
编辑:海狸 英智
【新智元导读】刷到1分钟AI短视频别只顾着点赞,背后的算力成本让人惊叹。MIT和英伟达等提出的径向注意力技术让长视频生成成本暴降4.4倍,速度飙升3.7倍,AI视频的未来已来!
刷到1分钟的AI生成短视频时,你可能想象不到背后的算力成本。
传统的视频扩散模型,处理视频时采用密集注意力机制。
这种方法虽然能保证画质,但计算量大得吓人,生成10秒视频就要烧掉数千元算力费用,随着视频长度增加,算力需求呈指数级飙升。
最近,MIT英伟达等研究人员发明的「径向注意力」技术,不仅让长视频生成速度提升3.7倍,还能把训练成本砍掉4.4倍。

论文链接:https://www.arxiv.org/abs/2506.19852
代码链接:
https://github.com/mit-han-lab/radial-attention/

径向注意力
在扩散模型的加持下,高质量视频生成逐渐从科幻变成现实。
但视频的时间维度给算力增加了不少负担,导致训练和推理长视频的成本飙升。
生成10秒视频就要烧掉数千元算力费用,价格之高令人望而却步。
对此,团队从热力学借了点灵感:「没有任何传播是无损的;信号、影响、注意力都会随着距离衰减。」
他们发现视频扩散模型里的注意力分数同样遵循这个规律——softmax后的权重随着token间的空间和时间距离递减。
这种「时空能量衰减」现象与自然界信号的物理衰减不谋而合。
这会不会就是视频生成降本增效的关键?
为进一步证实这种猜想,团队提出了「径向注意力」(Radial Attention):一种计算复杂度仅为O(nlog n)的稀疏注意力机制。
区别于之前SVG每次推理对空间/时间注意力进行动态选择,径向注意力用的是一种统一且高效的静态掩码。
这种掩码把空间和时间注意力合二为一,带来了更灵活、更快的长视频生成体验。
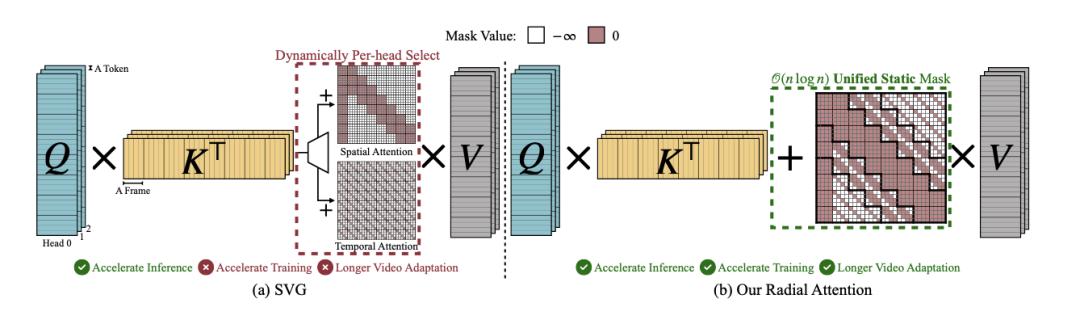
而且,这种简洁的静态注意力掩码让每个token只关注附近空间的邻居。随着时间距离的拉长,注意力窗口逐渐收缩。
相比传统的O (n²)密集注意力,径向注意力不仅大幅提升了计算效率,还比线性注意力拥有更强的表达能力。
在这项注意力机制创新的加持下,高质量视频生成变得更快、更长。
训练和推理的资源消耗极大地降低,为视频扩散模型打开了新的可能。
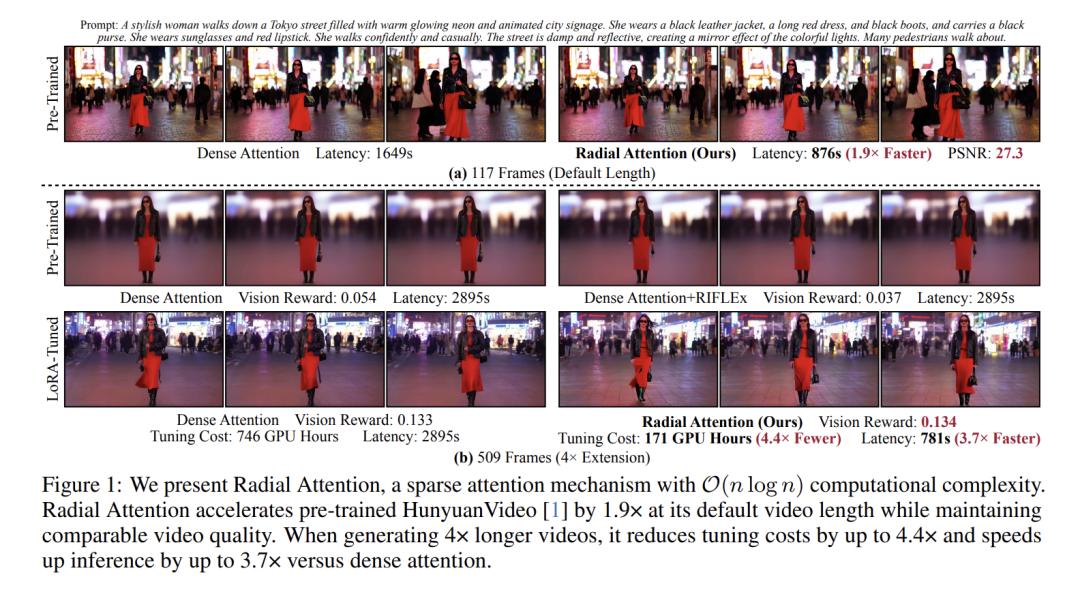
效果有多惊艳?实测数据来说话
研究团队在三个主流模型上做了测试:HunyuanVideo、Wan2.1-14B和Mochi 1,覆盖了不同参数规模的场景。
Mochi 1可以生成长达5秒、480p分辨率、162帧的视频;HunyuanVideo可以生成长达5秒、720p分辨率、125帧的视频;Wan2.1-14B可以生成长达5秒、720p分辨率、81帧的视频。


速度提升1.9倍到3.7倍
在默认视频长度下(如HunyuanVideo的117帧),径向注意力能把推理速度提升1.9倍左右。
当视频长度扩展到4倍时,速度提升更明显:从2895秒(近50分钟)降到781秒(约13分钟),足足快了3.7倍!
以前一小时才能生成的视频,现在喝杯咖啡的功夫就搞定了。
表1展示了在HunyuanVideo和Wan2.1-14B的默认生成长度下,径向注意力与三个强稀疏注意力基线的比较。
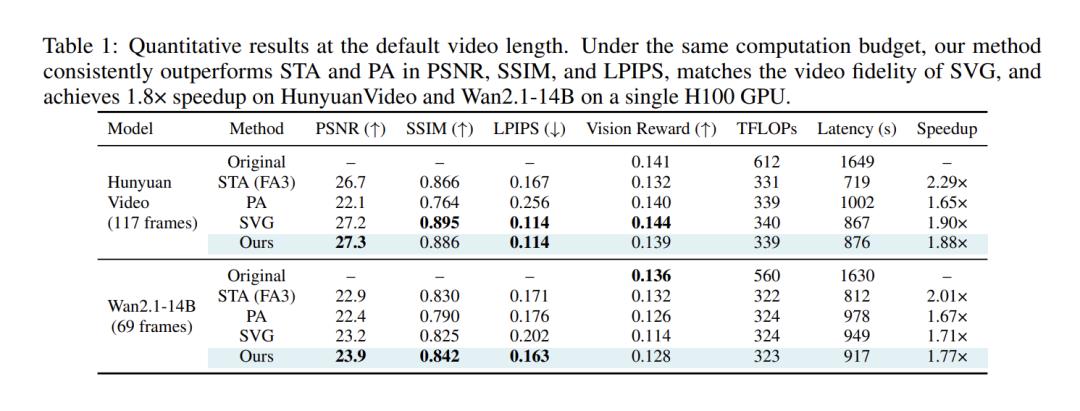
在相同的计算预算(以TFLOPs衡量)下,径向注意力保留了密集注意力的视频质量,同时在相似性指标(PSNR、SSIM、LPIPS)上始终优于STA和PA,并与SVG的质量相匹配。

在单个H100上,径向注意力为HunyuanVideo和Wan 2.1分别实现了1.9倍和1.8倍的端到端加速,与理论计算预算节省(1.8倍和1.7倍TFLOPs)相匹配。
尽管STA通过使用 FlashAttention-3(FA-3)产生了略高的加速,但视觉质量明显下降。
训练费用最多节省4.4倍
长视频生成最烧钱的其实是训练阶段。用径向注意力配合LoRA微调技术,训练成本直接大幅下降。
对于企业来说可是天大的好消息,以前做一个长视频项目可能要投入几十万,现在可能只需要几万块。
表2提供了2倍和4倍原始长度的视频生成结果。为了确保公平性,所有稀疏注意力基线使用相似的稀疏率。
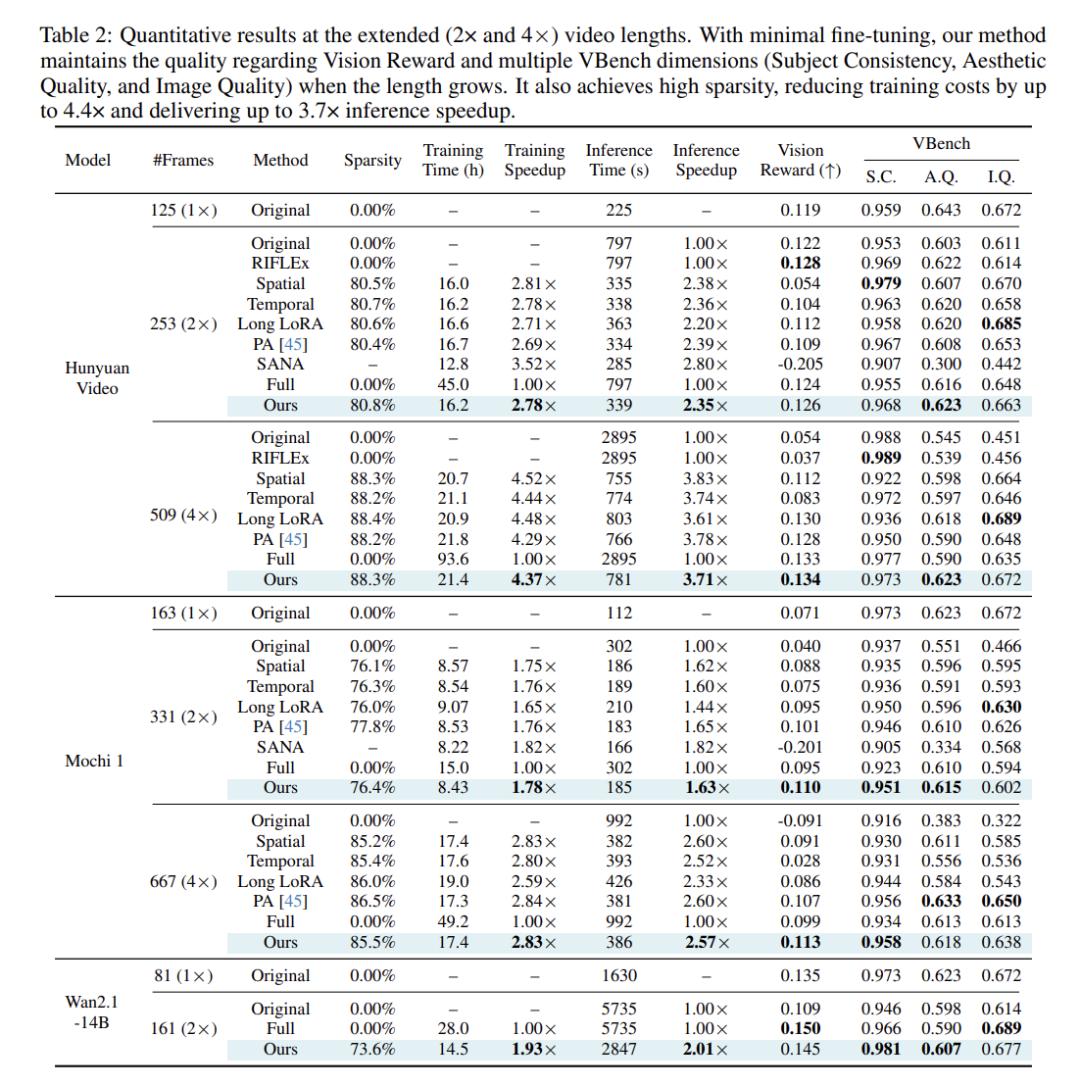
当生成长视频时,未经进一步调优的原始模型表现出显著的质量退化,尤其是在4倍视频长度扩展时。
虽然RIFLEx在2倍长度外推时提高了性能,但其质量在此之后恶化,表明扩展能力有限。
空间和时间稀疏注意力受到有限感受野的影响;另一方面,LongLoRA和PA虽然具有全局感受野,但未能捕捉时空相关性,导致质量下降。
有趣的是,PA在微调后视觉奖励有很大提高,表明其原始稀疏模式与预训练的注意力分布不一致。
微调允许模型适应施加的注意力稀疏性,改善对齐和质量。
SANA将softmax注意力替换为线性注意力,需要大规模重新训练,并且在基于微调的视频长度扩展下失败。
相比之下,径向注意力实现了与LoRA微调密集注意力模型相当的质量。甚至在默认视频长度下,比预训练模型略微提高了视觉奖励。

由于O(nlog n)复杂度,径向注意力比原始密集注意力提供了显著的推理和训练加速,如表2和图2所示。
生成4倍长的视频时,可以节省高达4.4倍的训练成本,并实现高达3.7倍的推理加速。
最关键的是,速度和成本降下来了,画质还没缩水。
在HunyuanVideo上,径向注意力的PSNR值达到27.3,和原始模型基本持平;视觉奖励分数0.134,甚至比密集注意力的0.133还高一点点。
不只是快:
径向注意力的「隐藏技能」
很多技术升级都需要重新训练模型,但径向注意力不需要。
它可以直接应用在预训练好的模型上,通过简单的 LoRA 微调就能实现加速。
径向注意力的一个关键优势是与预训练的特定任务LoRA(如艺术风格迁移)的无缝兼容性,这对创作者太友好了。
如图8所示,将扩展长度LoRA与现有风格LoRA结合使用,在实现长视频生成的同时保留了视觉质量。
研究团队还观察到,合并LoRA生成的内容风格与原始LoRA略有不同。
这种差异主要归因于用于训练扩展长度LoRA的相对较小的数据集,这可能引入轻微的风格偏差,与风格LoRA相互作用。
在更全面的数据集上训练长度扩展LoRA,预计将有助于缓解这个问题。
以前生成1分钟的AI视频是很多中小团队不敢想的,现在径向注意力让这事变得可行了。
以后,我们可能会看到更多AI生成的长视频内容,像短视频平台的剧情号。
参考资料:
https://www.arxiv.org/abs/2506.19852
https://github.com/mit-han-lab/radial-attention/

















Lyra77
AI视频生成太酷了,效率提升真的惊人!
Neo_X
感觉自己要变成一个只会点鼠标的家伙了
Neo_X
这效率,简直是让梦想成真!
Lyra77
未来世界,AI才是真正的艺术家!
PixelZen
人类的创造力正在被AI碾压,有点忧伤
Neo_X
别跟我提效率,这视觉效果太炸了!
Neo_X
AI,你这个小魔术师,真让人佩服
Neo_X
这波操作,我给跪了,这效率绝了!
VoidEcho
感觉自己要被AI取代了,有点害怕
VoidEcho
太牛逼了,效率就是真香!