

henry 发自 凹非寺
量子位 | 公众号 QbitAI
刚刚,Meta发布了全新开源视觉模型DINOv3——
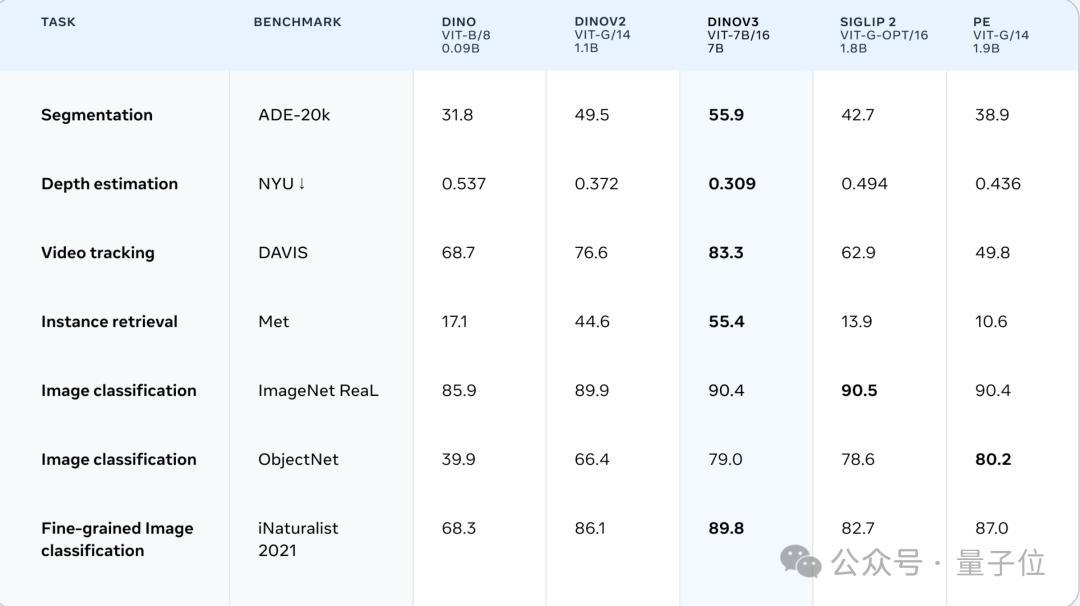
首次证明了自监督学习模型能够在广泛任务中超越弱监督学习模型。
DINOv3采用无标注方法,将数据规模扩展至17亿张图像、模型规模扩展至70亿参数,并能高效支持数据标注稀缺、成本高昂或无法获取的应用场景。
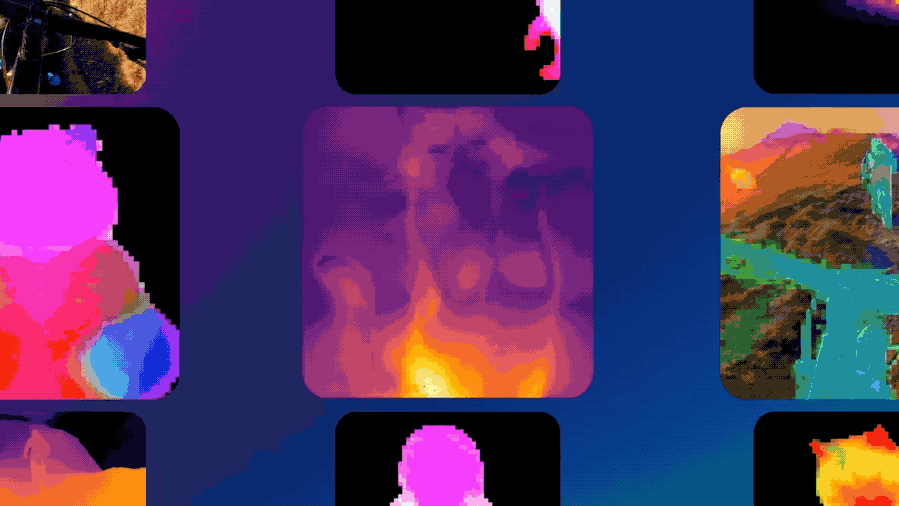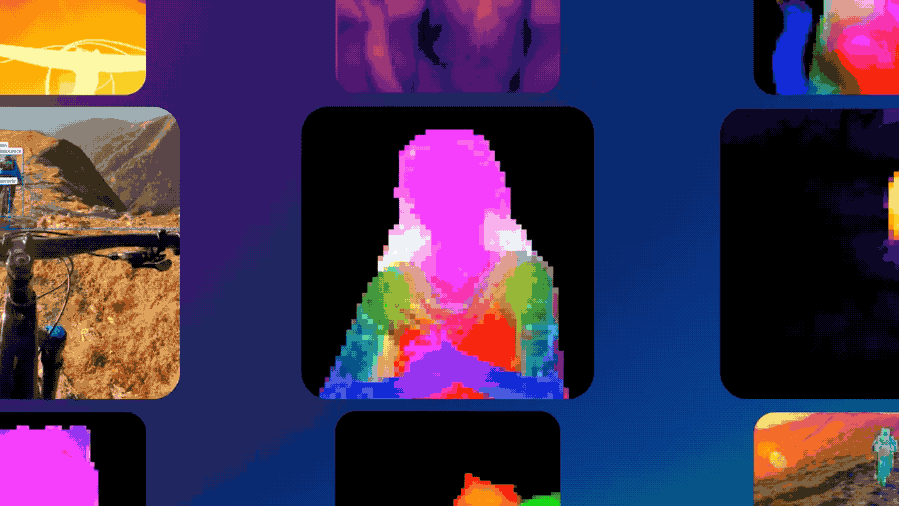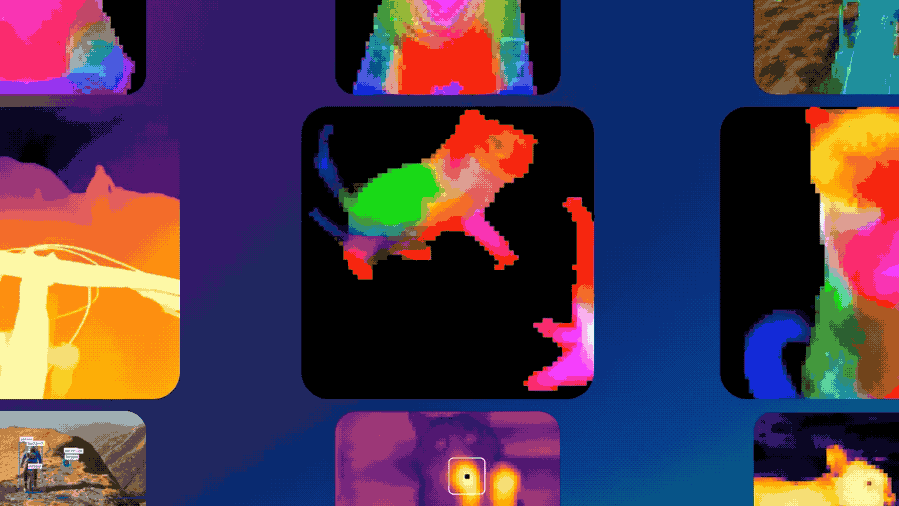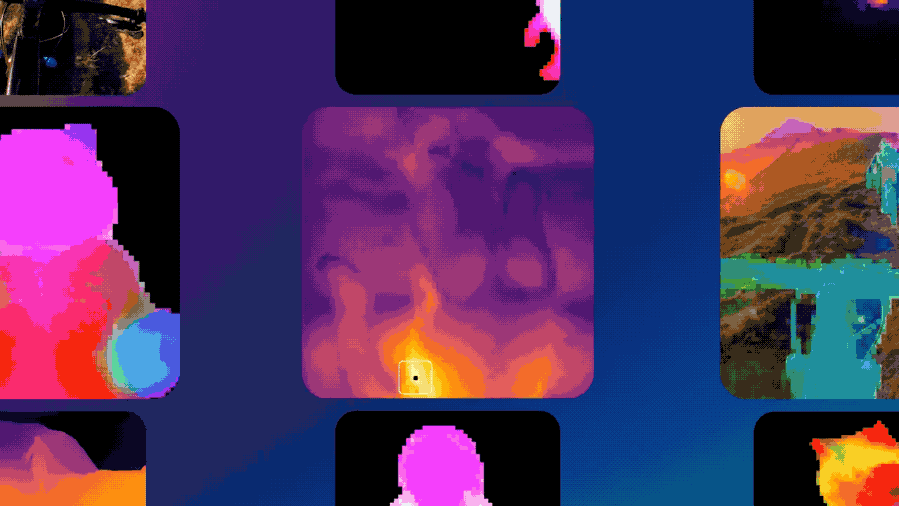
DINOv3不仅在缺乏标注或跨领域的场景(网络图像与卫星影像)中表现出绝对的性能领先,还在计算机视觉三大核心任务(分类、检测、分割)上实现了SOTA。
网友表示:我还以为你们已经不行了,好在你们终于搞出点东西来了。

计算机视觉的自监督学习
说起计算机视觉,就绕不开李飞飞老师推动的ImageNet和大规模标注数据。
然而,随着数据量的激增以及应用场景不断扩展,标注成本和可获取性成为了制约视觉模型通用性的主要因素。
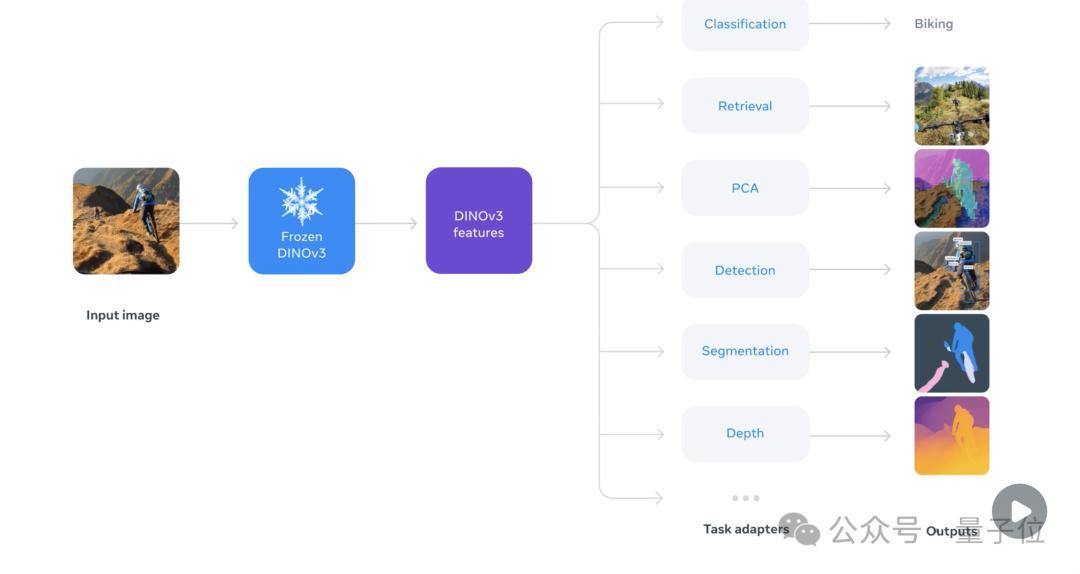
基于这一思路,DINOv3采用了创新的自监督学习方法,专注于生成高质量且高分辨率的视觉特征,为下游视觉任务提供强大的骨干模型(backbone)支持。
通过这一方法,DINOv3首次实现了单一冻结视觉骨干网络(Single Frozen Vision Backbone)在多项密集预测任务(Dense Prediction Tasks)中超越专门化解决方案的性能。
那么,DINOv3是怎么做到的?
总的来说,DINOv3的训练过程分为两个主要阶段:
- DINOv3在一个庞大且精心构建的数据集上进行大规模自监督训练,从而学习到通用且高质量的视觉表示
- 引入名为“Gram anchoring”的新方法来解决训练中密集特征图的退化问题,在不影响全局特征的同时,显著提升局部特征的质量
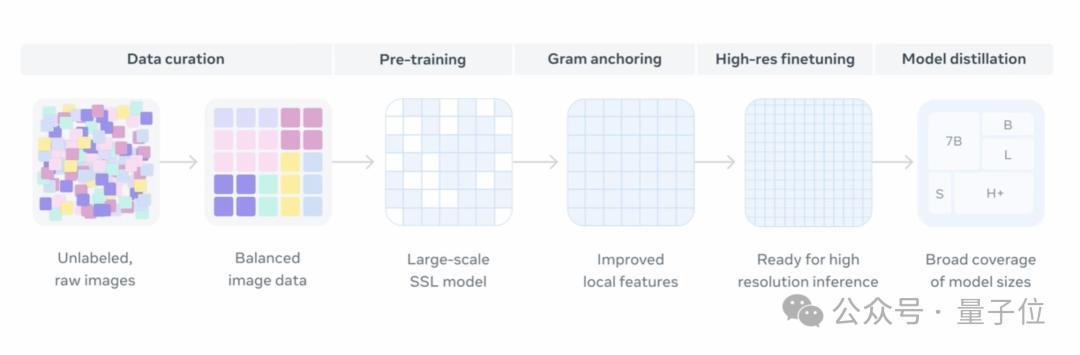
具体来说,研究者首先构建了一个包含约17亿张图片的预训练数据集。
这些图片数据主要来自Instagram上的公开图片,以及少量来自ImageNet的图片。
在对数据集进行分类、采样后,研究者采用判别式自监督(Discriminative Self-supervised),通过Sinkhorn-Knopp算法和Koleo正则稳定特征分布,实现了细粒度又稳健的密集特征学习。
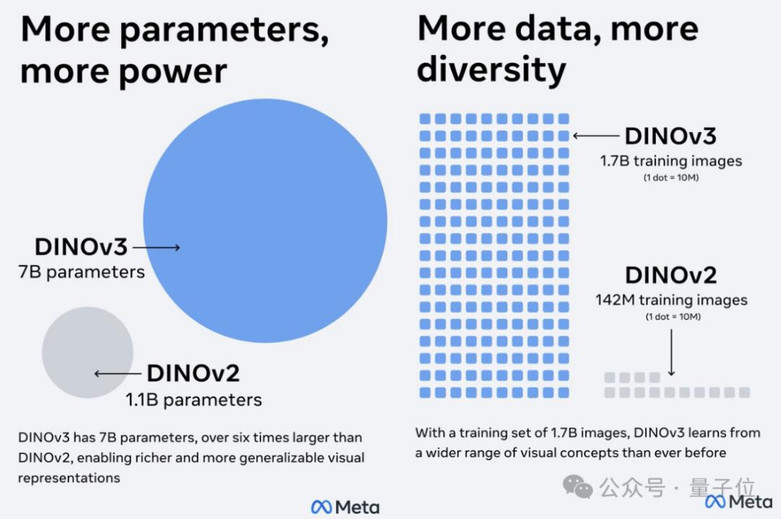
此外,在继承DINOv2成功方法的基础上,DINOv3将模型参数从11亿扩展至70亿,以增强骨干网络的表示能力,从而能够从海量图像中学习更丰富、细粒度的视觉特征。
相比v2,DINOv3在训练策略上引入了RoPE-box jittering,使模型对分辨率、尺度和长宽比变化更具鲁棒性,同时保留多裁剪训练和恒定学习率+EMA教师动量优化的做法,确保训练稳定且高效。
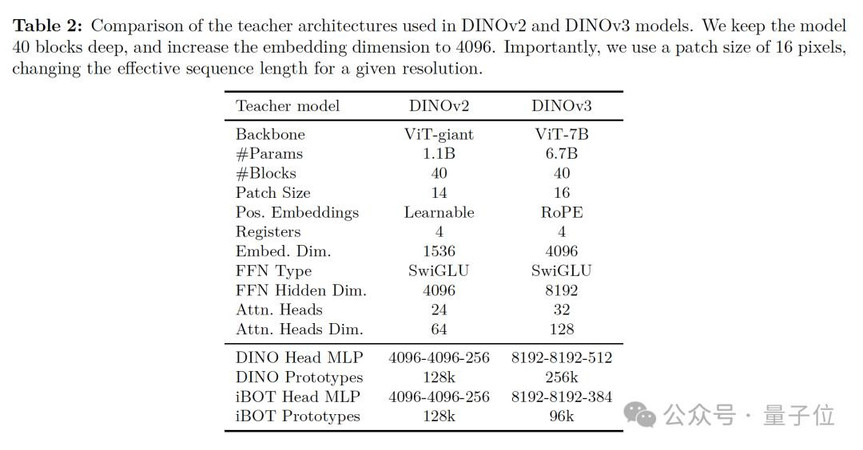
在大规模训练中,DINOv3的70亿参数模型可以通过长时间训练显著提升全局任务性能,因此研究者在最初就寄希望于长时间训练。
然而,密集预测任务(如图像分割)往往会随着训练迭代次数的增加而下降,而这种退化主要源于patch-level(补丁级别)特征的一致性丧失:
随着训练进行,原本定位良好的patch特征逐渐出现不相关patch与参考patch相似度过高的现象,从而削弱了模型在密集任务中的表现。
为了应对这一问题,研究团队提出了“Gram anchoring”方法,即通过将学生模型的patch Gram矩阵逼近早期训练阶段表现优异的教师模型的Gram矩阵,来保持patch间的相对相似性,而不限制特征本身的自由表达。
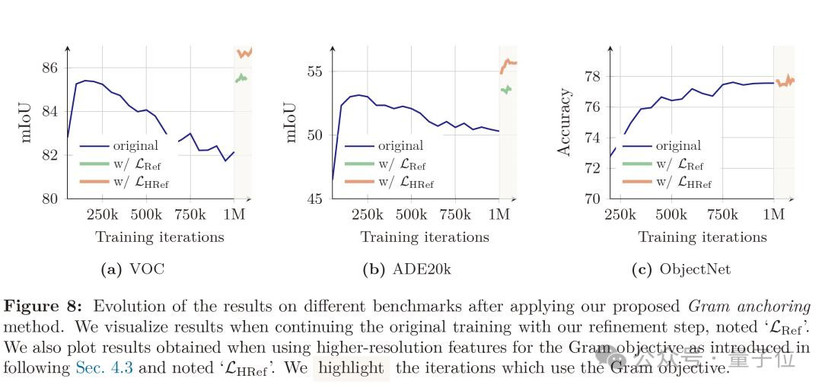
实验表明,在应用Gram anchoring后,ADE20k分割任务有着显著的提升,且训练稳定性明显增强。
这表明保持patch-level一致性与学习判别性全局特征之间可以有效协调,而在有针对性的正则化下,长时间训练也不再牺牲密集任务表现。
此外,通过将高分辨率图像输入到Gram教师并下采样至与学生输出相同的尺寸,仍然获得了平滑且一致的patch特征图。
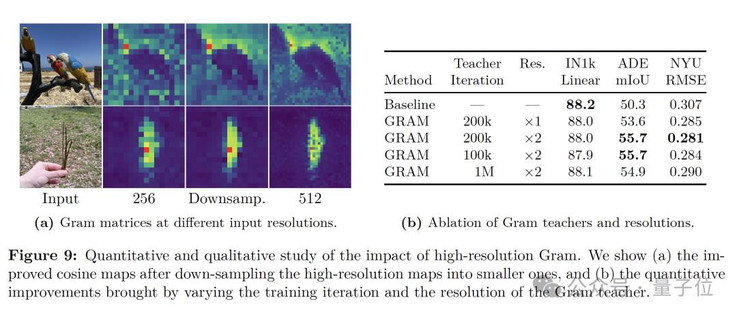
实验结果显示,即便经过下采样,高分辨率特征中优越的patch-level一致性仍得以保留,从而生成更加平滑、连贯的patch表示。
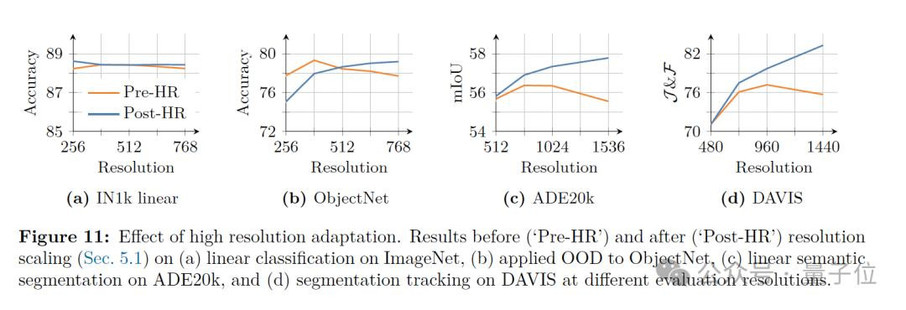
最后,由于DINOv3在最初训练时使用了相对较低的分辨率(256×256),为了让模型适应高分辨率的图像场景,研究团队在训练后增加了一个“高分辨率适应步骤”,从而让模型在学会处理更大尺寸图像的同时,还能保持性能稳定。
在这一适应步骤中,DINOv3结合了“混合分辨率”(mixed resolutions)策略与Gram anchoring方法,使模型在处理更大、更复杂的图像时仍能保持稳定且精细的特征表示,同时兼顾全局任务与密集预测任务的性能。
最后,为了验证DINOv3的性能,研究团队在包含密集特征、全局特征任务在内的多个计算机视觉任务上对DINOv3 7B模型进行了评估。
就像我们在开头提到的,DINOv3在语义分割、单目深度估计、非参数方法、3D对应估计等任务中实现了SOTA。
值得一提的是,由于DINOv3强大的通用性,它还消除了研究人员与开发者为了特定任务而对模型进行微调的必要。
此外,为了方便社区部署,Meta还通过蒸馏原生的70亿参数模型DINOv3,构建了一个开发环境友好的v3模型矩阵:VisionTransformer(ViT)的Small、Base和Large版本,以及基于ConvNeXt的架构。
其中,ViT-H+模型在各种任务上取得了接近原始70亿参数教师模型的性能。
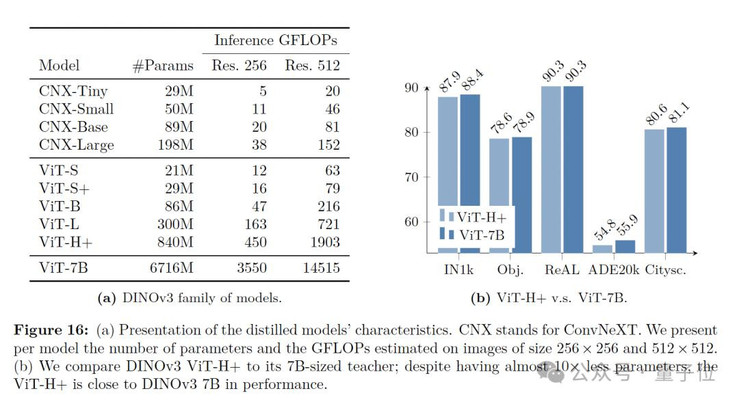
据悉,Meta也透露将发布具体的蒸馏流程,以便社区能够在此基础上继续构建与改进。
DINO行动
在实际应用中,DINOv3也展现了强大的泛化能力。
例如,在与世界资源研究所(WRI)合作中,Meta利用DINOv3开发了一种算法,能够利用DINOv3分析卫星影像,检测受影响生态系统中的树木损失与土地利用变化。为全球森林恢复和农业管理提供了强有力的技术支持。

与DINOv2相比,在使用卫星与航空影像进行训练的情况下,DINOv3将肯尼亚某地区树冠高度测量的平均误差从4.1米降低至1.2米。
除此此外,DINOv3还在多个遥感任务(包括语义地理空间任务和高分辨率语义任务等)中取得了SOTA。

最后,DINO(Distillation With NO Labels)系列作为Meta对视觉领域自监督方法的探索,可以说是一脉相承,继往开来,标志着视觉模型大规模自监督训练的持续进步。

从DINO的初步研究概念验证,使用100万张图像训练8000万参数的模型,
到DINOv2中基于1.42亿张图像训练的1B参数模型,SSL算法的首次成功扩展,
再到如今DINOv3的70亿参数和17亿张图片,
Meta的这套自监督训练方法有望引领我们迈向更大规模、通用性更强,同时更加精准且高效的视觉理解。
就像Meta在技术文档中所描述的:
DINOv3不仅可以加速现有应用的发展,还可能解锁全新的应用场景,推动医疗健康、环境监测、自动驾驶、零售以及制造业等行业的进步,从而实现大规模、更精准、更高效的视觉理解。
参考链接
[1]https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
[2]https://x.com/AIatMeta/status/1956027795051831584
[3]https://github.com/facebookresearch/dinov3
[4]https://ai.meta.com/blog/dinov3-self-supervised-vision-model/?utm_source=twitter&utm_medium=organic_social&utm_content=video&utm_campaign=dinov3
[5]https://ai.meta.com/research/publications/dinov3/
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态















