

文|光锥智能,作者 | 琳华,编辑|王一粟
大模型又迎来新一波的迭代周期。
近日,从Open AI发布GPT-5,到国内的昆仑万维、商汤、百川智能、智谱等都陆续发布了自己的新模型。其中昆仑万维更是一口气开启了技术周,连续5天每天发布一个新模型,而8月13日发布的,正是其本周发布的第三款模型——多模态统一模型UniPic 2.0。
UniPic 2.0主打的是,在单一模型中深度融合图像理解、文本到图像生成、图像编辑三大核心能力,这正是今年多模态技术攻克的热门方向——理解、生成、编辑一体化。
目前多数AI生图,生成之后就很难修改,经常出现对二次指令理解不充分,让图片越改越离谱的情况。
然而我们在测试UniPic 2.0的修改图片能力时,却看到了惊喜。
最近流行的“基础款不要搭基础款,上身基础,下身不基础”的玩梗,我们让UniPic 2.0给下身换一个同色系但夸张的穿搭,它就把下身的裤子改成了一条红色蓬蓬裙。

此模型在7月30日已经开源,这次上线的2.0版本,延续了之前1.0版本的优势——“又快又好”。
图片几秒生成、一句话编辑,小身材高表现
当其他大模型需要花几十秒生成一张图片时,UniPic 2.0只用几秒就画了一张复杂的“玻璃猫”出来。
不同于市面上其他开源的统一架构多模态模型动辄百亿参数的大规格,UniPic 2.0的参数规格只有2B,这让它响应生成的速度比起其他模型快了一个数量级。

虽然尺寸小,但UniPic 2.0在图片生成、理解和编辑三个方面的表现力也依然在线,甚至在图片编辑部分的部分指标分数打败了多个规模在10B以上开源模型。
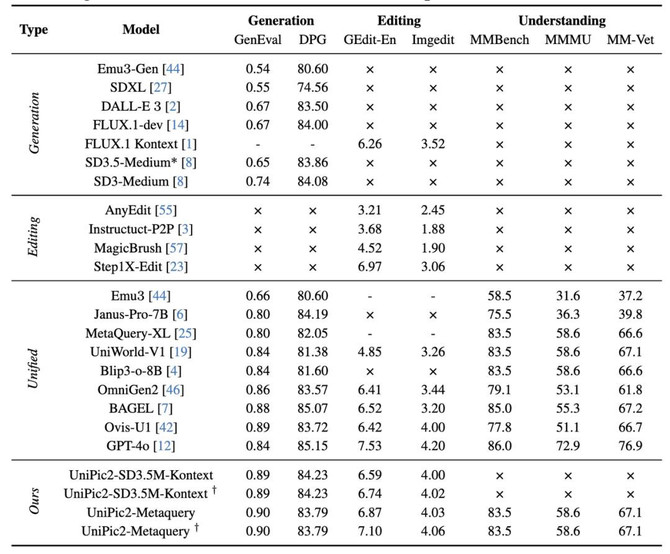
先从图片生成说起,在生成能力方面,UniPic 2.0的统一架构版本在GenEval(测试生成图像和文本匹配程度)取得0.90,超过了一众开源模型和闭源的GPT-4o(0.84)。可以看到,UniPic 2.0在小模型体量下依然能保持高性能的优势。
为了测试UniPic 2.0对于文本理解和生成匹配的情况,光锥智能让它和Bagel各自生成一张“梵高风格的树”,UniPic 2.0给出了一张完美切题的图片,而Bagel的图甚至还带着圣诞树的特征。

图片编辑则是UniPic 2.0表现最亮眼的部分,在GEdit-EN和Imgedit这两个关键的图像编辑任务指标上,UniPic2 - SD3.5M - Kontext 分别拿到6.59和4.00的成绩,UniPic2-Metaquery 系列模型的表现更好,最高拿到了7.10和4.06的分数,超越了OmiGen2、Bagel在内的多个开源模型,可以说直接追着闭源的GPT-4o而去。
在图像补全、擦除、主体一致性、风格转换上,光锥智能给出了多组提示词分别测评。
图片修改我们开头已经测试过,再给UniPic 2.0一张风景图,让它把相机视角向右旋转40度,给出的图片效果相当惊艳,甚至连阳光在墙上映出的影子都补全了。

日常比较实用的人物背景切换和图片消除,光锥智能也给UniPic 2.0安排上了。这比较考验大模型处理主体一致性的效果。
让UniPic 2.0给前OpenAI的前首席科学家ilya换个纯蓝色底的背景图,UniPic 2.0用5秒就把人物从色彩杂乱的背景中“抠”出来,换了个接近一寸照的纯蓝色背景。

再让大模型给纯色背景的人物P个沙滩海岸的背景图,UniPic 2.0把海岸的沙滩、大海和椰子树,都安排进了背景里。

嫌人物挡住拍摄的风景?我们给了UniPic 2.0一张被狗占据绝大部分的照片,让它消除掉狗的部分,UniPic 2.0生成出来的图片,基本做到了和原生背景一致。最上方的树林和右下角的深色部分,也都被保留在新生成的图片中。

风格转换方面,UniPic 2.0也能对各种风格信手拈来。我们先是让它生成了一张赛博朋克风格的图片,再让它做成吉卜力风,它也能把酷炫的机器人变成宫崎骏笔下的主角~

最重要的是,一个2B大小的模型,理论上已经可以在人们的手机和电脑上运行起来,这意味着一个可用、好用的高质量生成模型,距离真实落地已经越来越近。
轻量级的一体化模型架构,是怎样炼成的?
昆仑万维Skywork UniPic 2.0的核心优势,在于把模型同时将生成架构压缩在2B参数,在极少算力设备的情况下,也能负担起模型的运转。
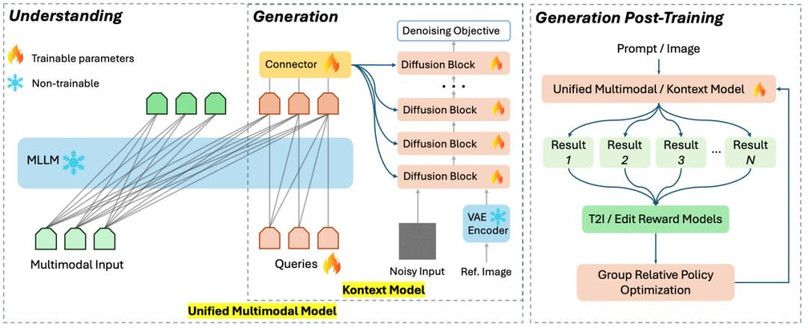
从模型架构上,昆仑万维选择了统一架构的方式,把图片编辑、生成和理解装在了一个模型中完成。
而长期以来,AI领域在处理多模态任务时,多采用的是“模块化”策略:图像理解、文本生成图像和图像编辑等任务,往往由独立的模型或模块分别完成,再串联起来。这样分割的架构导致各个模块之间缺乏协同。
“各自为政”的后果是,一个专注于图像生成的模型可能无法充分利用图像理解的信息来优化生成质量,而一个图像编辑模型也可能难以在编辑过程中兼顾文本指令的语义。这种“各自为政”的模式,最终导致各个参数的测试结果分数不高,难以形成强大的综合能力。
相比之下,UniPic2.0采用的统一架构,实现了图像理解、生成和编辑三大任务的深度融合。这种一体化的设计使得模型能够进行协同训练,形成更强大的多模态处理能力。
事实上,无论是坚持做原生多模态,还是做理解生成一体化,都是今年业内在探索多模态大模型的前沿方向:尽管在图像生成领域,许多公司出于商业化考虑仍坚持单一架构,但学界和坚持基础模型研究的厂商在近一年来都在积极探索理解统一生成和原生多模态方面的技术。
包括智源的OmniGen2、阶跃星辰发布的多模态推理模型Step-3,还是字节跳动Seed团队开源的BAGEL模型,都是通过原生多模态的框架或理解生成统一的机制,试图提升模型生成能力的效果。
此外,在兼顾多个模块性能优势的处理上,昆仑万维这次采用了一个创新的多任务强化学习模式——“渐进式双任务强化策略”。
针对传统多任务强化学习,常陷入优化一个任务会损害另一个任务的困境。对此,昆仑万维先针对编辑任务进行专项强化,再在已对齐一致性编辑的基础上,针对文生图任务的指令遵循进行专项强化。在这种模式下,能够确保文生图和图像编辑这两种不同任务的强化学习过程互不干扰,并且能够同时得到提升。
最终,和单一架构的模型相比,新的统一架构模型显著提升了整体性能和泛化能力,让生成质量与编辑精度同时提升。
UniPic 2.0模型的生成模块基于2B参数的SD3.5-Medium架构进行训练, 2B的参数规模使得UniPic 2.0模型非常“轻巧”,有望部署到各种硬件环境中,包括个人电脑、手机等端侧设备,从而降低模型应用的门槛。
UniPic的1.0版本就已经验证了这种可能性。昆仑万维表示,该模型可以在RTX 4090 消费级显卡上流畅运行。
轻量化的模型,意味着更快的推理速度和更低的计算资源消耗。不仅让用户可以享受到秒级响应的生成和编辑体验,还具备真正落地的成本和环境,成为一个真正能够“跑起来”的多模态生成模型。
追SOTA,也要追落地
在平衡AGI和务实落地上,昆仑万维一直是想得很清楚的一家公司。
追求SOTA带来的技术红利固然有限,但在模型竞争上,昆仑万维通过卷性价比和坚持开源两条策略,昆仑万维在国内巨头林立的环境下,开辟出了一个独有的舒适区:保持技术优势的同时,在落地上一骑绝尘。
是不是感觉很熟悉?前两天OpenAI发布的GPT-5也玩了一样的策略,拿便宜1/10的价格,剑指海外的顶流Anthropic。
要想做到这些,首先,技术得过硬。UniPic 2.0做到了,它用仅2B的参数规模,性能却反超了一批同样架构、参数却更庞大的模型。
这样做的好处是,2B参数的UniPic 2.0在推理时所需的计算资源大幅减少,让模型能够以秒级速度完成图像生成和编辑任务,对于用户来说,这个速度具有决定性的意义——很少有人愿意等AI跑个几十秒甚至是几分钟。
更小的参数,也意味着更低的训练和推理成本,既能让昆仑万维在追求SOTA的路上少烧点钱,也能让用户每次使用的成本更低。对于目前将重心放在应用出海的昆仑万维来说,UniPic 2.0无疑是一个更有性价比的选择。
同时,一个更早做出的决策——开源,也支撑昆仑万维在AI大模型训练中跑得更快。
DeepSeek掀起的开源风暴让人们看到开源对模型能力进化的重要性,而早在2022年底,昆仑万维就意识到了开源的重要性。从最早AI图像、音乐、文本和编程四大开源算法模型、百亿参数的大语言模型Skywork-13B系列到各类多模态大模型,可以说,昆仑万维在AI 2.0时代一直是坚定的开源选手。
开源,不仅能让更多好想法汇集反哺模型的训练,也能让昆仑万维通过模型吸引开发者和用户,建立品牌影响力。
从结果看,昆仑万维的这步棋走对了。
在国际知名开源社区HuggingFace的7月榜单中,和一众大厂、“五小虎”并列的中国公司中,就出现了昆仑万维的身影。在该榜单上,昆仑万维共有两个模型跻身海外模型引用的Top100,其中一个就是UniPic的1.0版本。
通过坚持开源和追逐SOTA并行,昆仑万维避免了与大厂在资源上的硬碰硬,而是通过技术创新和生态建设,找到了自己的生态位。
几年追逐AGI的赛跑下来,昆仑万维一直是那个嗅觉最敏锐的捕手。在大模型之战越来越卷的情况下,他们正在通过集中资源的方式,追求垂类的领先。
在模型领域上,昆仑万维做出了自己的取舍——比如,选择专注多模态领域深耕。
DeepSeek的出现,是昆仑万维改变的契机之一。在采访中,昆仑万维董事长兼总经理方汉提及,对于通用大模型,他们可能会选择外采。但一些专有大模型,则要自己训练。
这次,昆仑万维持续5天的技术周,就是围绕着多模态领域“秀肌肉”,展示他们持续深耕的成果。无论是能用在数字人上的音频驱动人像视频生成模型SkyReels-A3、还是当下大家更关注的具身智能大脑——世界模型Matrix-3D,都映射出这家公司的战略考量:聚焦前沿,也不忘落地。
在大模型密集发布的8月,昆仑万维成功找到了自己的位置。放在当下的中国AI生态圈里,能持续在牌桌上引人驻足的公司凤毛麟角,这是昆仑万维又一次靠策略胜利做到的以小博大。















