
Archer团队 投稿
量子位 | 公众号 QbitAI
当大模型在数学题和代码任务里“卷”参数规模时,一支来自快手和清华的团队给出了不同答案——
他们用1.5B参数的小模型,在多个推理基准上干过了同量级SOTA。
秘密在于给模型的“学习过程”做了精细化管理:让该记牢的知识稳住,让该灵活的推理放开。
在多个挑战性的数学、代码评测基准上,该团队提出的Archer方法都展现出了强大的实力。
目前,Archer的代码已开源,详细链接可见文末。

“两难”:知识和推理难兼顾
通过预训练,LLM能记住海量的知识。但要让这些知识转化为解决数学题、写复杂代码的推理能力,还得靠后续的强化学习(RL)优化。
其中,带可验证奖励的强化学习(RLVR)是当前的主流方法——简单地说,就是让模型不断尝试解题,通过“是否做对”的反馈调整行为,有点像人类“做题纠错”。
但问题来了:模型输出的内容里,有些是“知识型”的(比如“1+1=2”这类事实),有些是“推理型”的(比如“先算括号里,再算乘除”这类逻辑规划步骤)。
过去的RLVR方法要么“一视同仁”,给所有内容用一样的训练信号;要么“粗暴分割”,用梯度屏蔽把两类内容拆开训练。
结果往往是:要么知识逐渐变差(比如把公式记错),要么推理放不开(比如总用老套思路解题)。
快手和清华团队发现:这两类内容在模型里其实有明显特征:
- 低熵Token
- (确定性高):比如“3.14”、“def函数”,对应事实性知识,训练时不能乱改;
- 高熵Token
- (不确定性高):比如“因此”、“接下来”、“循环条件”,对应逻辑推理,需要多尝试。
但关键在于,这两类Token在句子里是“绑在一起”的——比如解数学题时,“因为2+3=5(低熵),所以下一步算5×4(高熵)”,拆开会破坏语义逻辑。
Archer:给Token“差异化训练”
团队提出的Archer方法,核心是“双Token约束”——不拆分Token,而是给它们定制不同的训练规则。
简单说就是两步:
1.先给Token“贴标签”:用熵值分类型
通过计算每个Token的熵值(不确定性),自动区分“知识型”和“推理型”:
- 高熵Token:比如数学推理里的“接下来”、“综上”,代码里的“循环”、“判断”,是逻辑转折点;
- 低熵Token:比如“123”、“print”,是必须准确的事实性内容。
团队用“句子级熵统计”替代传统的“批次级统计”——比如同一道数学题,不同解法的Token熵分布不同,按句子单独划分,避免把“关键推理Token”误判成“知识Token”。
2.再给训练“定规矩”:差异化约束
对贴好标签的Token,用不同的规则训练:
- 推理型(高熵)Token:松约束。用更高的裁剪阈值(允许更大幅度调整)和更弱的KL正则(减少对原始策略的依赖),鼓励模型多尝试不同推理路径;
- 知识型(低熵)Token:紧约束。用更低的裁剪阈值和更强的KL正则,让模型“死死记住”正确知识,避免越训越错。
这样一来,知识和推理既能同步更新,又不互相干扰——就像老师教学生:基础公式要背牢,解题思路可以大胆试。
从数学到代码:全面碾压同量级模型
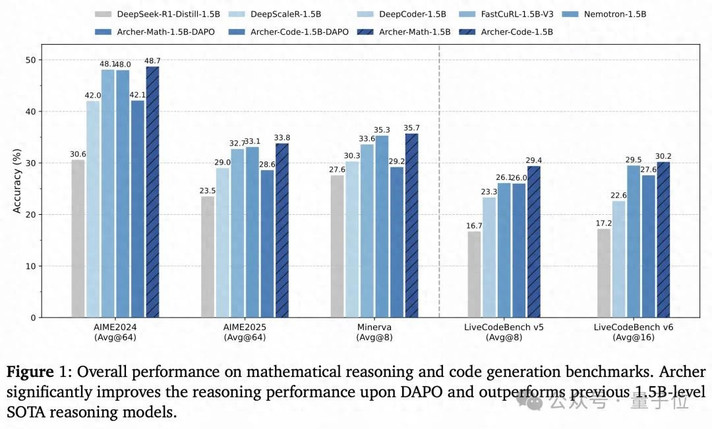
在最考验推理能力的数学和代码任务上,Archer的表现都很出色。
数学推理:解题正确率大幅提升

在AIME 2024/2025、Minerva等硬核数学基准上:
- 相比同基座的原始模型,Archer在AIME24上正确率提升18.1%,AIME25提升10.3%;
- 对比当前SOTA方法DAPO,Archer在AIME24上多对6.6%的题,AIME25多对5.2%;
- 1.5B参数的Archer-Math,直接超过了FastCuRL、Nemotron等同量级SOTA模型,平均正确率登顶。
代码生成:刷题能力显著增强

在LiveCodeBench(主流代码生成基准)v5/v6上:
- 相比DAPO,Archer在v5上正确率提升3.4%,v6提升2.6%;
- 超过了专门优化代码的DeepCoder-1.5B,成为同量级最佳代码生成模型之一。

效率方面,Archer只用单阶段训练、1900 H800 GPU小时(对比Nemotron的16000 H100小时),就实现了这些提升。
没有复杂的多轮训练,达到了“花小钱办大事”的效果。
关键在“平衡”
Archer的核心洞察是:LLM推理能力不是“死记硬背”或“盲目试错”,而是知识稳定性和推理探索性的平衡。
团队通过实验验证了这种平衡的重要性:


- 若不给低熵Token加约束(KL=0),模型会很快“记混知识”,输出重复内容,性能崩塌;
- 若给高熵Token加严约束(裁剪阈值太小),模型推理“放不开”,学不到新方法;
- 只有让知识Token“稳”、推理Token“活”,才能既不丢基础,又能提升逻辑能力。
这种思路也解释了为什么小模型能逆袭——大模型的参数优势能堆出更多知识,但如果训练时“管不好”知识和推理的关系,能力提升反而受限。
Archer用精细化的Token管理,让小模型的每一个参数都用在刀刃上,学会如何更好的组织使用已有的知识。
论文链接:http://arxiv.org/abs/2507.15778
GitHub:https://github.com/wizard-III/ArcherCodeR
— 完 —
量子位 QbitAI · 头条号
关注我们,第一时间获知前沿科技动态签约
















