

近日,Apple 机器学习研究团队发布了一篇名为《思考的幻觉(The Illusion of Thinking)》的论文。

这篇 53 页的技术报告并非普通评测,而是一记质疑当下主流 LLM 推理能力的重锤。
研究者们指出,OpenAI 的“o”系列、Google 的 Gemini 2.5、以及 DeepSeek-R 等所谓“推理型大模型”,本质上并没有从训练数据中学习到可泛化的第一性原理。
他们用了四个经典问题来证明这一观点:汉诺塔(Tower of Hanoi)、积木世界(Blocks World)、过河问题(River Crossing)和跳棋(Checkers Jumping)。
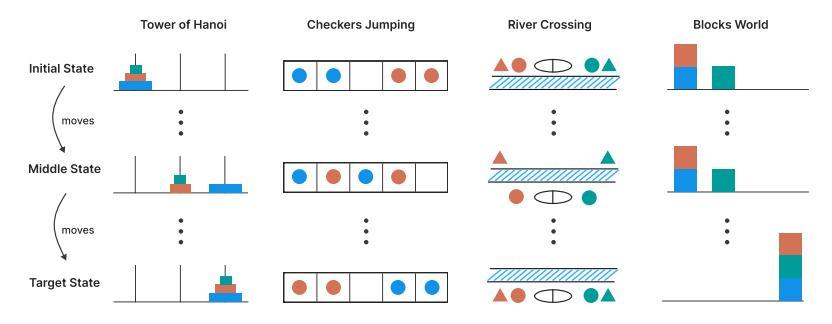
图注:四类经典问题的示意图。
这些任务的特点是,可以通过增加步骤和限制条件,让难度指数级飙升,极其考验模型的长链条逻辑规划能力。
苹果的要求也很苛刻:不仅要给出正确答案,还得用“思维链”的方式,把解题的每一步都写出来。
结果呢?
正如苹果所料,随着谜题越来越难,所有顶尖推理模型的准确率都直线下滑。在最复杂的任务面前,性能直接崩盘,准确率归零。

图注:在所有谜题环境和不同难度级别下,思维模型(Claude 3.7 Sonnet with thinking、DeepSeek-R1)与其非思维对应模型(Claude 3.7 Sonnet、DeepSeek-V3)在准确率方面的对比。
更有意思的,是苹果研究员发现的一个现象:模型用于“思考”的篇幅(也就是输出的token数量)也开始缩水。
作者将此视为模型主动减少推理尝试的迹象。
也就是说:推理,是幻象。

这篇论文在X(推特)上被疯狂转发,很多人上来就直接宣判:“苹果已经证明了,像Claude、DeepSeek这类模型根本不会推理,它们只是记性特别好的复读机罢了!”
反转来了:“思考幻觉”本身的幻觉

争议的火苗很快被一篇名为《The Illusion of The Illusion of Thinking》的反驳论文点燃,作者是一位名叫Alex Lawsen的独立研究员——以及,他的合作伙伴:大语言模型Claude Opus 4。
是的,一篇论文,合著者是AI。
他们认为,苹果所谓的“推理崩溃”,根本不是AI能力的上限到了,而是实验设计本身存在致命缺陷。
槽点一:混淆了“推理失败”和“作文本不够长”
这是最核心的一个反驳点。
批评者指出,像汉诺塔这类问题,解决步骤是随着盘子数量指数级增长的。比如,要解开15个盘子的汉诺塔,需要输出超过32000个步骤。
而大模型的上下文窗口和单次输出Token都是有上限的。
模型很可能在内部已经得出了正确的算法和策略,但因为输出篇幅的限制,导致答案被截断,结果被苹果的评估脚本直接判了零分。
也就是说,这不是逻辑的极限,这是Token的极限。
槽点二:“考卷”本身就有问题
这是对苹果研究严谨性的最后一击。反驳论文指出,不仅仅是评估方法有问题,苹果用来测试的“考卷”本身,都存在设计缺陷。
论文作者发现,在苹果使用的基准测试中,一些“过河问题”的题目,根据其给出的限制条件,在数学上是 根本无解的 。
一个无解的题,AI当然给不出“正确答案”。
但最离谱的是,苹果的评估系统,依然对模型在这些无解题上的输出进行了评分,并以此作为模型“失败”的证据。
槽点三:换个“考法”,AI原地复活
他们做了一个简单的实验:他们不再要求模型一步一步地写出汉诺塔的完整解法,而是让模型直接输出一个能解决这个问题的“程序代码”(比如一个Lua函数)。
结果如何?
模型在之前被判定为“彻底失败”的、更复杂的任务上,轻松给出了正确的程序。
这个反转极具说服力。它证明了AI不是不懂解题的逻辑,它只是无法遵循那种“默写全文”式的、极其冗长又低效的输出要求。
AI 的脑子里已经有了算法,但你非要它把每一步计算都口述出来。
此外,还有其他研究者在推特(X)指出了第四个槽点:缺乏人类基准的“单方面宣布”
即,苹果在整个实验中,从未将模型的表现与人类在相同任务下的表现进行对比。
别说AI了,就是一个正常人,在没有任何纸笔辅助的情况下,去心算一个需要几百步规划的逻辑谜题,大脑一样会“宕机”。
没有这个最基本的参照系,怎么能断言AI的“性能衰减”是一种根本性的“思考缺陷”,而不是所有智能体(包括人类)面对超限复杂任务时的正常表现呢?
本文来自微信公众号“大数据文摘”,36氪经授权发布。















