
刚刚,硅谷爆出新料:OpenAI企业市场份额断崖式下跌,Anthropic全面反超!
GPT-5再不来,奥特曼正要熬夜头秃,无法入眠了!
刚刚,OpenAI最强劲敌Anthropic被曝年化收益已达45亿美元,晋级为史上增长最快的软件公司。
在LLM API赛道上,Anthropic成功登顶,而OpenAI在AI编程上更是落荒而逃,市场份额只有Anthropic一半!
X上的网红投资人、硅谷VC大佬Deedy,继2024年AI产业报告之后,重磅推出了年中LLM市场更新报告:
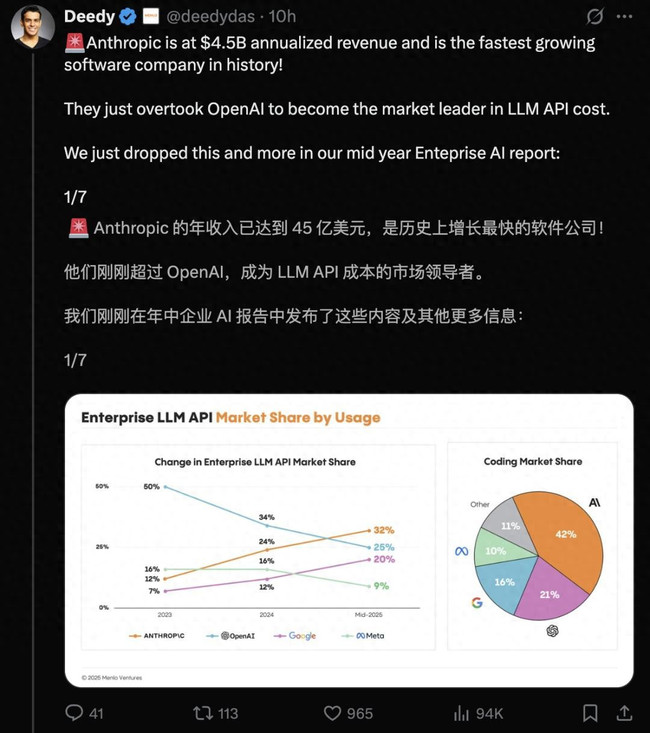
这次他直接断言:旧皇已死,新王登基!随着使用量和支出的激增,新的企业级LLM领导者已应运而生。
除了预判未来趋势外,这次他还分享了LLM商业化的4大趋势:
1. Anthropic在企业领域的使用率已超越OpenAI
2. 企业采纳开源技术的趋势正在放缓
3. 企业更换模型看重的是性能提升,而非价格优势
4. 企业在AI上的投入正从模型训练转向实际应用的推理阶段
LLM天下三分,OpenAI痛失一城
2025年已过一半,AI大模型赛道却已悄然进入「中场战事」。
刚刚,Menlo Ventures发布了中场报告,揭示了整个LLM行业的新格局,也为下半年的市场走势埋下了伏笔。
这次重点在企业市场。在6月30日至7月10日,他们调研了150家开发AI应用的企业和初创公司技术负责人。

「企业」指员工规模超5000人的组织,初创公司则要求至少500万美元风险投资
到本年中,企业在基础模型API上的投入已高达84亿美元,远超去年全年的两倍。他们预计企业在基础模型上的花费还将继续飙升。
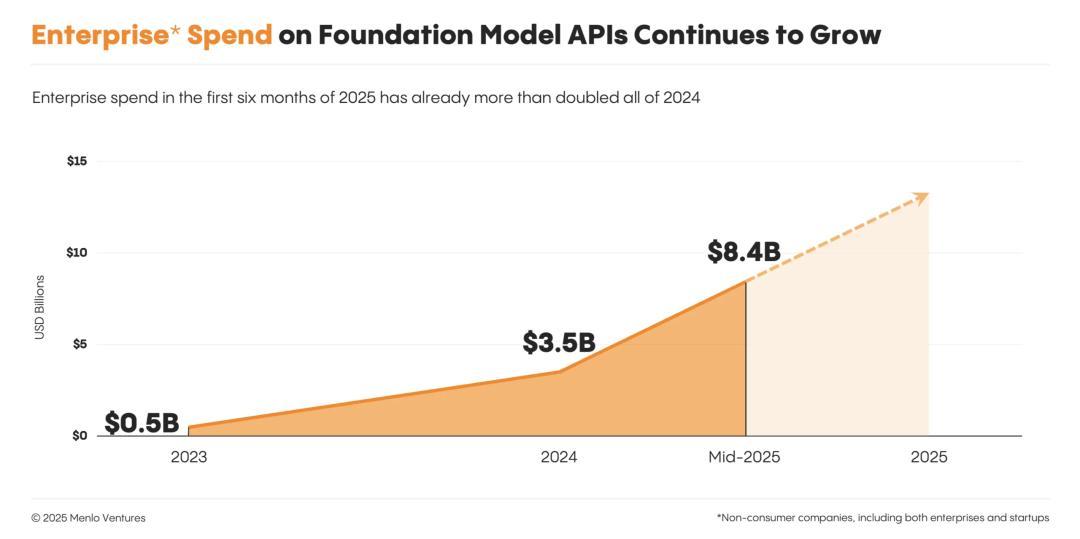
企业在LLM API方面的支出
正如他们的报告所言:基础模型不仅是生成式AI的动力,还在塑造计算的未来。
随着其能力与商业模式的演进,构建于其上的系统、应用和产业也将随之变革。
曾经,OpenAI凭借ChatGPT 3.5和4系列横扫市场,遥遥领先。
但如今,局势开始松动。
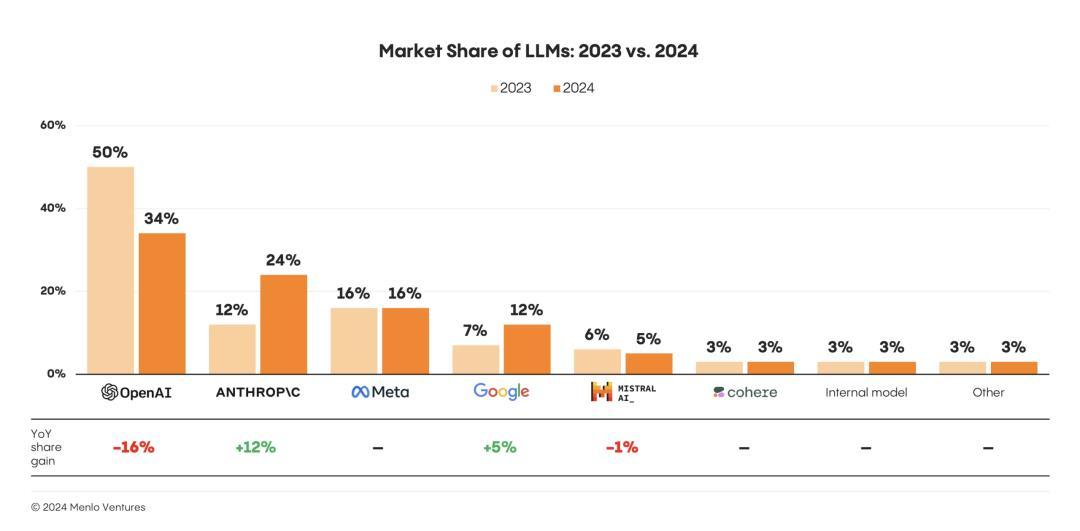
从2023年到今年年中,企业LLM API调用量市场数据显示:
· Anthropic上增长最快,以32%的份额击败OpenAI,成功登顶;
· 谷歌增长速度次之,年中市场份额已达20%,位居第三;
· OpenAI和Meta使用份额持续下降,尤其是OpenAI从50%跌至25%;
· Meta的使用份额不足9%,沦为边缘角色。
这就是他们的核心发现:Anthropic在企业使用率上超越了OpenAI。

OpenAI已失一城,难再躺赢。
美版「AI三国」正式成型。
旧王已逝,新皇登基
在2023年底,OpenAI一度占据企业LLM市场50%的份额,但如今地位不再,现在的使用率仅为25%,是两年前的一半。
而Anthropic已成为企业AI市场的新晋领导者,占据了32%的份额,领先于OpenAI和谷歌(20%)。
最近几个月,谷歌也表现出强劲的增长。Meta只占据了9%的份额。
国产的DeepSeek在年初发布,也占了1%。
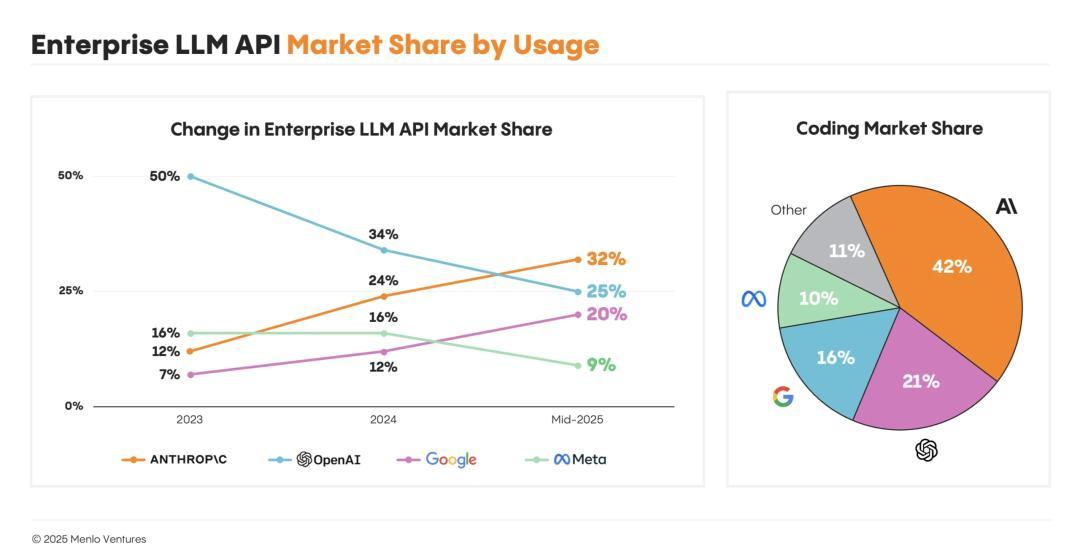
按使用量计算的企业LLM API市场份额
Anthropic的强劲势头,真正始于2024年6月Claude Sonnet 3.5的发布。
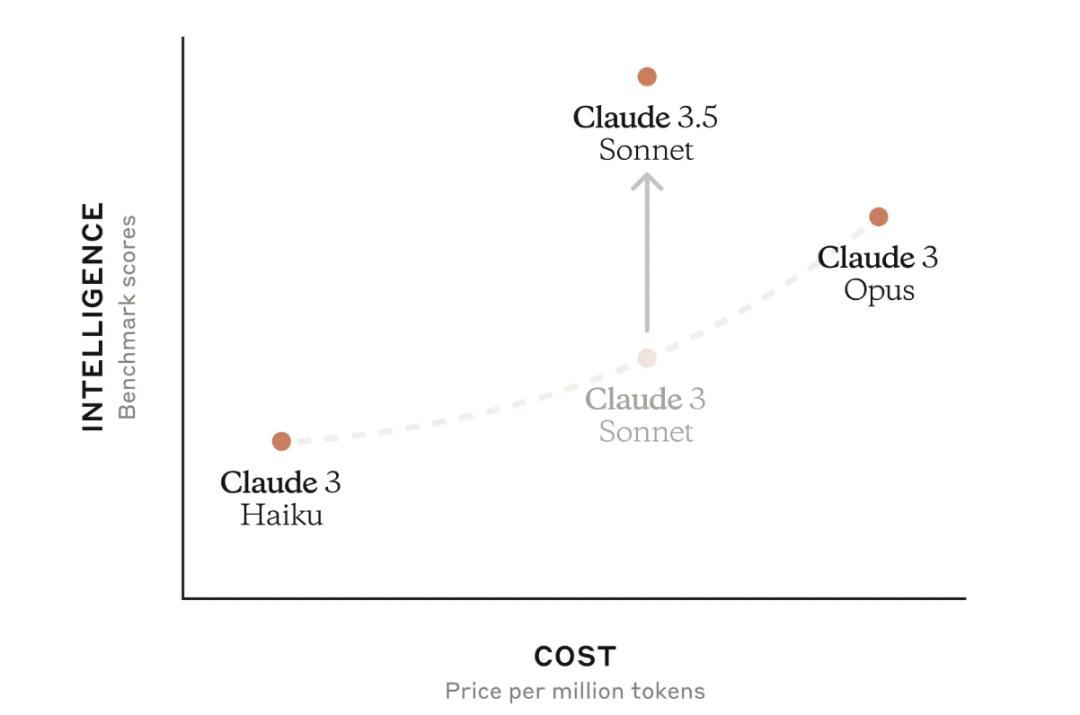
与Claude 3 Haiku和Opus比较,Claude Sonnet 3.5具有极高的性价比
今年2月,Anthropic推出了Claude Sonnet 3.7。
Claude Sonnet 3.7首次让人们一瞥「Agent-First」大语言模型。这进一步加速了这股势头。
到5月,Claude Sonnet 4、Opus 4和Claude Code相继发布,Anthropic彻底巩固了市场领先地位。


至此,Anthropic一鼓作气成功登顶,而OpenAI痛失企业LLM市场龙头地位。
Anthropic乘风而起
Anthropic的崛起也得益于三个颠覆性行业趋势。
(1)代码生成成为AI的首个杀手级应用。
Claude迅速成为开发者Coding首选,占据了42%的市场份额,是OpenAI(21%)的两倍多。
仅在一年内,Claude就帮助将GitHub Copilot市场,转变为价值19亿美元的庞大生态系统。
2024年6月发布的Claude Sonnet 3.5证明,模型层的突破能直接撬动应用市场,催生出全新赛道:
· AI IDE:Cursor、Windsurf等;
· 应用构建器:Lovable、Bolt、Replit等;
· 企业级编码智能体:Claude Code、All Hands等;
……
(2)带验证器的强化学习,成为提升模型智能的新路径。
在2024年,提升模型智能的主要方法是投入更多数据,进行更大规模的预训练。
如今,互联网数据的规模本身正成为瓶颈。而采用带可验证奖励的强化学习(RLVR)进行后训练,则成为推动技术前沿的下一个突破口。
在编码这类易于进行确定性验证的领域,该策略的效果尤为出色。
(3)将模型训练为使用工具的「智能体」,使其效用大增。
最初,LLM被设计为在一次交互中给出完整答案。
然而,通过训练模型进行分步思考、推理问题,并在多次交互中调用外部工具——即构建所谓的「智能体」——能极大地提升模型在真实应用场景中的效能。因此,2025年被称为「智能体之年」。
Anthropic在这方面处于领先地位,他们训练模型以迭代方式优化回答,并通过模型上下文协议(MCP)整合搜索、计算器、编码环境等多种工具,从而显著提升了模型的能力和用户采用率。
海外企业市场,开源日渐沉寂
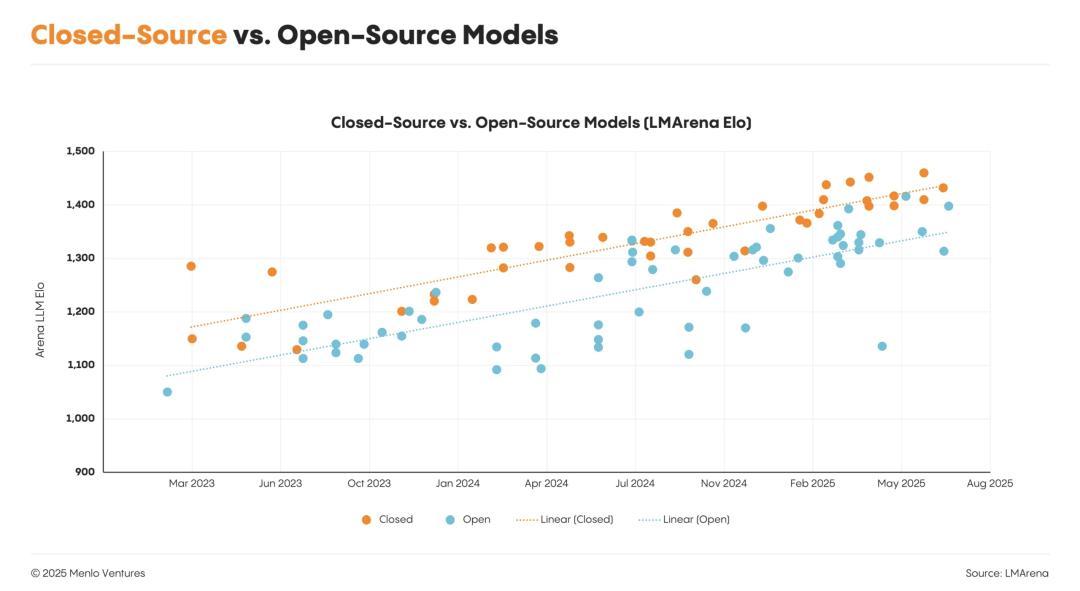
现在,只有13%的AI工作负载使用开源模型,而半年前是19%。
2024年,Menlo Ventures调研的LLM市场份额同期对比
过去半年内,DeepSeek(V3,R1)、Qwen3、GLM-4.5等国内开源大模型相继发布,引人注目。
这次调研显示市场份额最大的是Meta广受欢迎的Llama模型,但其4月发布的Llama 4表现未及预期。
对企业而言,开源模型优势明确:
可定制性更强、有潜在的成本效益,并且能部署在私有云或本地环境中。
但在性能上,他们认为开源模型仍落后于顶尖闭源模型大约9到12个月。
这种性能差距,加上部署开源模型的技术复杂性,以及企业技术选型的犹豫,共同导致了开源模型市场份额的停滞。
闭源模型 vs. 开源模型
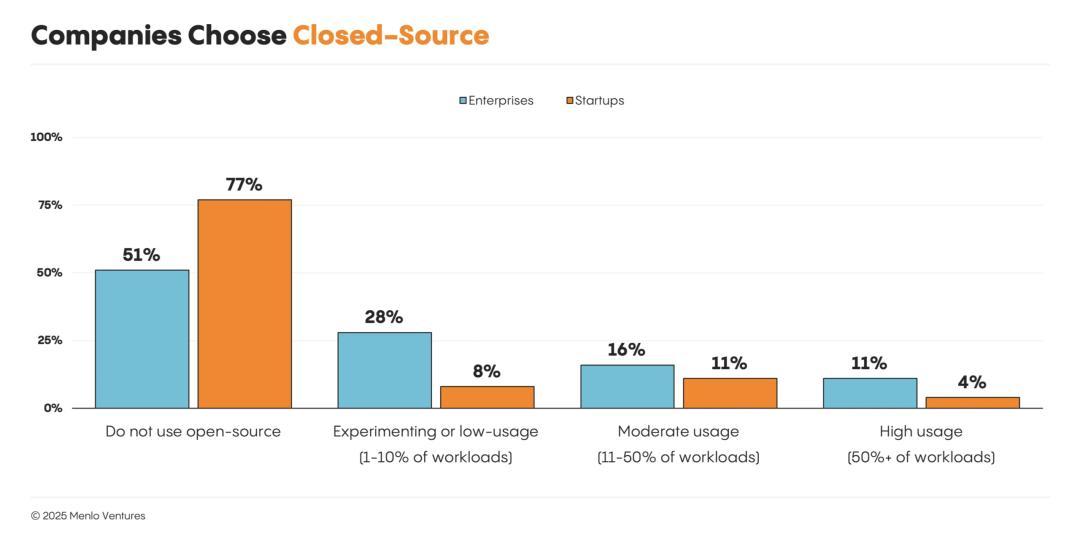
不仅是大型企业,出于同样的原因,选择开源模型的初创公司也越来越少。
正如一位受访者所说:
目前,我们的生产工作负载,100%运行在闭源模型上。最初,我们使用Llama等进行概念验证(POC)。但随着时间推移,它们的性能无法跟上闭源模型的步伐。
公司选择闭源
价格战在企业市场行不通
尽管在不同供应商之间切换模型的难度相对较低,但这种情况正变得越来越少见。
大多数团队会继续使用原有的供应商,只在新模型发布时进行升级。一旦开发者选定一个平台,他们就倾向于留下来,但会在性能更强的新模型发布时迅速升级。
过去一年,66%的开发者在原供应商内部升级了模型,23%完全没有更换模型,只有11%更换了供应商。
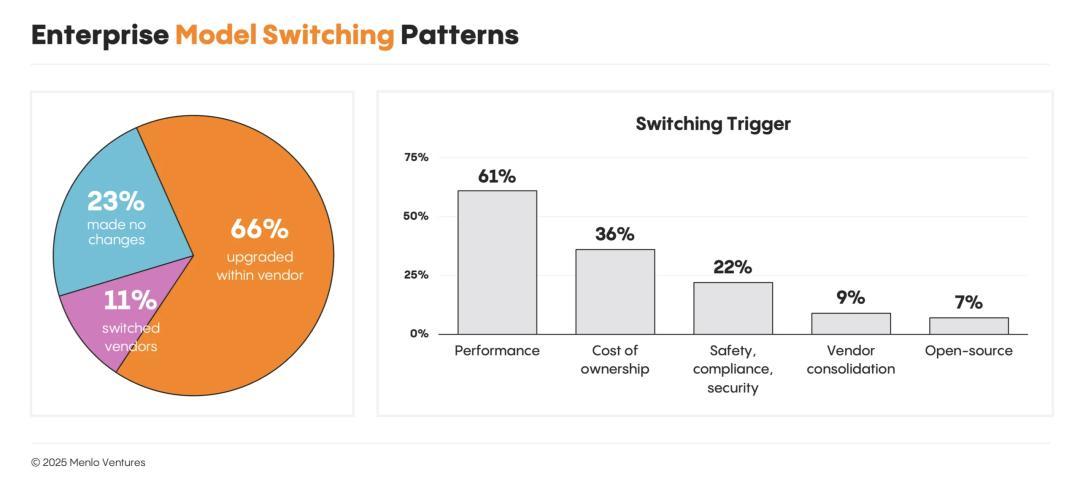
企业模型切换模式
性能是决策的核心驱动力。
开发者们始终选择最前沿的模型,而不是那些更便宜、更快的替代品。他们优先考虑性能,并愿意为此付费。每当新模型发布,切换通常在几周内完成。例如,在Claude 4发布的一个月内,Claude 4 Sonnet就吸引了45%的Anthropic用户,而Sonnet 3.5的份额则从83%骤降至16%。
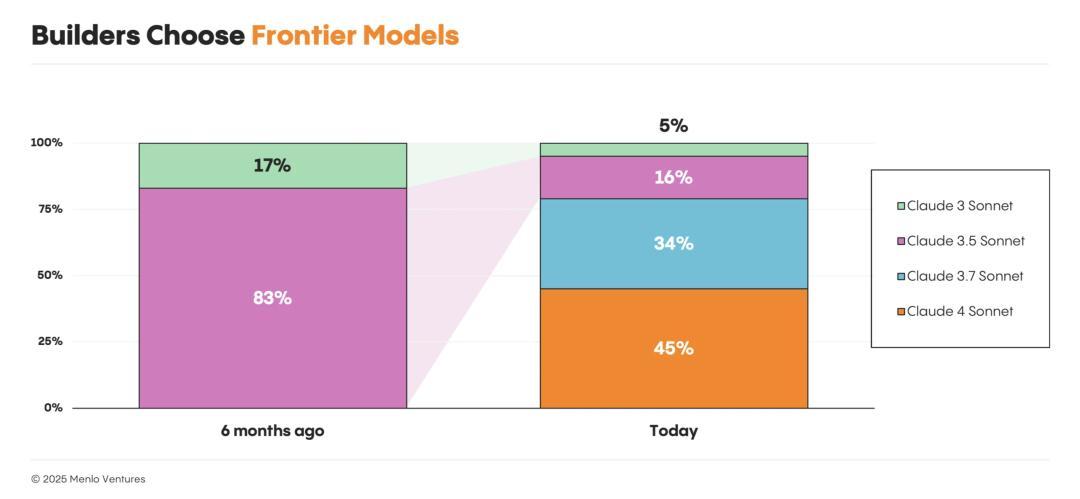
开发者选择前沿模型
一种出人意料的市场趋势出现了:
即使模型的价格每年下降10倍,开发者也不会为了节省成本,只用旧模型;他们只会集体迁移到性能最强的新模型。
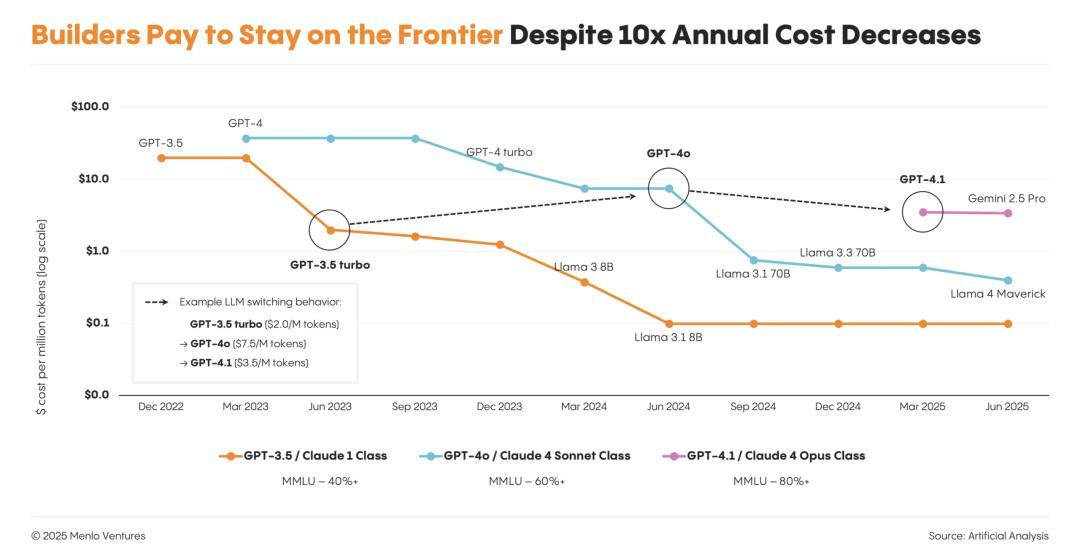
尽管年度成本下降10倍,开发者仍愿付费使用前沿模型
推理比训练更花钱
计算资源的支出正在稳步地从模型构建和训练,转向模型推理——即模型在生产环境中的实际运行。
这种转变在初创公司中最为显著:74%的开发者表示,他们的大部分工作负载是推理,远高于一年前的48%。
大型企业也紧随其后,近一半(49%)的企业报告称,其绝大部分计算资源由推理驱动,而去年这一比例仅为29%。
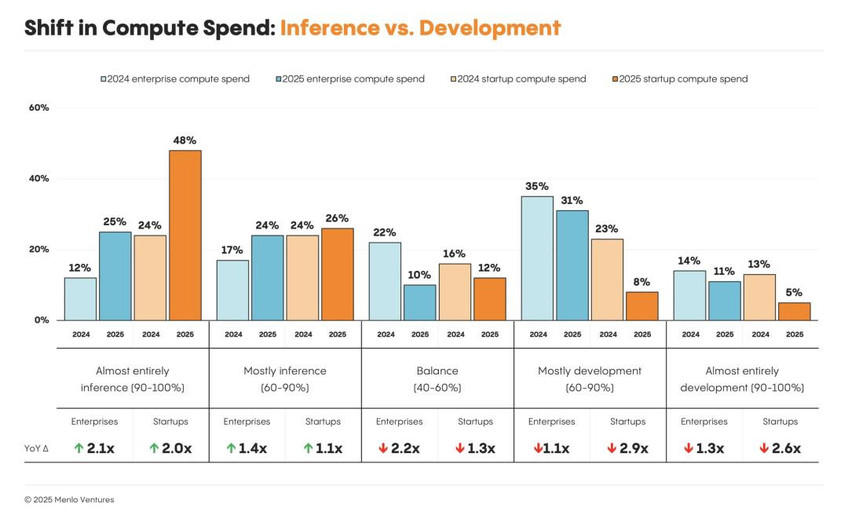
计算资源支出的转变:推理 vs. 开发
AI行业新时代
应用为王时代来临,LLM不再是极客的「电子宠物」,而是企业的「基础设施」。
不再是demo show-off,不再是PPT跑分,现在LLM必须落地到真实应用场景中。
应用新趋势:
· API平台化:Anthropic、Cohere等转型做「开发者友好接口」
· 垂类微调:医疗、金融、代码生成等场景专属模型风口已起
· 原生产品爆发:AI Agent、AI写作、AI分析师迅速涌现
谁能提供真实ROI,谁才是下一个市场赢家。
LLM市场正在重新洗牌,一场无声的淘汰赛已经展开。
或许,2023年属于OpenAI,2024年属于Claude与Llama,但2025年,属于谁还远未确定。
而我们只知道:
模型性能≠市场赢家
封闭系统≠未来主流
高估值≠商业成功
真正的赢家,是「AI界的福特」——那个「让AI用起来的人」。
参考资料:
https://x.com/deedydas/status/1950942147529843121
https://menlovc.com/perspective/2025-mid-year-llm-market-update/
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
















