
BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数,其中70亿为活跃参数。采用混合变换器专家架构(MoT),通过两个独立编码器分别捕捉图像的像素级和语义级特征。

BAGEL遵循”下一个标记组预测”范式进行训练,使用海量多模态标记数据进行预训练,包括语言、图像、视频和网络数据。
主要功能:
图像与文本融合理解:BAGEL能深入理解图像和文本之间的关系,准确地将图像内容与文本描述相结合。

视频内容理解:BAGEL能处理视频数据,理解视频中的动态信息和语义内容。能捕捉视频的关键信息并进行有效的分析。
文本到图像生成:用户可以通过输入文本描述来生成相应的图像。BAGEL能根据文本内容生成高质量、与描述匹配的图像。

图像编辑与修改:BAGEL支持对现有图像进行编辑和修改。BAGEL能根据指令生成修改后的图像,实现自由形式的图像编辑。
视频帧预测:BAGEL能预测视频中的未来帧。基于视频的前几帧,模型可以生成后续的帧内容,恢复视频的完整性。
三维场景理解与操作:BAGEL能理解和操作三维场景。可以对三维物体进行识别、定位和操作,例如在虚拟环境中移动物体、改变物体的属性等。
世界导航:BAGEL具备世界导航能力,可以在虚拟或现实的三维环境中进行路径规划和导航。
跨模态检索:BAGEL能实现跨模态检索功能,例如根据文本描述检索与之匹配的图像或视频,或者根据图像内容检索相关的文本信息。
性能测试:
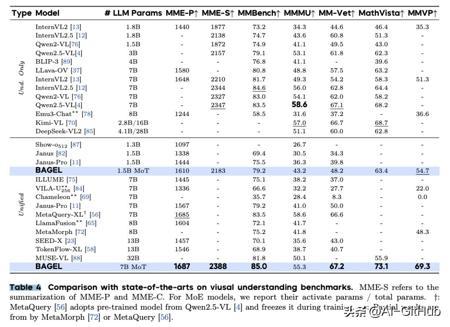
BAGEL 在理解任务上优于现有的统一模型。例如,在 MMMU 和 MM-Vet 上分别比 Janus-Pro提高了 14.3 和 17.1 分。值得注意的是,MetaQuery-XL依赖于冻结的、预训练的 Qwen2.5-VL主干网络,这限制了其适应性。
此外,与专用理解模型(如 Qwen2.5-VL 和 InternVL2.5)相比,BAGEL 在大多数基准测试上表现更优,表明我们的 MoT 设计在保持强大视觉理解能力的同时,有效缓解了任务冲突。
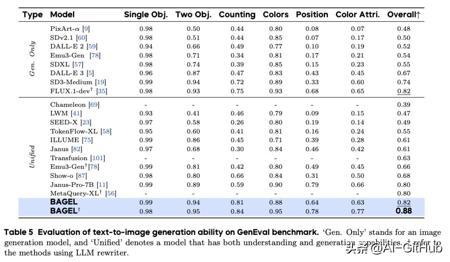
在 WISE 基准上,BAGEL 超越了除领先私有模型GPT-4o外的所有模型。这表明 BAGEL 在结合世界知识进行推理方面具有较强能力。
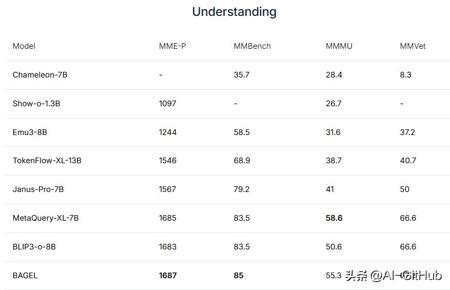
BAGEL 使用更多的多模态令牌来扩展预训练,在理解、生成和编辑任务方面取得了一致的性能提升。
GitHub:https://github.com/bytedance-seed/BAGEL















