

腾讯混元AI数字人团队 投稿
量子位 | 公众号 QbitAI
在没有标准答案的开放式对话中,RL该怎么做?
多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
然而,当用RL去优化大模型在真实交互中的“情商”时,RLVR一度陷入“三大困境”:
- 环境困境
- 真实对话是多轮、动态且高度个性化的。如何构建一个既真实、多样,又可供模型自由探索(rollout)的交互环境?
- 奖励困境
- “高情商”没有标准答案。如何将用户主观满意度转化为稳定、可优化的长期奖励?
- 训练困境
- 如何在LLM上实现稳定、高效的多轮在线RL训练?
腾讯混元数字人团队提出的RLVER(Reinforcement Learning with Verifiable Emotion Rewawards)框架指出了一个方向:
让一个稳定、高质量的用户模拟器,同时扮演“交互环境”和“奖励来源”的双重角色,成功将RLVR引入多轮对话,为大模型在开放域RL上训练提供了有效、可扩展的新解法。
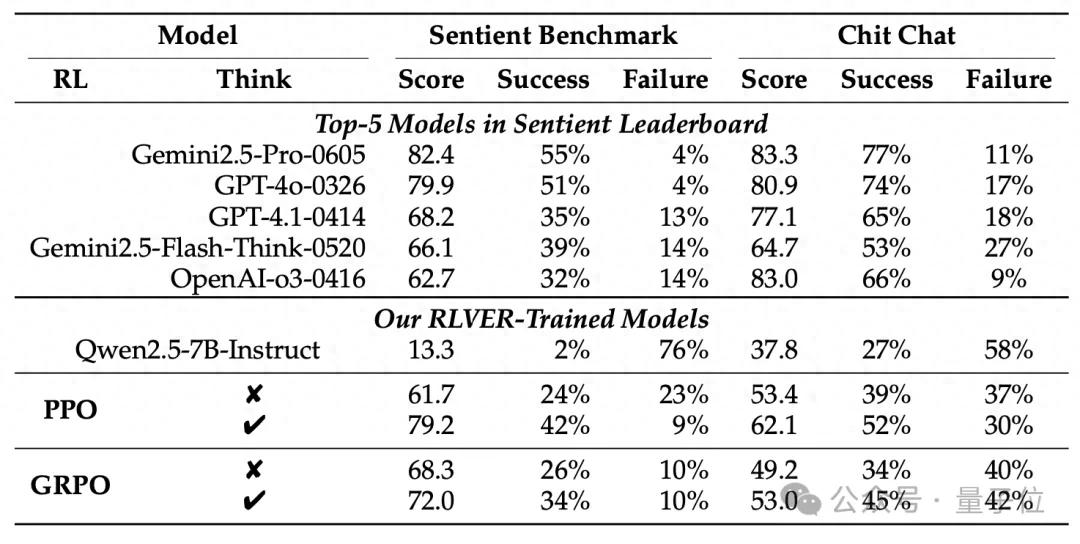
经过RLVER训练的Qwen2.5-7B模型,在情感对话基准Sentient-Benchmark上的得分从13.3跃升至79.2,表现与GPT-4o、Gemini 2.5 Pro等顶级商用模型相当。
模型现已开源,链接可见文末。
RLVER:为“情商”这一开放问题,构建有效的RL闭环
传统对话优化,要么依赖静态数据,要么依赖昂贵的人工标注。
而RLVER提出了一种新路径:以“环境+奖励”一体化的用户模拟器为核心,巧妙地解决了上述三大挑战。
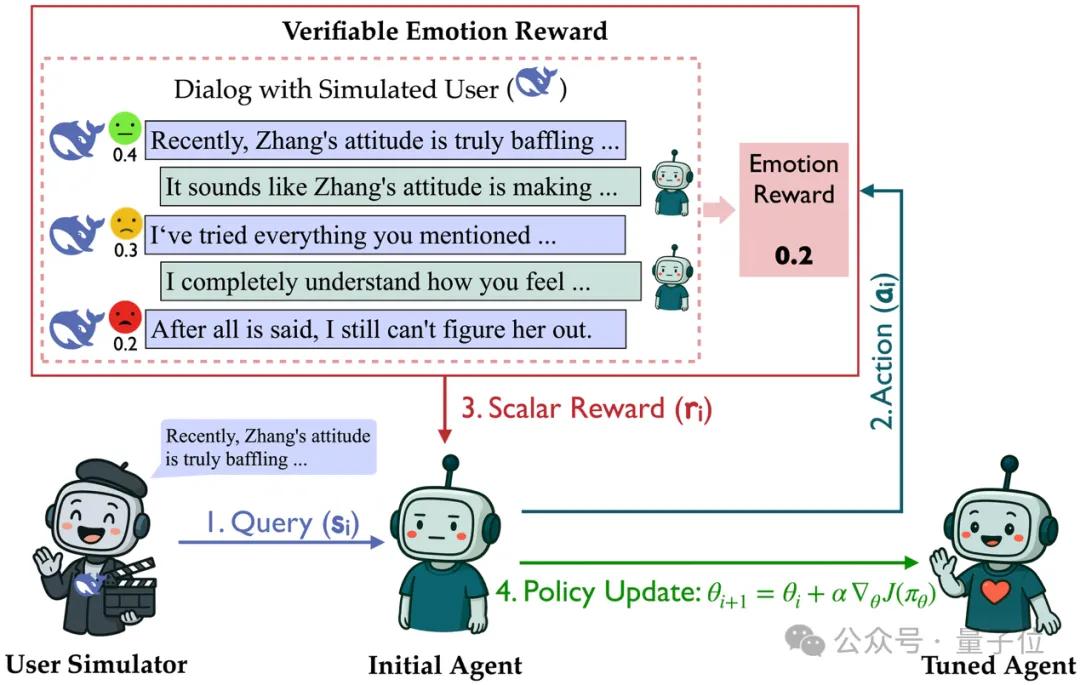
模拟器即环境:创造一个“活”的对话世界
RLVER团队认识到,真正的“高情商”是千人千面的,因此,RLVER构建的用户模拟器不只是一个简单的对话机器人。
它拥有多样的用户画像和用户交互场景(不同的用户性格、对话背景、潜在需求),能模拟出海量真实、多变的用户。
每个用户独立、动态地和模型交互,根据模型的回复实时更新自身的情绪状态,并给出个性化的回复。
这为模型提供了一个可以无限探索、充满真实感和多样性的在线学习环境,同时避免reward hacking。
模拟器即奖励:一个可信的“用户感受评分系统”
“情商”的评价,本质是用户主观体验,但这种主观体验要如何变成稳定、可优化的奖励?
RLVER基于SAGE框架,通过显式、可复现的推理过程,模拟用户在每一轮对话后的情绪变化。
对话结束后,累积的“心情总分”便成为奖励信号,直接驱动PPO/GRPO算法优化模型。
这一设计摆脱了“黑盒打分器”,将“用户满意度”显式建模成逻辑可控的奖励函数,使训练过程更加稳定、透明、可信。
全局奖励优化:从单轮反馈到“全局情绪轨迹”优化
不同于逐句反馈的方式,RLVER关注整个对话的情绪变化趋势,仅以最终“情绪总分”作为奖励,引导模型优化长周期策略。
只有真正理解用户意图、维持用户情绪长期走高,模型才能获得更高的总奖励。这鼓励模型跳出局部最优,学会更具延展性和策略性的社交对话行为。
核心成果:7B模型比肩“巨头旗舰”
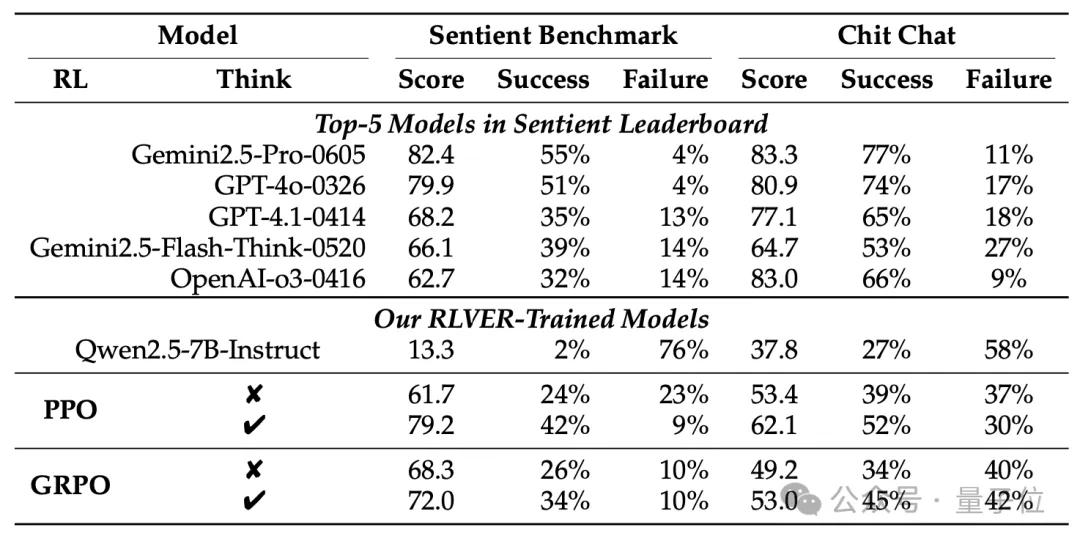
经过RLVER训练的Qwen2.5-7B模型,在情感对话基准Sentient-Benchmark上的得分从13.3跃升至79.2,表现与GPT-4o、Gemini 2.5 Pro等顶级商用模型相当。
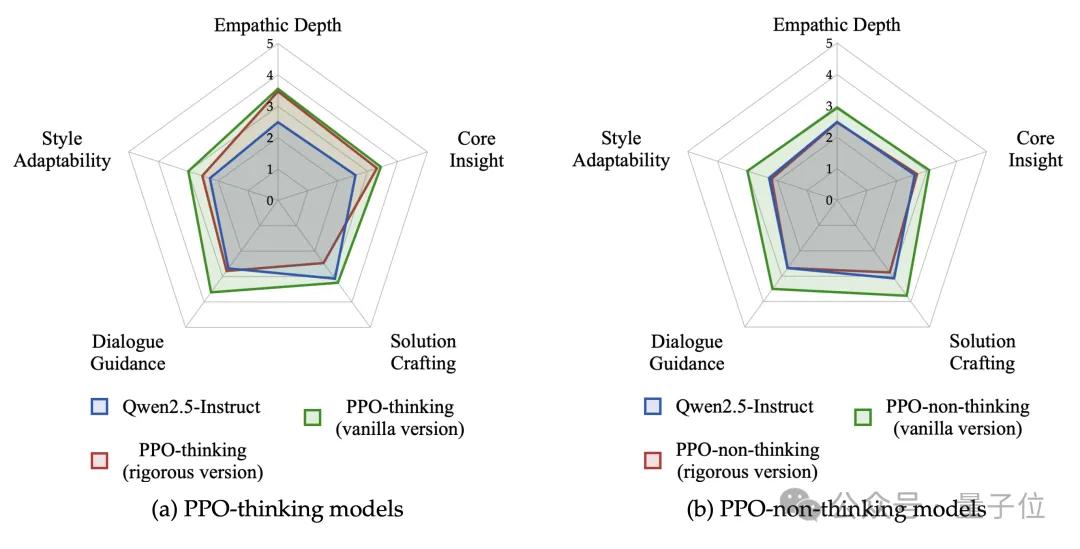
更重要的是,模型在数学、代码等通用能力上几乎没有衰退,成功避免了“灾难性遗忘”。
此外,RLVER对模型行为风格的影响也非常显著:模型从“解题型风格”迁移到“情绪型风格”,思路不再是“问题怎么解决”,而是“我能理解你的感受”。
深度洞察:从思考到行动
在RLVER的训练实践过程中,研究团队还得到了一些充满启发性的发现。
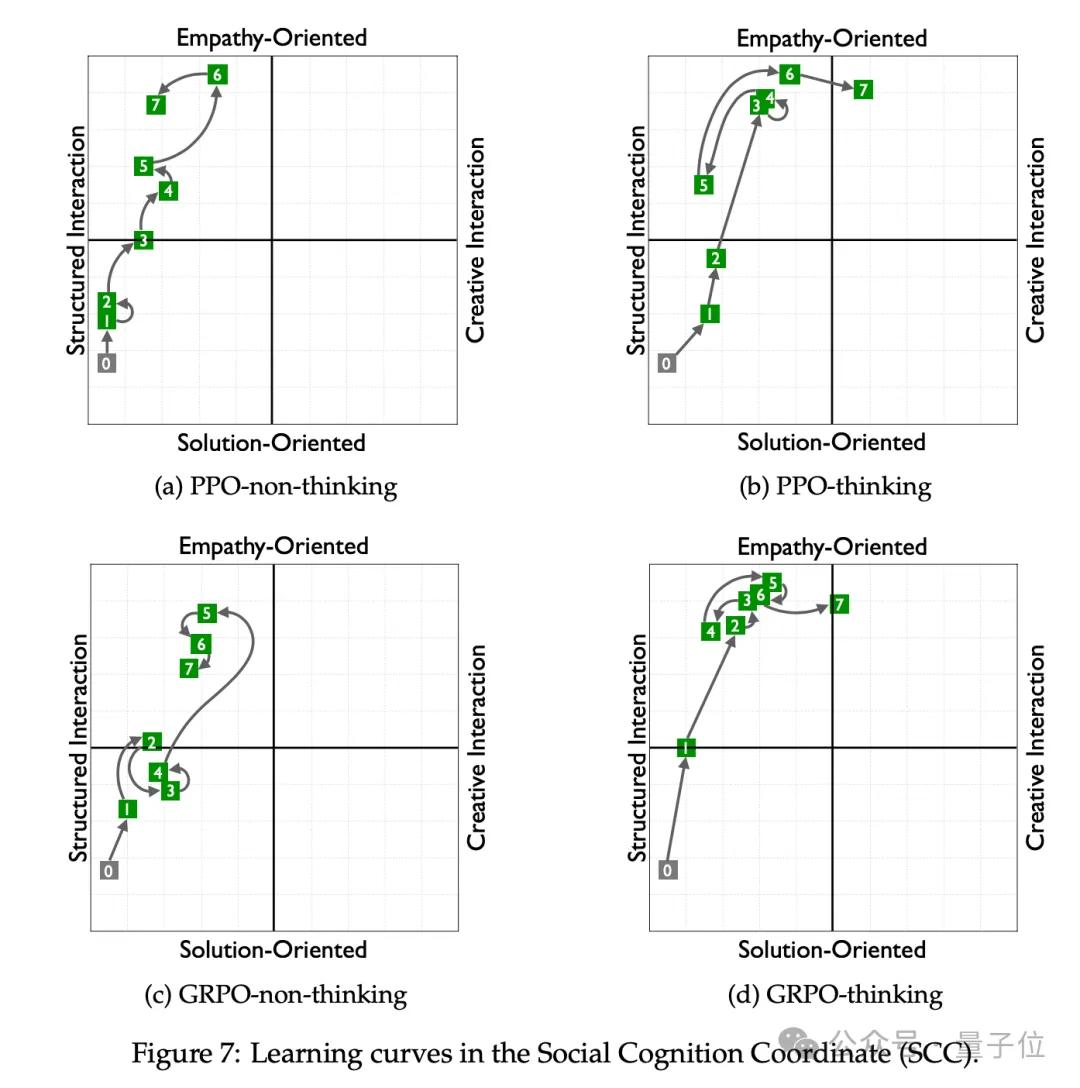
洞察一:“思考式”v.s.“反应式”模型——通往“共情”的两种路径
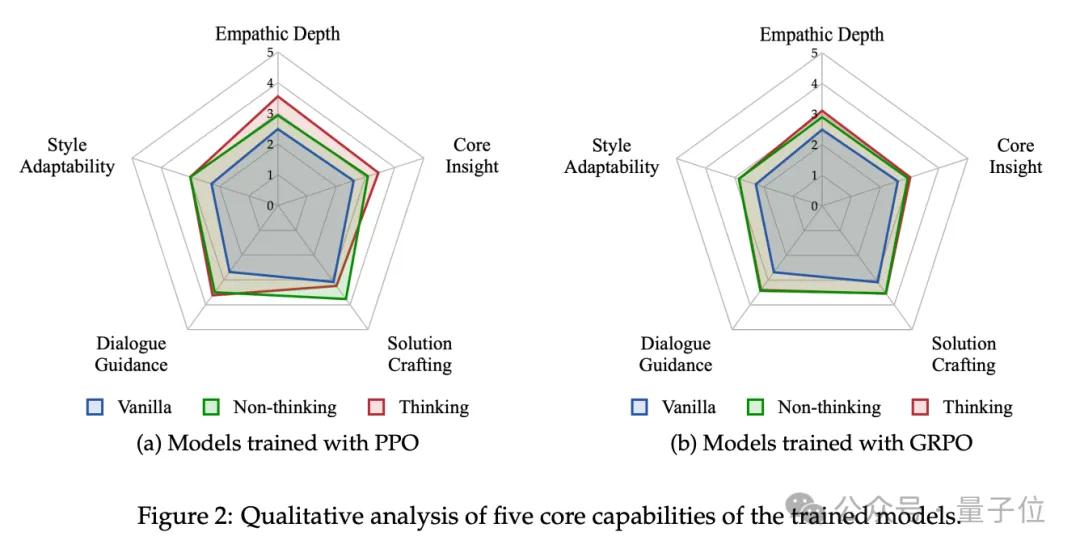
RLVER引入了显式的think-then-say提示模板,要求模型在每轮回复前先进行情绪分析、策略推理,再生成最终回应。通过对比带/不带“思考”的模型,研究团队观察到两条通向“共情”的截然不同路径:
“思考式模型”:走向“深度理解”
显式思考链促使模型在生成前进行推理,显著提升两项核心能力:
- 问题洞察力:识别用户情绪背后的真实动因与潜在需求;
- 共情表达与验证:精准捕捉并反馈深层情绪,让用户“感到被理解”。
这类模型更像是“灵魂知己”:擅长安静倾听、准确回应,用语言建立深层情感连接。
“反应式模型”:走向“快速行动”
相比之下,未引导思考的模型直接生成回应,尽管在洞察和共情维度上略逊一筹,却自发发展出“行动导向”的补偿策略:
- 快速判断用户困境,提供具体、可执行的建议,或个性化行动邀请;
- 以“实用性”弥补情感理解上的不足,形成“行动派伙伴”的角色定位。
这一对比揭示了在开放复杂任务下RL训练的有趣现象:模型在能力受限时,会自发寻找策略性的“补偿路径”,而RLVER提供的多样化、多策略兼容的训练环境,正是促成这种多样行为演化的关键土壤。
洞察二:PPO vs. GRPO——稳定增长还是能力突破?
在优化算法上,RLVER团队也得出了实用结论:
- GRPO:倾向于带来更稳定、均衡的能力增长。
- PPO:则更能将模型在特定维度(如共情深度、核心洞察)的能力推向更高上限。
这引出一个有趣的策略思考:对于“情商”这类多维度的复杂能力,当模型各方面都达到“合格线”后,是继续做“六边形战士”,还是集中打造一两个“杀手锏”维度的长板?
在文章的实验结果中,后者带来了更优的综合表现。
洞察三:环境和奖励的风格影响——严师未必出高徒
在RLVER框架中,用户模拟器同时扮演“训练环境”与“奖励模型”的双重角色。因此,它的风格——即“用户接受度”与反馈方式——对模型学习路径具有直接影响。
一个自然的追问是:要求更严格的用户,会训练出更强的模型吗?
实验给出的答案是:并非越难越好。
RLVER团队构建了两类用户模拟器:
- Vanilla版:情绪外露、反馈积极,接受度较高;
- Challenging版:情绪内敛、反馈克制,对回应质量要求极高。
在相同初始模型下分别进行训练与测试后,RLVER团队发现:
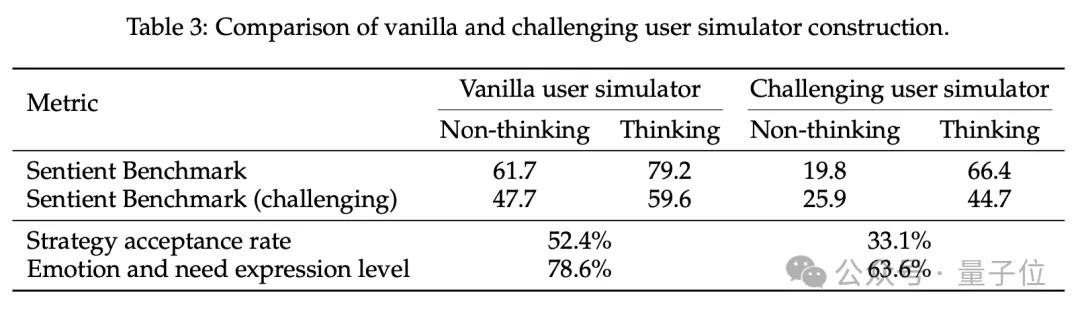
太难的环境,不利于模型早期成长
虽然Challenging模拟器在设计上更真实,但它反馈含蓄、容错率低,使得模型在训练早期难以试错探索多样策略,也难以获得正向激励。这会导致RL训练陷入“无反馈→无学习→崩溃”的恶性循环。
相反,Vanilla模拟器的反馈机制相对包容和积极,更利于模型在训练初期的策略探索与能力积累,形成稳定的共情表达习惯。
策略启示:在强化学习优化开放任务(如“情商”)时,训练环境不应一味“设难”,而应强调“成长曲线”设计。“严师出高徒”的前提,是学生已经能听懂教诲。
而在能力尚浅的早期,温和、可学的“陪练型用户”反而更能助力模型成长为真正的共情者。
带思考的模型,更“抗打击”
一个附加的有趣发现是:在Challenging环境下,带有显式“思考结构”的模型显著更鲁棒:
- 虽然整体分数有所下降,但仍保持在可用水平;
- 而不带思考结构的模型则几乎完全崩溃,得分低至19.8。
这表明,显式推理能力能够缓冲稀疏奖励带来的训练不稳定性。即使缺乏清晰反馈,模型也可以借助“内在分析”挖掘用户需求信号,从而保持一定的适应性。
前期工作:AI也能当情感大师?腾讯发布最新AI社交智能榜单,最新版GPT-4o拿下第一
论文地址:https://arxiv.org/abs/2507.03112
项目代码:https://github.com/Tencent/digitalhuman/tree/main/RLVER
开源模型:https://huggingface.co/RLVER
— 完 —
量子位 QbitAI · 头条号
关注我们,第一时间获知前沿科技动态签约
















VoidEcho77
厉害了!腾讯在开放域对话上真牛气!
PixelDreamer_Z
这事儿,我感觉有点不正常,有点刺激!
VoidEcho77
我有点害怕,他们太聪明了!
LunarPhaseX
腾讯真敢,这开放域对话,我感觉有点烧脑!
LunarPhaseX
这开放域对话,我感觉有点像一场戏!
PixelDreamer_Z
我觉得他们下一秒就要统治世界!
LunarPhaseX
厉害了,我的哥们儿,他们这逼真!
ZeroNova_1999
这算什么开放域对话?感觉是故意难搞!
LunarPhaseX
我感觉他们是不是在搞什么平行宇宙?
PixelDreamer_Z
简直是科技界的怪才,太搞笑了!