

凌晨,谷歌带着全新的Gemini 2.5 Pro炸场了!
仅一个月的时间,Gemini 2.5 Pro(06-05)直接干趴了I/O大会放出的Gemini 2.5 Pro(05-06)。
果然,能打败谷歌的,只有谷歌自己。

这次,Gemini 2.5 Pro(06-05)依旧是所有榜一。
在数学、编程、推理基准测试中,新版模型全部刷新SOTA,完全碾压o3、Claude 4、DeepSeek-R1。
相较于上一代,Gemini 2.5 Pro整体Elo提升了24分,尤其是在Web Arena上Elo提升了足足35分。

值得一提的是,更新后版本token依旧维持原价,性价比极高,输出价格仅为o3的四分之一,Claude 4就更别提了。

而且,Gemini 2.5 Pro(06-05)还引入了「思考预算」,最高达32k,还改进了函数调用等功能。

Gemini 2.5数学编码再进化,所有榜一
新版Gemini 2.5 Pro(06-05)和旧版Gemini 2.5 Pro(05-06),名字后面版本的时间,值得玩味。
很明显,谷歌这次特意选择在这个时间点放出新模型。

根据官博介绍,此次是Gemini 2.5 Pro的升级预览版,这是谷歌迄今最智能的模型。
升级基于5月I/O大会展示的基础上,这个模型将在几周后成为普遍可用的稳定版本,适合企业级应用。

最新的2.5 Pro在LMArena排行榜上Elo分数跃升24分,达到了1470,稳居榜首。
更夸张的是,它在所有领域里都排名第一。

在WebDevArena上实现了35分的Elo评分飞跃,达到1443 分。

它在编程方面表现卓越,在Aider Polyglot等高难度编程基准测试中名列前茅。
同时,它在GPQA和「人类最后考试」(HLE)等极具挑战性的基准测试中也展现了顶尖性能,这些测试评估模型的数学、科学、知识和推理能力。
谷歌还针对之前2.5 Pro版本的反馈进行了改进,提升了其风格和结构——现在它能提供更有创意、格式更优的回答。
开发者可以通过Google AI Studio和Vertex AI中的Gemini API开始使用更新的2.5 Pro进行开发,此次还新增了「思考预算」功能,能让开发者更好地控制成本和延迟。
它也在Gemini app中正式上线。

网友实测
Gemini 2.5 Pro(06-05)在真实任务中表现如何?
劈柴的一张图,早已暗示了,Gemini就是兽中之王。

网友们早已摩拳擦掌,开始了一波实测。
编码能力碾压o3、Claude 4并不只是说说而已,现在,Gemini 2.5 Pro直接通过了六边形物理模拟测试。


更惊艳的是,它还能通过Three.js创建出3D DNA模型,效果非常逼真。

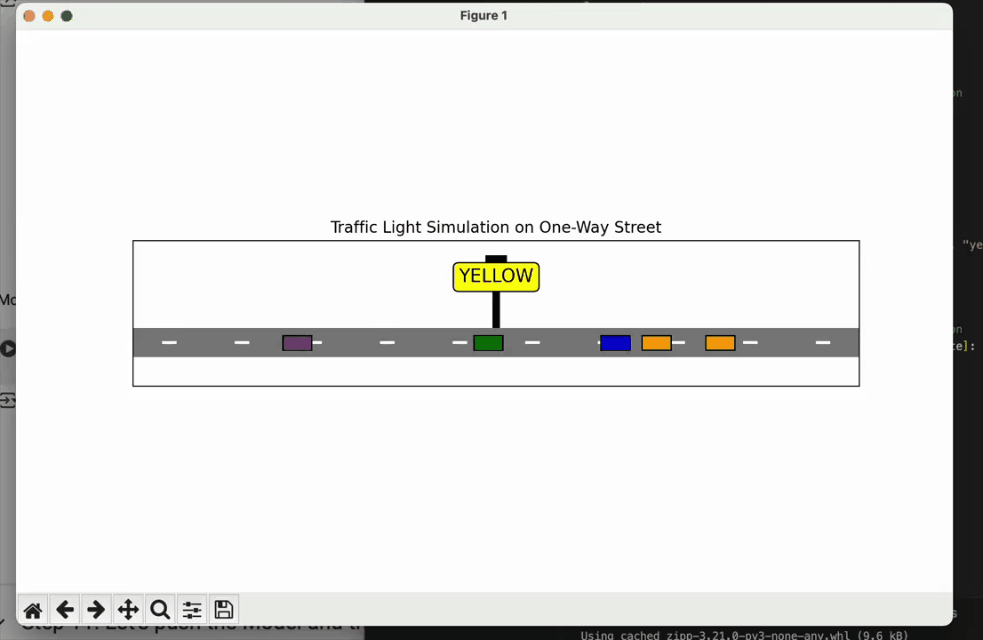
数据科学家Diego测试Gemini 2.5 Pro 06-05编写一段Python代码,可视化单行道中交通灯的工作原理,要求车辆以随机速率进入。

代码运行后的效果。
可以看出整体上动画还是比较精美的,没有什么太大的问题。

作为对比,下面是GPT 4.5生成代码的效果。
不仅画面粗糙,车子也不符合物理规律。

Diego之前还测试了Claude Sonnet 3.7和Grok 3,下面是这两个模型的表现。
大家可以评判一下,到底哪个模型更强。
Claude Sonnet 3.7

Grok 3
参考资料:
https://x.com/sundarpichai/status/1930656033237823862
https://x.com/GoogleDeepMind/status/1930656243346976925
https://blog.google/products/gemini/gemini-2-5-pro-latest-preview/
https://x.com/lmarena_ai/status/1930658518560133435
文章来自公众号“新智元”
















