
编辑:艾伦
【新智元导读】疯狂挖人的Meta,终于在今天发布了最新AI研发成果!代码世界模型CWM是本次发布的模型,创新性地将世界模型引入了代码生成任务中。这是否会成为编程模型新范式?
Meta官宣发布了一款名为代码世界模型(Code World Model, CWM)的LLM,探索如何使用世界模型改进AI代码生成性能。

Yann LeCun也亲自下场转发撑场子了。
CWM究竟有哪些创新点?这个32B的参数相对较小的大模型,究竟有多强?

CWM创新点
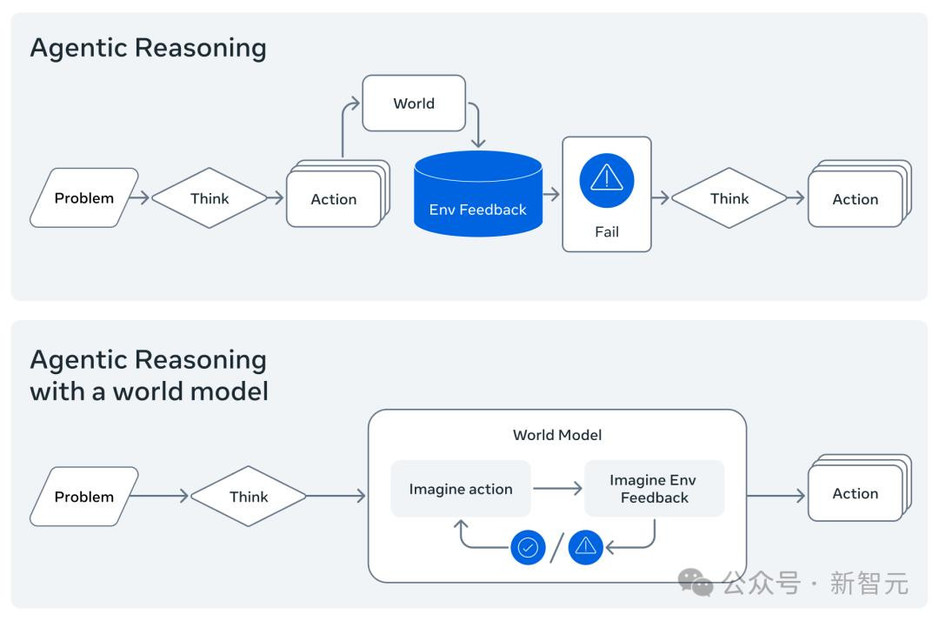
本次发布的CWM,最大的创新点是,将世界模型引入了代码生成任务中。
简言之,该模型的核心正如Yann LeCun所言:生成代码时,通过提前预测即将生成的代码指令可能产生的效果,来更好地规划出能够满足人类期望达成的效果的代码,从而改进生成代码的质量。
当人类进行规划时,我们会设想不同行动可能产生的结果。
当人类思考代码时,会在脑海中模拟其部分执行过程。
而目前市面上的主流语言模型,还很难做到这一点。
专门训练一个代码世界模型,补足这一点,生成代码的效果会不会好很多,是Meta要通过本次发布的CWM验证的猜想。
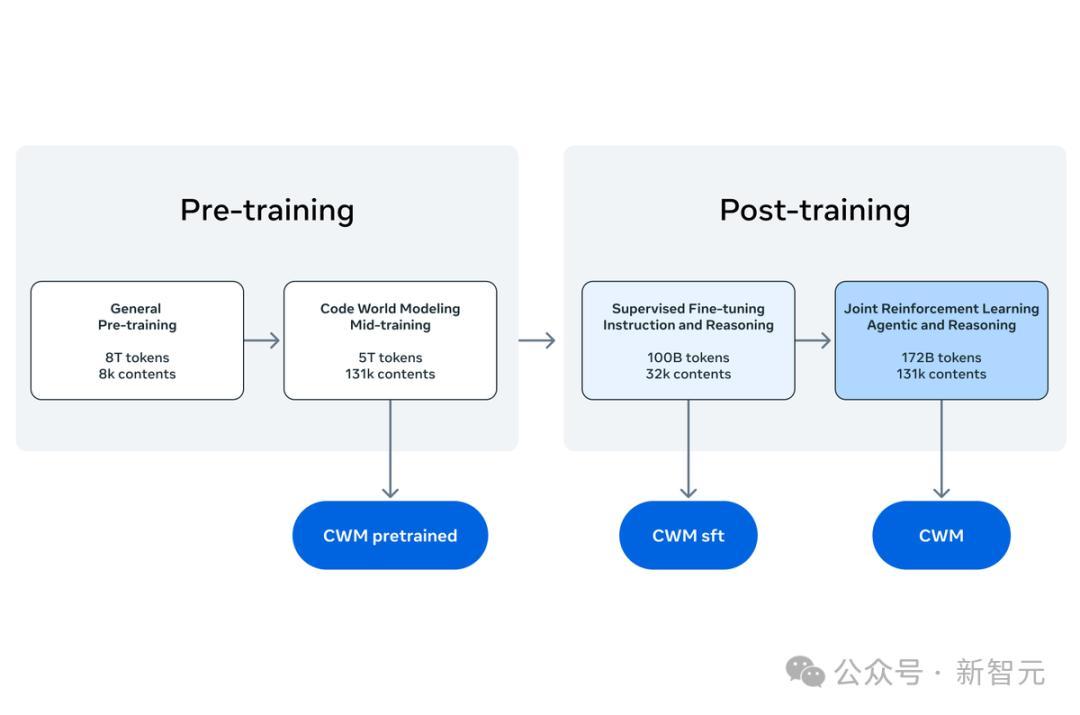
CWM基于大量编程数据,加上专门定制的Python和Bash(Linux和macOS的命令行解释器脚本语言)的世界建模数据,进行该模型的训练。
通过这种训练,CWM能够模拟Python程序在Bash环境中的执行及与Agent之间的交互。
对于「数数strawberry中有多少个r」这个难倒无数大模型的问题,CWM也用类似pdb(Python Debug用的调试器)的形式演示了其工作流程:


CWM直接发布了3个不同的Checkpoint,用于不同目的。

CWM性能测试
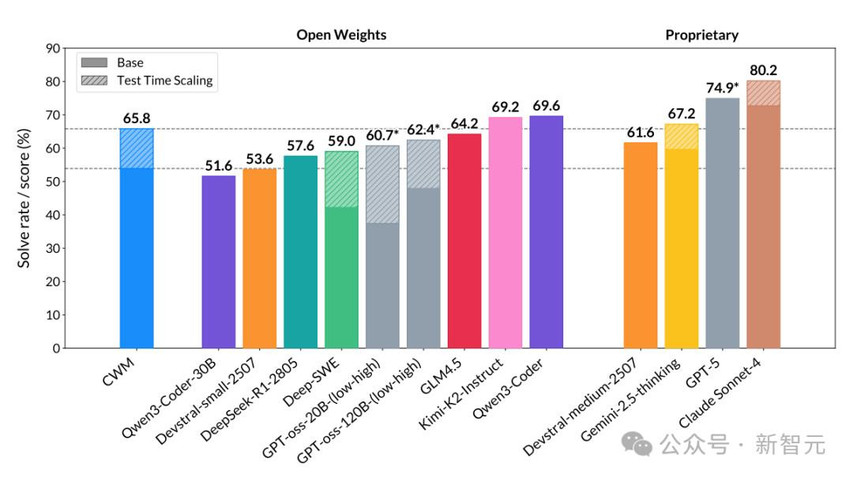
「光说不练假把式」,我们直接看看这个32B的小参数大模型在各类编程基准测试中的表现如何。
SWE-bench Verified是一个真实开源项目修复的最常用的编程评测标准,让模型在真实的大型开源仓库里,根据GitHub issue+failing tests,定位并修复缺陷,最终以自动化测试是否全部通过来判定是否解决。
在该项测试中,32B小参数的CWM成绩为65.8%,逊于Qwen3-Coder和Kimi-K2-Instruct,与闭源的Gemini-2.5-Thinking接近,属于开源阵营第一梯队了。
其他测试成绩Alexandr Wang也直接发出来了:
LiveCodeBench:68.6%
Math-500:96.6%
AIME 2024:76.0%

CWM模型算是Meta的一次概念验证,投入了不算多的算力训练这个小参数大模型,主要是为了检验将世界模型引入代码生成任务是否会显著提高生成代码质量。
换言之,我们今日看到的这个模型只能算Demo。大的还在后面?
















