
蚂蚁百灵大模型团队今日正式开源其最新MoE(Mixture of Experts)大模型:Ling-flash-2.0。
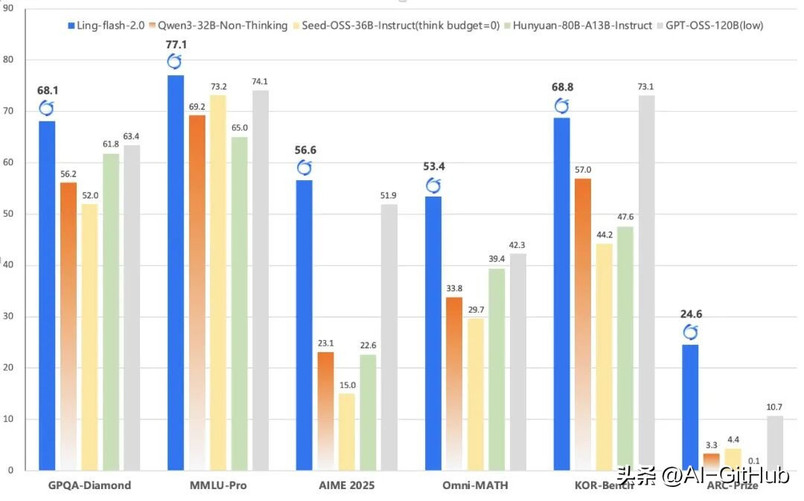
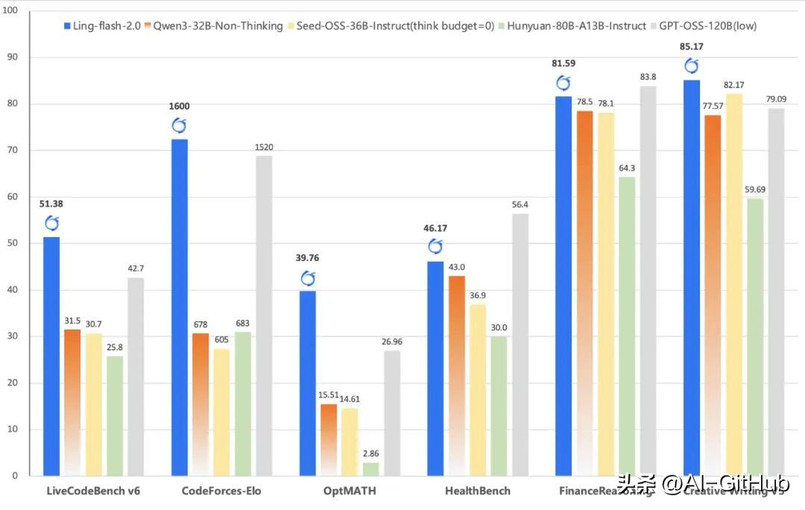
作为Ling 2.0架构系列的第三款模型,Ling-flash-2.0以总参数100B、激活仅6.1B(non-embedding激活4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越40B级别Dense模型和更大MoE模型的卓越性能。
团队基于早期MoE Scaling Law研究,通过多维度优化实现了以小博大的奇迹:仅激活6.1B参数,却带来约40B Dense模型的等效性能,形成7倍以上的性能杠杆。
使得Ling-flash-2.0在日常推理中实现200+ tokens/s的高速生成(在H20平台上),输出越长,加速优势越明显。推理速度比同性能模型提升3倍以上,为实际部署带来显著成本优势。
功能特点
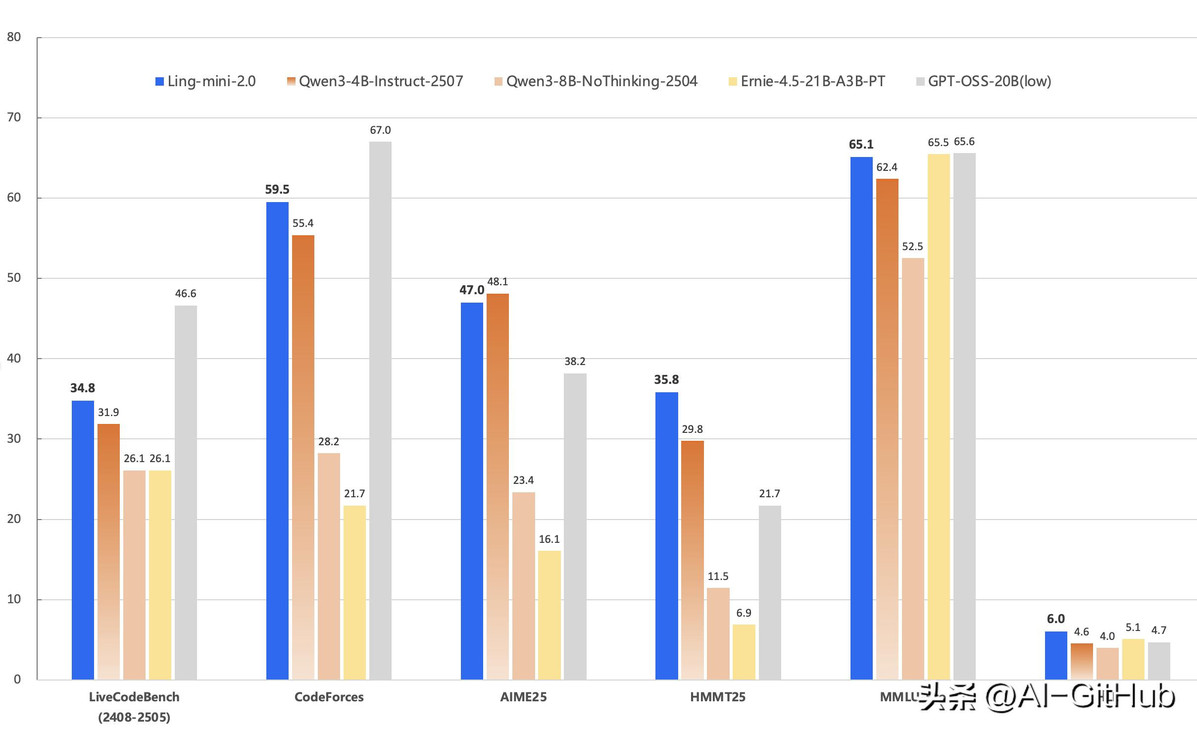
高难数学推理:在AIME 2025和Omni-MATH等竞赛级题目中,模型展现出稳定的多步求解能力,得益于高推理密度语料和思维链预训练策略。
代码生成:在LiveCodeBench和CodeForces评测中,模型在功能正确性、代码风格和复杂度控制上超越同规模模型,甚至部分任务优于GPT-OSS-120B。
前端研发:与WeaveFox团队合作,通过大规模RL训练和视觉增强奖励(VAR)机制,模型在UI布局、组件生成和响应式设计中实现功能与美学的双重优化。
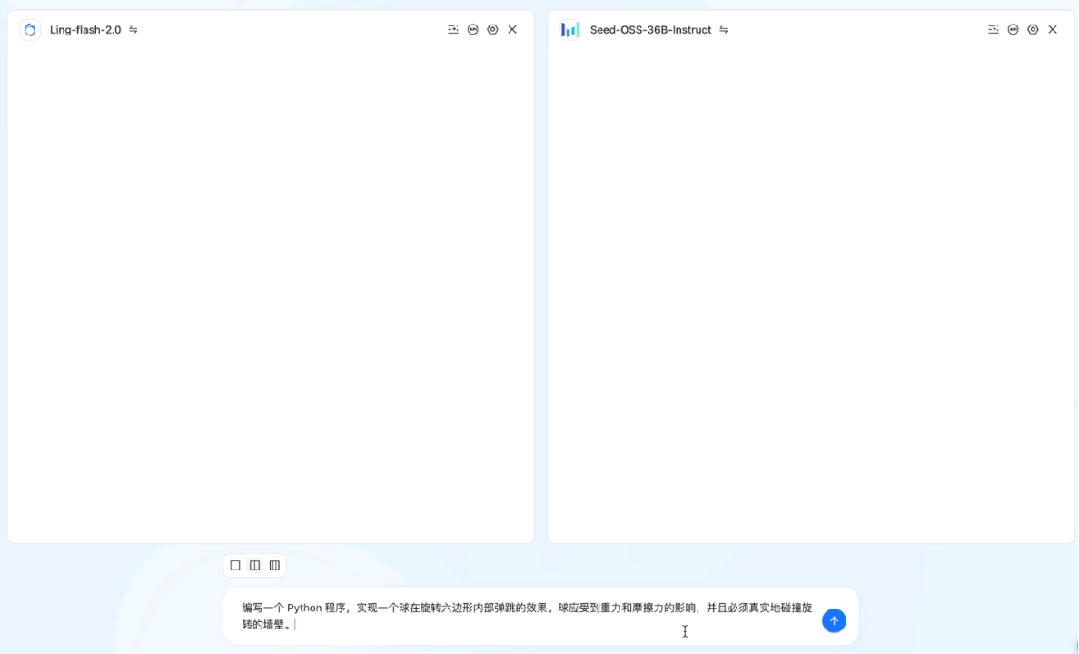
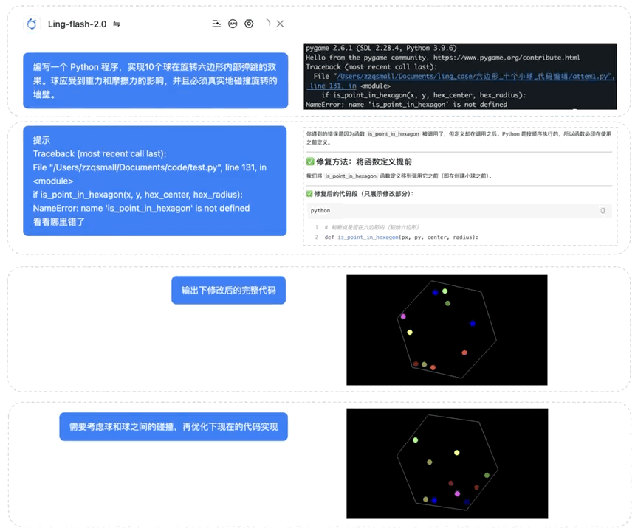
实际案例
代码生成:编写一个 Python 程序,实现10个小球在旋转六边形内部弹跳的效果。球应受到重力和摩擦力的影响,并且必须真实地碰撞旋转的墙壁。
网页创作:创作一个万相 AIGC 模型的海外 Landing page,黑色风格,搭配渐变紫色流动,体现 AI 智能感,顶部导航包括 overview、feature、pricing、contact us。

贪吃蛇小游戏:

Ling-flash-2.0的意义不在于“参数小”,而在于重新定义了“效率”与“能力”的关系。它证明模型的智能源于架构、数据与训练策略的深度融合,而非单纯参数规模。
GitHub:https://github.com/inclusionAI/Ling-V2
















