
最近看到很多找工作的伙伴在用AI写简历 injob Ai,突然期望能不能做一个AI来帮助用户自动写简历的东西。为此观察了大家使用Ai的习惯,逐步探索出一条适合的多Agent协同的写简历的方案逻辑,简单说下三者有什么不同。

想必很多人第一次用 AI 写简历,都是打开一个对话框,输入一句话:“帮我写份××岗位的简历 + 一对内容”
- 结果呢?模型生成一堆看起来“得漂亮”,但往往内容不够专业、不够稳定,内容能用又不能用的尴尬情况。
- 为什么昵?这是因为它还只是一个“更会说话的模型”,而不是一套有组织、有流程的简历生产体系。
为此我们做的尝试,是把写简历这件事,从“对话”提升到“工作化的流程上”。为此参考 Manus 的三元 Agent 架构(规划 → 执行 → 验证),我们设计了三元协同写简历模式(对话 → 计划 → 执行)。
它不只是会写,而是像一条专业的“简历流水线”,让结果更可控、更稳定、更贴合岗位。
纯模型对话和单Agent写简历有什么问题,三元结构的多Agent有什么优势?
阶段1:纯模型对话(Pure LLM Chat)
就像和一个充满智慧的人闲聊,但问题也最多:
- 稳定性差:一次说得准,下次就跑偏,上下文一长,约束就被遗忘。被打岔,可用性低
- 易幻觉:无中生有,自行大面积扩散,说的都对,但是可用又不可用。
- 结构不可控:自由发散,可能记忆混乱、要点缺失、不停的补充、上下内容不一致、已丢失。
- 对用户要求高:需要用户自己懂岗位、懂关键词、懂怎么喂提示词。
结果:适合给你提供灵感草稿,不适合直接做事情,思考依赖人。效果如图

阶段2:单Agent(Single Agent Pipeline)
有了流程意识,但还是“一人身兼数职”,agent匹配不堪:
有了改进:会按模板生成、会参考JD、会抽取关键词、能做有限校对。
局限性也很明显:
- 角色混淆:同一个Agent既采集需求又写作又校验,容易自我干扰、自相矛盾。
- 长上下文漂移:流程越长越容易忘前面定下的规则。
- 纠错成本高:一处错误常导致“整份重来”,上下文太多混乱,不可局部重试。
- 可观测性弱:哪一步出了问题不易定位,难以持续优化。
结果:能产出“像模板”的简历,但在复杂岗位/多段经历时,质量与稳定性仍不够。修改成本高
阶段3:三元协同多Agent(Dialogue → Plan → Execute )
分工明确,流水线产出、结构稳定:
- 对话Agent(收集需求):像产品经理,问清岗位、经历、成果、量化指标,补齐变量。
- 计划Agent(制定蓝图):像项目经理,拆解结构、选择模板、明确每段经历的“能力锚点”与关键词。
- 执行Agents(模块写作):像执行团队、开发测试。执行对应的内容,不用共享记忆,相互独立,互不干扰,可分别重试。
结果:稳定、可控、可追踪、分模块接受信息,避免自我干扰。操作简单,你只需提问题,即可执行任务。
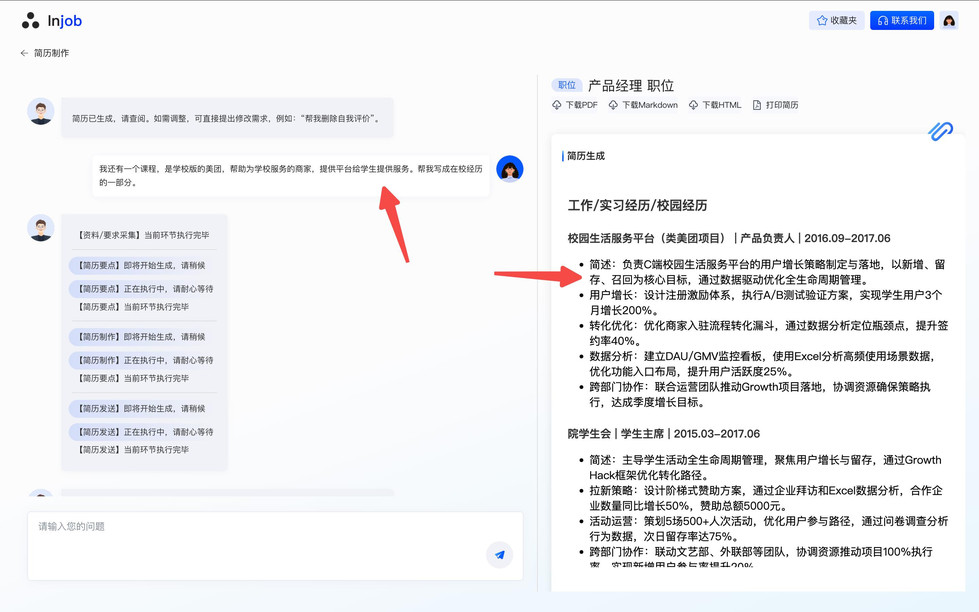
演化路径与能力对比如下
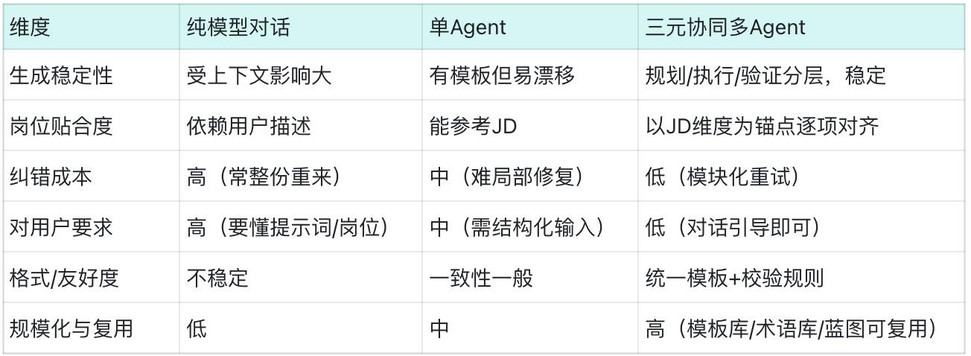
可以看到,越往后越稳定,对使用者的要求越低,效果越好。
injob AI:三元骨架:对话 → 计划 → 执行流程梳理
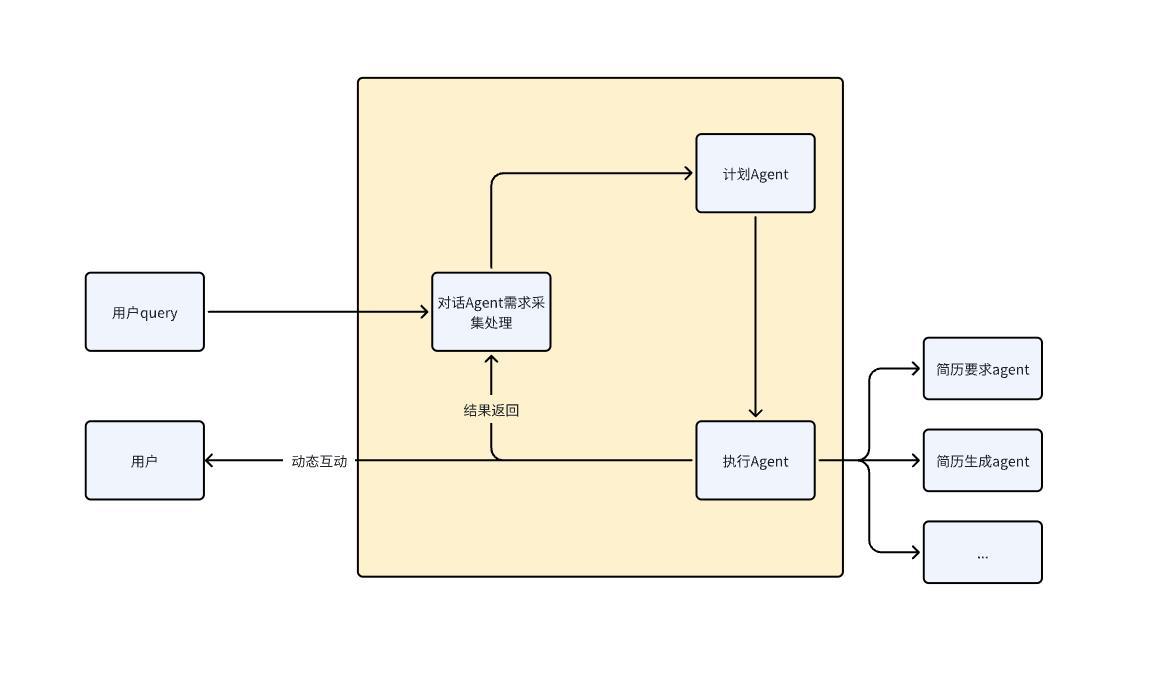
对话 Agent:把“经历”采成“变量”
像产品经理采需求,围绕 JD 维度提问,抽取并标准化:
- 岗位/行业/级别、必备能力关键词
- 关键经历(职责、动作、方法、结果、影响)
- 可量化指标(增⻓%、节省成本、效率倍数、覆盖人群)
计划 Agent:把“变量”排成“蓝图”:
像项目经理制定方案:
- 选择合适的简历结构与模板(应届/社招/技术/产品/运营等)
- 提取岗位关键词并分配到对应模块
- 生成主要简历
执行 Agents:把“蓝图”写成“成品”
- 多路并行:教育/经历/项目/技能/补充模块独立生成
- 抗干扰:各模块上下文隔离,不会互相“带跑偏”
效果
更稳定、也更“省心”,使用成本更低
- 分层解耦:对话只采集、计划只规划、执行只写作,职责清晰,减少“自我干扰”。
- 对使用者更友好:你只要说人话(目标与经历),其余交给系统问、系统定、系统写。
实际体验上的差异
- 纯对话:你得懂怎么跟模型说话,结果看缘分。
- 单Agent:像填表,但遇到复杂经历容易“失真”。
- 三元协同:像被专业顾问带着走——问到位、写到点、改到好。
本文由 @易俊源 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。















