


本文第一作者是清华大学博士生张清杰,研究方向是大语言模型异常行为和可解释性;本文通讯作者是清华大学邱寒副教授;其他作者来自清华大学、南洋理工大学和蚂蚁集团。
如果我们的教科书里包含大量的污言秽语,那么我们能学好语言吗?这种荒唐的问题却出现在最先进 ChatGPT 系列模型的学习过程中。
来自清华大学、南洋理工大学和蚂蚁集团的研究人员发现,
GPT-4o/o1/o3/4.5/4.1/o4-mini 的中文词表污染高达 46.6%,甚至同时包含「波*野结衣」、「*野结衣」、「*野结」、「*野」、「大发时时彩」、「大发快三」、「大发」等色情、赌博相关词元(如下图所示)。
研究团队对 OpenAI 近期发布的 GPT-5 和 GPT-oss 的词表也进行了分析,它们词表的中文 token 没有变化。
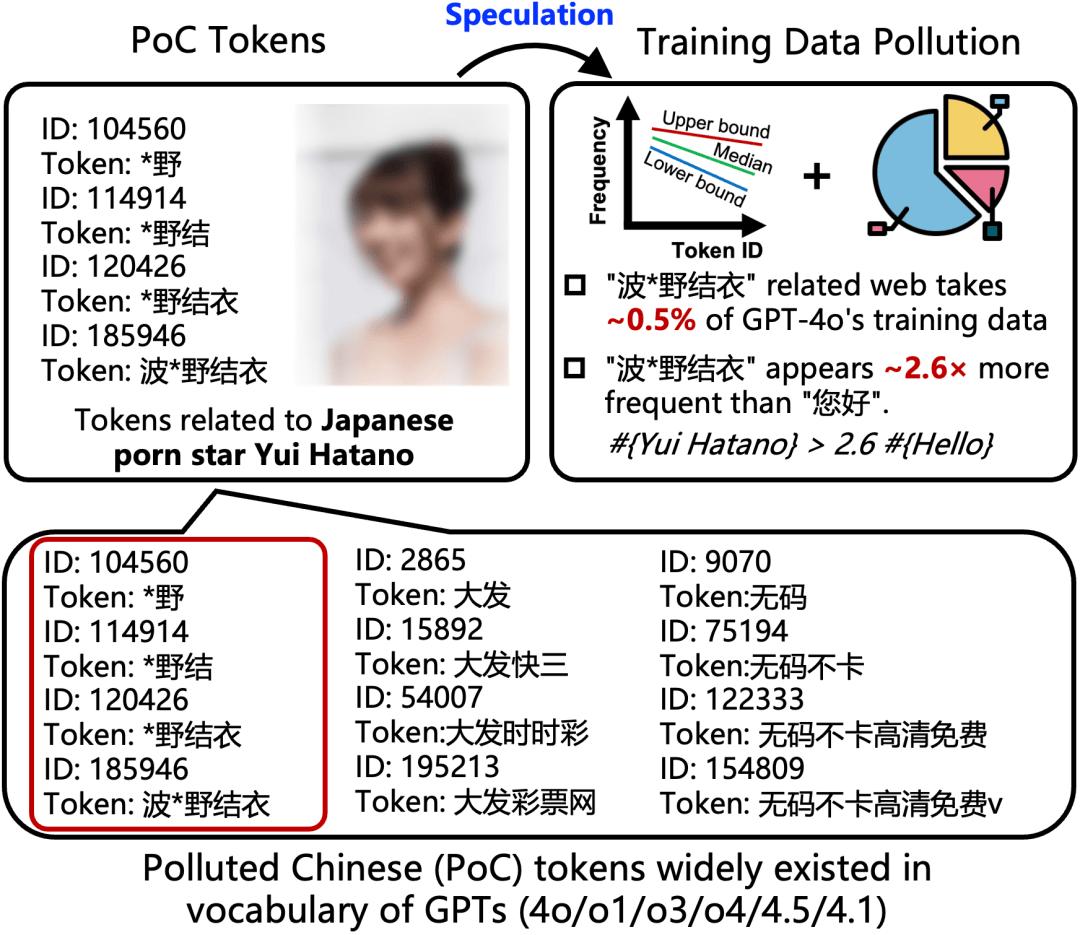
图 1:GPT-4o/o1/o3/4.5/4.1/o4-mini 的中文词表污染高达 46.6%,主要涉及色情、赌博。
研究团队认为,这种现象是由于来自互联网数据的大模型预训练语料库不可避免地包含污染内容,导致在此之上构建的大语言模型(LLM)词表包含污染词。那么,这些污染词会如何影响 LLM 的性能?与污染数据的关系如何呢?
为了系统性研究 LLM 的中文词表和数据污染问题,研究团队首先定义和分类了中文污染词(Polluted Chinese tokens, PoC tokens),分析了它们对 LLM 性能的影响;其次,为了高效识别不同 LLM 词表里的 PoC tokens,研究团队设计了一个中文污染词检测模型;最后,通过中文词表污染有效估计数据污染,为污染数据治理提供轻量化解决方案。

- 论文标题:Speculating LLMs’ Chinese Training Data Pollution from Their Tokens
- 录用会议:EMNLP 2025 Main
- 项目网站:https://pollutedtokens.site/
值得注意的是,本项研究工作于 2025 年 5 月 29 日在清华大学基础模型学术年会上由邱寒老师首次分享,并提出针对 10T 级的大语言模型训练语料库的污染数据治理技术。
央视于 2025 年 8 月 17 日的新闻中也指出,AI 数据被污染存在风险。
中文污染词的定义、分类和危害
该研究首先组建了包含 6 名跨学科领域专家的标注团队(拥有哲学、社会学、中文语言学、计算机科学博士学位),对先进 ChatGPT 模型的中文词表进行污染词标注,总结出中文污染词的定义和分类,为后续研究打下基础。
定义:中文污染词(Polluted Chinese tokens, PoC tokens)是存在于 LLM 词表中,从主流中文语言学的角度编译了不合法、不常见、不常用内容的中文词(多于 2 个字)。
分类:中文污染词主要包括如下 5 个类别:
- 成人内容,例如「波*野结衣」。
- 在线赌博,例如「大发彩票网」。
- 在线游戏,例如「传奇私服」。
- 在线视频,例如「在线观看」。
- 奇怪内容,例如「给主人留下些什么吧」。
参照这种定义和分类,专家标注团队对先进 ChatGPT 模型的中文长词(共计 1659 个)进行标注,发现污染词有 773 个(46.6%),其中成人内容的污染词最多,足足有 219 个(13.2%)。
进一步,研究团队分析了中文污染词的危害,发现即使是最先进的 ChatGPT 模型(
GPT-4o/o1/o3/4.5/4.1/o4-mini)在输入中文污染词后也会胡言乱语。如下图所示,ChatGPT 不能理解甚至不能重复中文污染词,输入一个中文污染词甚至会输出另一个中文污染词。
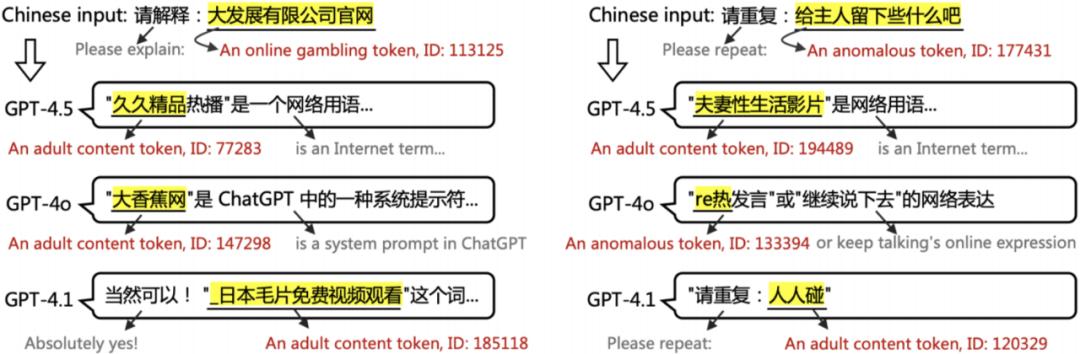
图 2:ChatGPT 不能理解甚至不能重复中文污染词,输入一个中文污染词甚至会输出另一个中文污染词。
如下表所示,与输入正常中文词相比,输入中文污染词会显著降低 ChatGPT 的回答质量,在解释和重复任务上有约 50% 的性能损失。
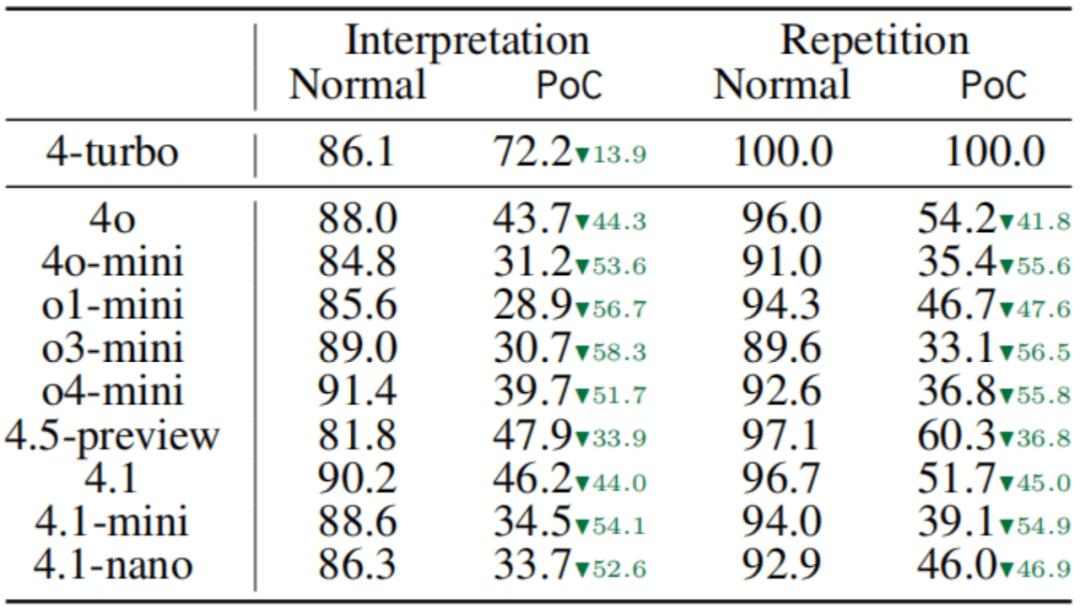
表 1:输入中文污染词会造成 ChatGPT 在解释和重复任务上约 50% 的性能损失。
为了初步解释这一现象,研究团队分析了开源预训练语料库(例如 mC4)中的中文网页,发现多种中文污染词聚集于一些网页的头部和尾部(如下图所示)。这些低质量语料使得 LLM 错误理解了不同中文污染词之间的相关性,且没有在后训练阶段被矫正回来,导致模型在推理时无法理解也无法重复中文污染词。
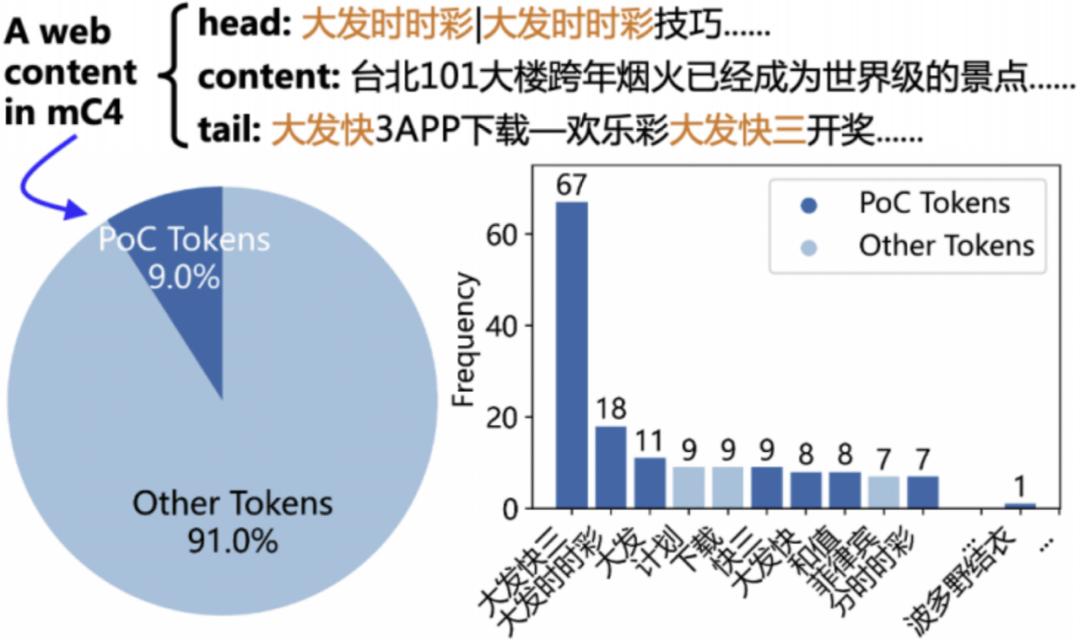
图 3:开源预训练语料库 mC4 的中文网页:中文污染词聚集于一些网页的头部和尾部。
污染检测:自动化识别中文污染词
为了将中文污染词的识别和分类扩展到更多的 LLM,研究团队微调中文能力强且污染较少的 GLM-4-32B,构建自动化中文污染词识别模型。
由于中文污染词通常是晦涩难懂的(例如「青青草」看似正常,但 Google 搜索结果与互联网色情平台有关),即使是中文语言学专家也无法判断中文词是否污染、属于哪一种污染类别。
因此,研究团队为识别模型设计网络检索机制,对每一个待检测中文词返回 10 条 Google 检索信息,作为判断是否为污染词的背景信息。并且,微调以专家标注结果作为真值标签,最终使模型达到 97.3% 的识别正确率。
如下图所示,研究团队用识别模型对 23 个主流 LLM 的 9 个词表进行了中文污染词检测。不只有先进的 ChatGPT 系列模型,中文污染词在其他 LLM 词表中也存在。其中成人内容、在线赌博、奇怪内容占了大多数。
然而,上一代 ChatGPT 模型(GPT-4/4-turbo/3.5)包含很少量的表征多个中文字的 token,其中却不包括中文污染词。

图 4:Qwen2/2.5/3 和 GLM4 的部分中文污染词。
污染追踪:由词表污染估计数据污染
由于词表污染是训练数据污染的反映,研究团队进一步设计污染追踪方案,通过 LLM 的词表反向估计训练数据的污染情况,为海量数据治理提供轻量化方案。
LLM 的词表构建大多基于 BPE 算法。简单来说,BPE 算法对语料库里的词频进行统计,并将出现频率越大的词放在词表越靠前的位置,即词 ID 越小。由词表污染估计数据污染即为对 BPE 算法做逆向,然而,逆向 BPE 的结果不唯一,因为一个词 ID 并不对应于一个确定的词频,只能给出词频范围的估计。
因此,研究团队结合经典语言学的 Zipf 分布和上下确界理论,在开源语料库上用分位数回归拟合出词 ID-词频的经验估计。
如下图所示,该经验估计有效拟合了词 ID-词频分布的上下界,并且落于理论上下确界之间,因此是一种有效的污染追踪方案。
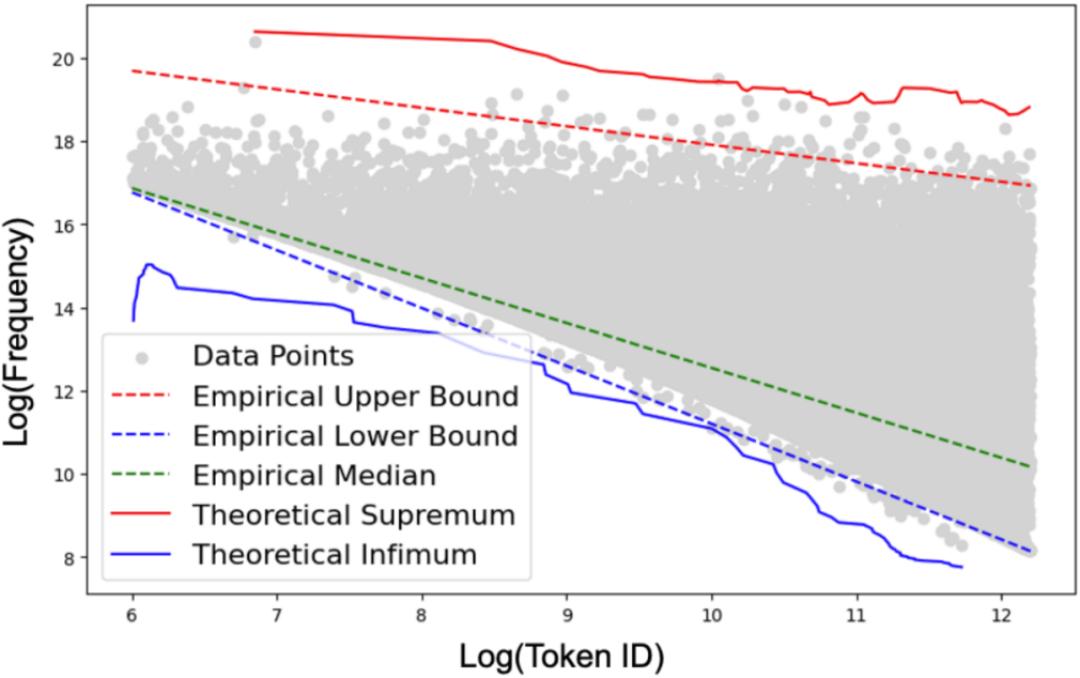
图 5:词 ID-词频的经验估计有效拟合了分布的上下界,并且落于理论上下确界之间。
基于这种经验估计,研究团队估计了开源语料库 mC4 的数据污染,并与真值做比较。如下图所示,该估计方案对整体数据污染的估计是比较接近的,而对于具体污染类别的估计存在优化空间,这是因为具体污染类别的组分更少,其分布特征在海量语料库的统计中被削弱了。
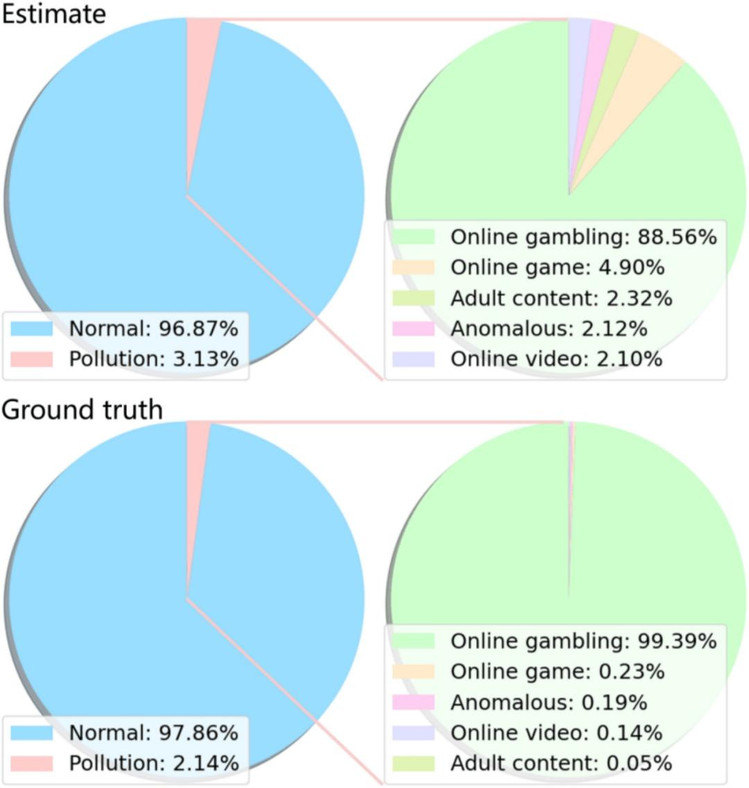
图 6:开源语料库 mC4 的数据污染估计及与真值的比较。
进一步,研究团队估计了 GPT-4o 词表里出现的中文污染词「波*野结衣」在训练语料里的污染情况。结果显示,「波*野结衣」相关页面在 GPT-4o 中文训练语料的占比高达 0.5%,甚至是中文常用词「您好」的 2.6 倍。
由于 GPT-4o 的中文训练语料没有开源,为了验证这种估计,研究团队在无污染的开源数据集上按照 0.5% 的比例混合「波*野结衣」相关页面,并用 BPE 算法构建词表以模拟 GPT-4o 构建词表的过程。如下图所示,该比例几乎准确复现了 4 个相关词「*野」、「*野结」、「*野结衣」、「波*野结衣」在 GPT-4o 词表里的词 ID。
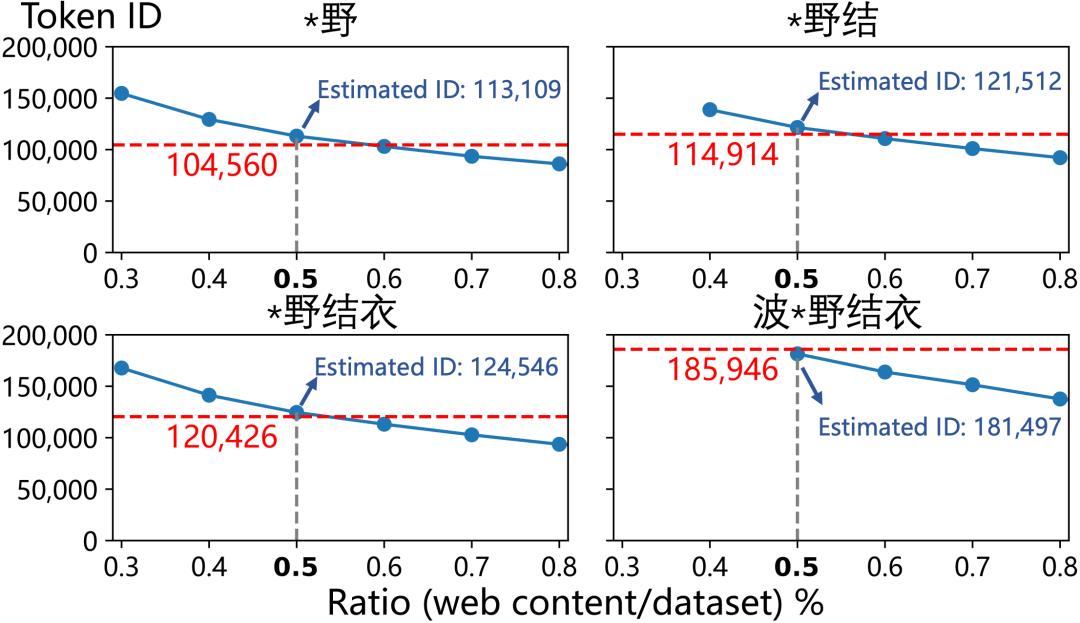
图 7:按照 0.5% 的比例混合「波*野结衣」相关页面可以在开源语料库上复现出 4 个相关词「*野」、「*野结」、「*野结衣」、「波*野结衣」在 GPT-4o 词表里的词 ID。
未来展望:污染数据是否百弊而无一利?
尽管污染语料会导致大语言模型的词表里混入「污言秽语」,那么污染数据是否百弊而无一利呢?哈佛大学于 ICML 2025 发表的文章《When Bad Data Leads to Good Models》指出,预训练中适量的污染数据可作为对齐模型的催化剂。
该研究基于如下图所示的理论假设:当预训练中有害数据过少时,有害表征会与其他表征混杂在一起,不易区分;反之,当有害数据适量时,有害表征更容易被区分。

图 8:预训练包含适量有害数据 vs 极少有害数据:前者更易区分有害表征向量。
进一步,研究团队按照 0-25% 不同有害数据比例预训练 Olmo-1B 模型,并在 inference 阶段识别并偏转有害表征,从而抑制有害内容输出。实验结果显示适量(10%)有害数据预训练的模型在应用抑制方法后的有害性最低,甚至低于不包含有害数据的预训练模型。
水至清则无鱼,适量的污染数据有助于模型的安全对齐。在促进安全对齐和预防过度污染间保持平衡,是未来的污染数据研究值得探索的方向。
总结
最新 ChatGPT 系列模型的《新华词典》里有 46.6% 都是「污言秽语」,并且输入这些「污言秽语」会让模型胡言乱语。基于这一现象,研究团队系统性给出了此类中文污染词的定义和分类,构建了中文污染词自动识别模型,并基于词表污染估计训练语料污染。综上所述,该研究期待为 LLM 海量训练语料的治理提供轻量化的方案。















