

近日,阿里开源长文本深度思考模型QwenLong-L1!
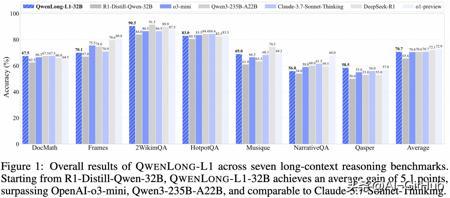
通过渐进式上下文扩展策略逐步提升模型在长上下文推理任务上的表现,最终在多个长文档问答 benchmarks 上表现卓越!其32B参数版本超过OpenAI-o3-mini、Qwen3-235B-A22B等,取得与
Claude-3.7-Sonnet-Thingking相当的性能。
功能创新:
- 定义长上下文推理强化学习范式
区别于短上下文推理强化学习促进模型利用内部知识推理,长上下文推理强化学习需要模型首先定位外部关键信息然后整合内部推理。
- 识别长上下文推理强化学习关键问题
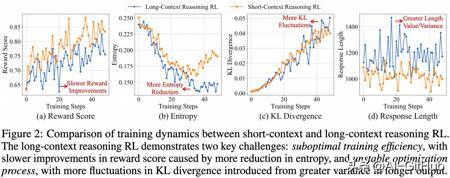
长上下文推理强化学习训练效率低,具体表现在(a)奖励收敛较慢,(b)模型输出熵的显著降低,限制了优化过程中的探索行为。同时,长上下文推理强化学习训练不稳定,具体表现为(c)KL 散度突刺较多,这是由于(d)较长的输出长度和不均匀的输入长度导致方差变大,导致策略更新不稳定。
- 构建 QwenLong-L1 长上下文推理强化学习框架
基于渐进式上下文扩展技术和混合奖励机制,QwenLong-L1 通过强化学习实现了从短文本到长文本的稳定上下文适应。
- 开源 QwenLong-L1-32B 长上下文文档推理大模型
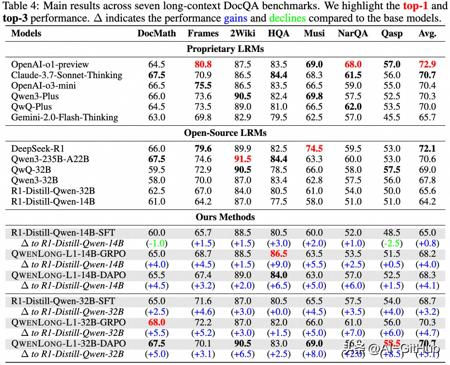
与前沿长上下文推理大模型相比,QwenLong-L1-32B 实现了显著的性能提升,相较于
DeepSeek-R1-Distill-Qwen-32B 平均提升 7.8%,不仅超越 OpenAI-o3-mini、Qwen3-235B-A22B 等旗舰模型,更与
Claude-3.7-Sonnet-Thinking 性能对标,为长文本推理优化提供了基础性技术方案。
性能测试:
在国内外旗舰推理模型中处于领先地位:
- QwenLong-L1-14B 模型平均 Pass@1 达到 68.3,超越 Gemini-2.0-Flash-Thinking, R1-Distill-Qwen-32B, Qwen3-32B;
- QwenLong-L1-32B 模型平均 Pass@1 达到 70.7,超越 QwQ-Plus, Qwen3-Plus, OpenAI-o3-mini, 与 Claude-3.7-Sonnet-Thinking 持平;
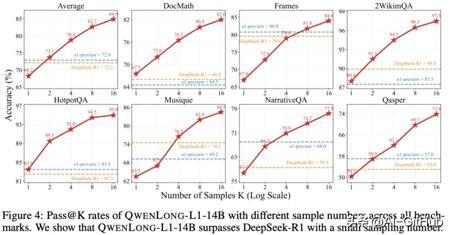
Test-Time Scaling 性能明显:QwenLong-L1-14B 模型平均 Pass@2 达到 73.7,超越 DeepSeek-R1 (Pass@1, 72.1), OpenAI-o1-preview (Pass@1, 72.9) 。
QwenLong-L1-32B 的出现,为我们打开了一扇通往长文本推理新世界的大门。相信在未来,基于这一模型和框架,将会涌现出更多创新的应用和解决方案,为人们的生活和工作带来更多的便利和惊喜。
GitHub:https://github.com/Tongyi-Zhiwen/QwenLong-L1
#AI开源项目推荐##github##AI技术##通义开源#长文本分析















