴数据生产平台,比如GUI轨迹采集、多模态标注工具、具身智能平台;通过即插即用的模块化产品设计,支持快速部署与灵活适配,显著提升数据服务效率。
同时,澳鹏构建了标准化成品数据集(如代码、高难度题库等),大幅缩短各细分领域模型的开发周期。
而澳鹏智能化平台,既可快速响应多模态、多场景的标注功能需求,又注重对业务规则的敏捷迭代和精细化管理能力。
这就确保了对于复杂需求的项目,澳鹏能高效、准确地落实和交付。
此外,澳鹏建立了覆盖多领域的专家资源库和人才标签体系,实现了人才与任务需求的智能匹配。
尤其是,在医学等高壁垒垂类,澳鹏精准调度具备相应资质的专业人员,保障数据交付的质量与专业性。
模型评估>训练,数据质量>规模
今年4月,OpenAI的研究科学家姚顺雨判断:
AI进入下半场,评估比训练更重要。

基准测试在快速饱和
在多个基准上,AI早已超越绝大多数人类——然而世界并未因此巨变,至少从经济学和GDP维度来看如此。
姚顺雨将此称为「效用困境」(utility problem),并视其为AI领域最至关重要的课题。
他认为,AI下半场的玩家将通过将智能转化为实用产品,打造价值亿万美元的企业。
这是数据行业的巨变:数据质量比规模更加重要!
根据最新数据,截至2025年6月,我国已建设超过3.5万个高质量数据集,总体量超过400PB,甚至高质量数据集的建设已上升为国家战略。
通用大模型的发展,给各垂直领域的AI应用提供了可能,即便是OpenAI也逐渐把目光投向了编程等具体领域。
医疗、法律、金融等专业领域的数据标注需要行业专家参与,标注准确率要求从95%提升至99.5%以上。
预计到2028年,医疗健康数据要素市场规模将突破250亿元,工业制造领域达302亿元。
这就出现了「数据荒漠」与「数据绿洲」并存的现象:
通用数据面临瓶颈,但高价值垂类数据开发程度仍低。
在许多垂直场景中,缺的是高质量数据,比如自动驾驶极端事故数据,医疗数据难以从公域获取等。
而「合成数据」恰恰可以填补部分市场空白。
举个栗子,英伟达开源的基础「世界模型」Cosmos,可以合成自动驾驶需要的部分数据。很多场景,缺乏的不是数据,而是高质量数据。

在部分场景,真实数据和合成数据可以相辅相成,甚至完全依赖合成数据,比如游戏中的图片等。
但合成数据总是带有某种假设,无法顾及到一些特殊情况等,而关键行业不容有失。
目前,绝大多数应用场景,还需要用真实数据来训练AI,要想提高性能,要通过专业人士来生产数据,从而赋能模型。
事实上,现在的数据行业对专业要求越来越高,本科早已不能满足数据行业的需求,一些企业开始招聘博士去构造训练数据!

国内的AI数据服务行业,也从人力密集型行业转型升级为技术密集型行业。
为了应对挑战,除了开发MatrixGo等五大技术平台外,澳鹏同样组建了由行业顶尖专家领衔的垂类团队:
医疗团队拥有500余名医学专家,其中15%持有执业医师资格;
金融团队300多名专家覆盖金融、保险、基金等领域,70%成员具备从业资格认证;
代码团队120余名全职工程师,覆盖主流编程语言;
法律团队由执业律师和法学专家组成;
数理团队由全国竞赛获奖者组成;
音乐团队拥有500余名兼职音乐人;
多语言团队涵盖200+种语言;
TTS团队拥有全球数十个国家、数千小时采集经验;
文学团队汇聚985/211高校人才;
美学团队则由50余名专业设计师构成。
医疗是数据门槛最高的赛道之一:多群体代表性、合规红线、周期/成本压力并存。
为此,澳鹏用「平台+专家」双轨方案破题:
数据工程平台集成智能标注、多模态融合及私有化部署能力;
专家网络确保标注准确率逼近临床级要求。
全程严格对齐GDPR、ISO等标准,并通过标准化SOP把项目周期缩短30%—50%。
结果是,更快、更准、更合规的医疗AI数据底座,加速产品落地与国际化部署。
AI的未来,数据的未来
过去,外界乃至AI业界往往聚焦于算法、算力突破,却对数据行业抱有诸多刻板印象和误解。
许多人会认为:数据行业没前景、「数据荒漠」马上来了、数据标注没有技术含量,只是体力活......
实际上,事实远非如此。
这个行业正以两位数年增长率迅猛前行,而澳鹏数据作为领军者,更是连续6年保持增速,一举拿下中国市场份额第一的「宝座」。
曾经的那些误解,早已站不住脚:无技术平台寸步难行,纯人工无法应对复杂需求。
技术平台、数据工程能力,早已成为行业的核心竞争力。
如今,AI正在由感知走向认知与推理,能力从2D静态识别扩展到4D时空建模,实现多模态融合。
随之而来的是,数据与算力的数量级提升,质量、可追溯与精细化成为刚需。
一旦自动驾驶、医疗等场景取得有效突破,就能在全球快速复制、铺开应用。
要支撑这一进程,需补齐两类基础设施:
面向世界模型的高置信度物理世界数据,以及支持企业与个人安全对接的多模态内容平台。
数据行业由被动供给,转向共建认知体系与评测标准。
依托全球资源网络、平台化研发与AI原生流程改造,在AI浪潮中澳鹏将持续突破。
展望未来3-5年,澳鹏数据战略重点清晰:深化全球资源网络、垂类深度,以及平台产品化的转型。
而他们下一个目标是:中国区2030年前营收超20亿元。
采访中,澳鹏全球高级副总裁、大中国区及北亚区总经理田小鹏博士认真分享了指引其未来的三大原则。
首先,数据服务要全球化,以合规的方式完成数据交付。这不仅是风险防控,更是企业出海的竞争力。
其次,要经营客户的广泛度和复杂度,建立真正的护城河。
也就是说,不止要做数据标注者,更要做数据咨询师,提供超出标注的增值服务,如模型评估和流程优化。
最后,要建设好平台。依靠「技术+人力资源」双平台,澳鹏提供比友商更有竞争力的服务。
只要继续坚持原则、保持过去的增速,在澳鹏看来,下一个20亿的「小目标」绝非空谈。
















