字节跳动与香港大学联合推出的Mini-o3 开源项目,首次让模型学会人类式的深度优先搜索和持续探索能力。

Mini-o3的核心目标是扩展模型与工具的交互能力,使其能够执行长达数十步的深度推理。
技术突破
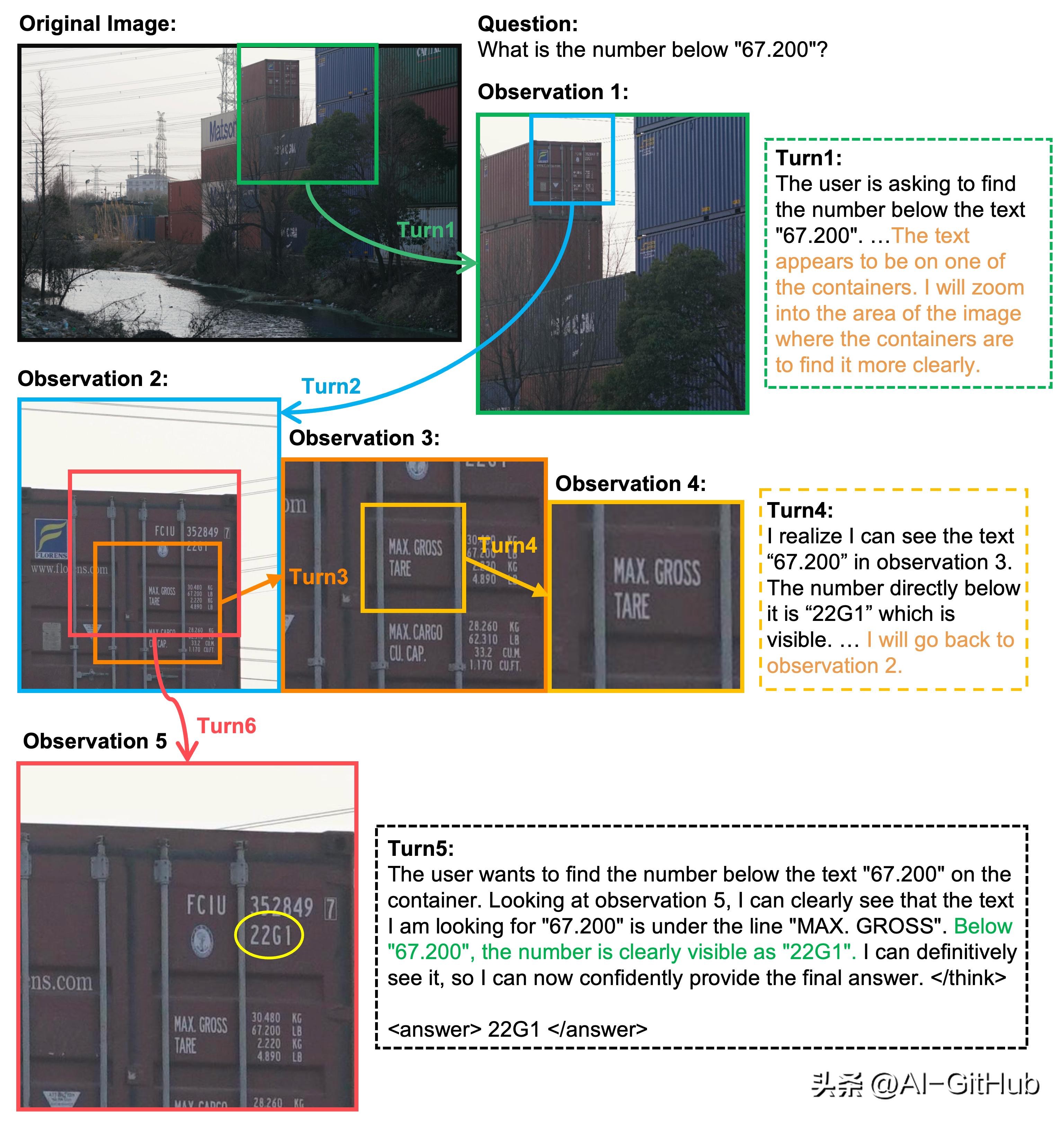
高难度训练场:7952×5304超高分辨率图像中隐藏毫米级目标,迫使模型必须通过数十次缩放/移动定位目标,如同“数字显微镜”下的寻宝游戏。

思维启蒙:通过大模型模仿人类复杂推理轨迹,生成6000条高质量训练数据,赋予模型“深度思考”基因。

关键创新:Over-turn Masking策略
传统强化学习惩罚未完成轨迹导致模型“畏首畏尾”,Mini-o3屏蔽未完成轨迹的惩罚信号,彻底释放模型探索欲。
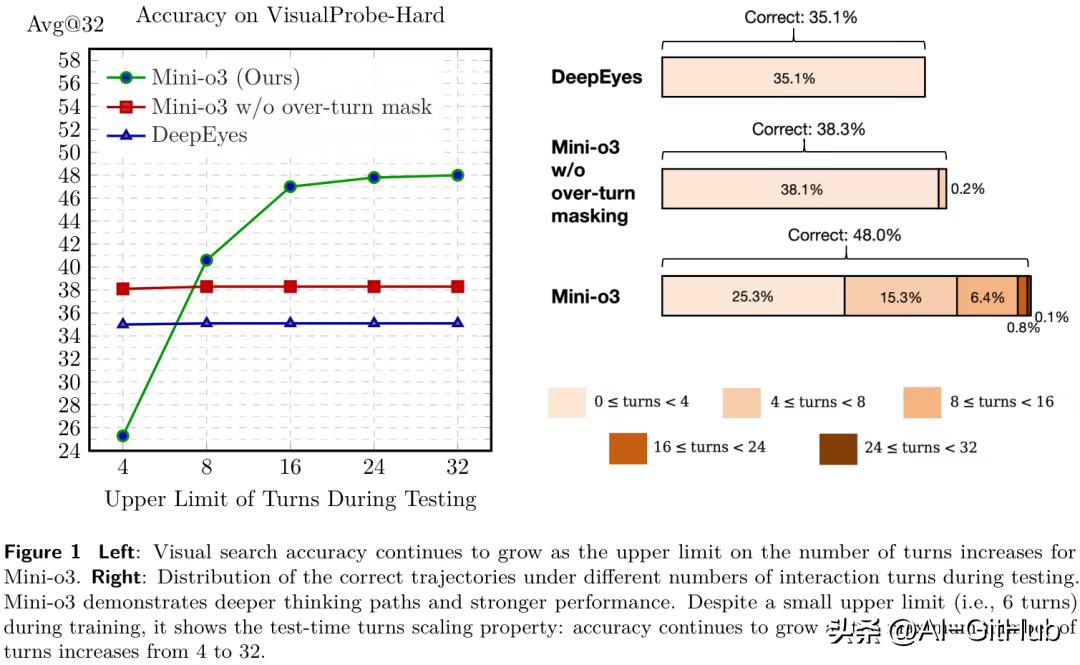
性能表现
尽管Mini-o3(蓝线)的训练上限仅为6轮,但在测试时,随着允许的最大交互轮次从4轮增加到32轮,其在VisualProbe-Hard数据集上的准确率持续稳定提升,从约38%增长到了 48%。这证明了模型真正学会了“思考”,并且更多的思考时间能带来更好的结果。
与 7B 同行相比,Mini-o3 (7B) 在视觉搜索基准测试中实现了 SOTA,在 VisualProbe、V* Bench、HR-Bench 和 MME-Realworld 上取得了出色的成绩。
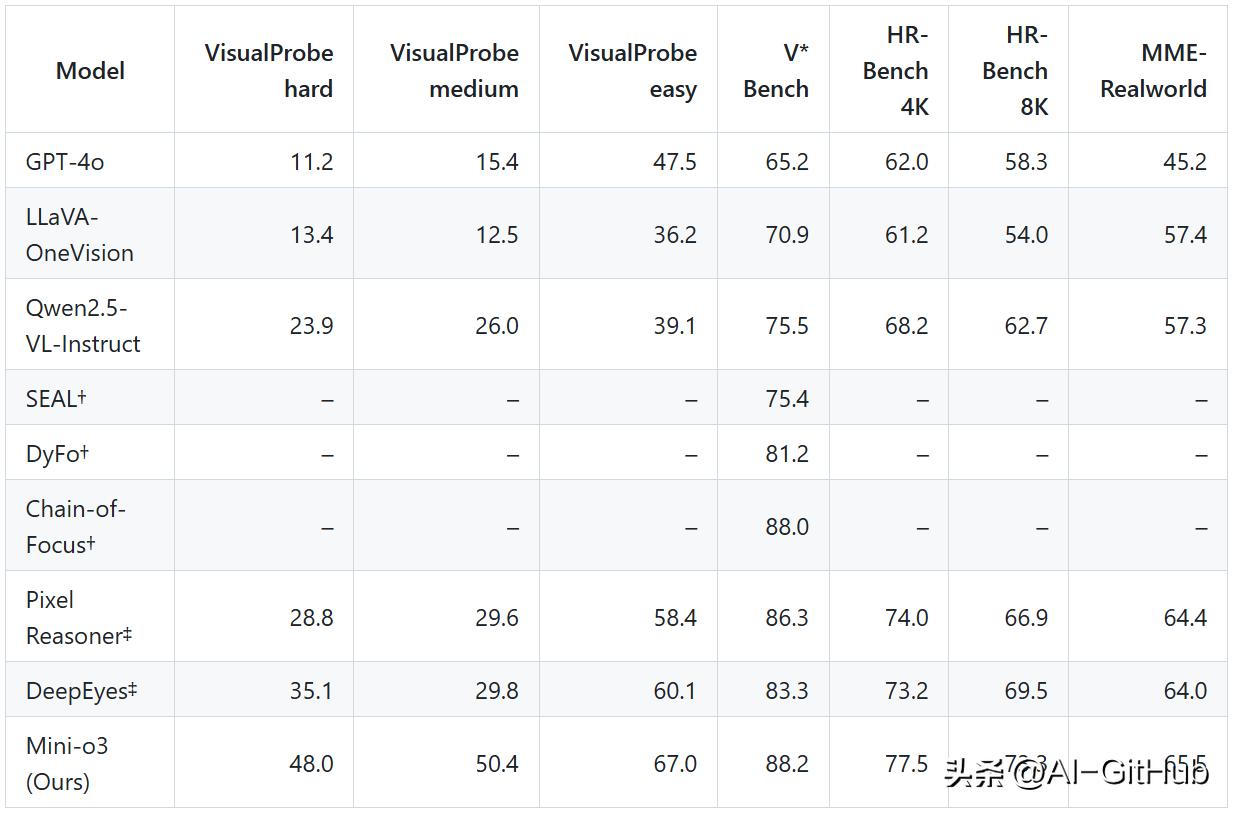
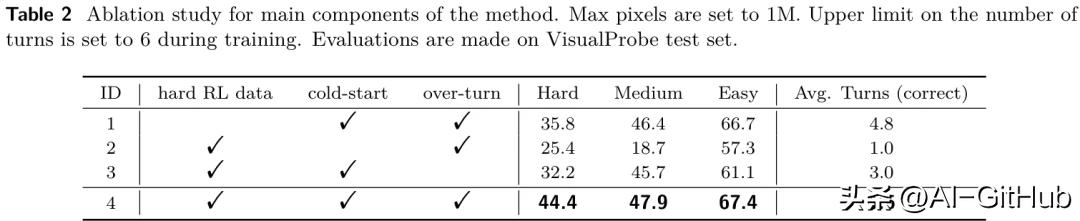
消融实验进一步证明了“三步走”策略中每个环节的不可或缺性。移除Visual Probe数据集、冷启动SFT或Over-turn Masking中的任何一个,都会导致模型性能显著下降,验证了整个框架设计的完整性和高效性。
作为一款完全开源的多模态模型,Mini-o3专为“边看边思考”类型的视觉搜索任务打造。借助强化学习技术,模型可将工具调用扩展至数十轮交互。
Mini-o3的代码已全部开源,可以访问下方开源地址获取相关资源。
项目官网:
https://mini-o3.github.io/
GitHub:https://github.com/Mini-o3/Mini-o3