OpenAI 新模型 GPT-4.1 可靠性遭质疑:独立测试显示其对齐性下降 195 0 IT之家 4 月 24 日消息,本月早些时候 OpenAI 推出了 GPT-4.1 人工智能模型,并声称该模型在遵循指令方面表现出色。然而,多项独立测试的结果却显示,与 OpenAI 以往发布的模型相比,GPT-4.1 的对齐性(即可靠性)似乎有所下降。据IT之家了解,通常情况下,OpenAI 在推出新模型时,会发布一份详细的技术报告,其中包含第一方和第三方的安全评估结果。但此次对于 GPT-4
微软365Copilot AI驱动企业搜索 推理代理 Copilot控制系统 微软365Copilot新增研究员和分析师机器人,助力企业智能化 195 0 近日,微软对其365Copilot 进行了更新,推出了一系列新功能,包括 AI 驱动的企业搜索、推理代理和一个新的代理商店。一些用户已经可以体验到这些新功能,而其他用户可能需要等待到5月份才能使用。其中,AI 驱动的企业搜索备受关注。微软表示,Copilot 搜索将搜索与人工智能的力量结合起来,提供更相关、更具上下文意识的搜索结果。微软设计和研究部门的副总裁 Jon Friedman 在视频中解释
DTVM 区块链虚拟机 JIT引擎 延迟JIT编译 全球首个集成大模型开发框架的区块链虚拟机正式开源 195 0 4 月 24 日,一款名为 DTVM(DeTerministic Virtual Machine)的区块链虚拟机宣布开源,在开发者社区引发热议。据其公开的技术论文显示,DTVM通过创新JIT引擎与全链路优化,IT引擎加速较传统解释执行实现约30倍的性能提升,刷新了目前行业最高水平,同时完全兼容以太坊生态,成为技术新标杆。区块链虚拟机是运行在区块链网络上的一个特殊计算环境,用于处理大量的计算和交易指
AI秘密曝光:Claude系统提示词泄露引发行业热议 195 0 近日,AI 领域再度掀起波澜,焦点集中在由 Anthropic 公司开发的强大语言模型 Claude 上。令人惊讶的是,一份长达25000个 Token 的提示词(System Prompt)意外泄露,内容详尽,超出行业的常规认知。这一事件迅速引发技术圈的热烈讨论,既揭示了顶尖 AI 系统的复杂性,也将透明度、安全性及知识产权等关键议题推向前台。系统提示词可以理解为大语言模型在与用户互动之前,开发
GeminiAPI Veo2 AI视频生成 文本到视频 Veo 2重磅登陆Gemini API:AI视频生成革命正式启航 195 0 近日,谷歌旗下人工智能团队宣布,其备受瞩目的视频生成模型Veo2正式通过Gemini API向开发者开放。这一消息迅速在科技圈掀起热潮,标志着AI视频生成技术迈入了全新的发展阶段。据悉,从即日起,凡是启用计费功能并达到Tier1及以上级别的开发者,均可通过API调用Veo2,体验其强大的文本到视频(Text-to-Video)和图像到视频(Image-to-Video)生成能力。这一举措不仅为开发
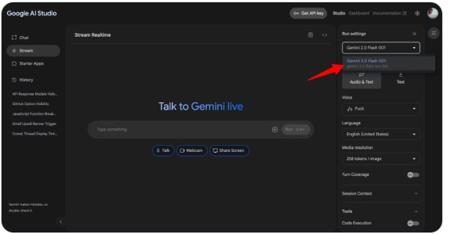
Gemini-2.0-flash-live-001 GoogleAIStudio 实时AI交互 多模态模型 谷歌AI Studio重磅更新:全新Gemini-2.0-flash-live-001正式上线 195 0 近日,谷歌人工智能开发平台Google AI Studio迎来了一次重大更新,全新的“Gemini-2.0-flash-live-001”模型正式亮相,并即刻取代了此前处于实验阶段的Gemini2.0Flash Experimental版本。这一消息迅速在全球开发者社区引发热议。据悉,这一新模型作为Gemini系列Live API的公开预览版本,已正式启用计费功能,标志着谷歌在实时AI交互技术上的
英伟达含量为零:华为密集模型盘古 Ultra 性能比肩 DeepSeek-R1,纯昇腾集群训练 195 0 密集模型的推理能力也能和 DeepSeek-R1 掰手腕了?华为利用纯昇腾集群训练出的盘古 Ultra,在数学竞赛、编程等推理任务当中,和 R1 打得有来有回。关键是模型参数量只有 135B,整个训练过程零英伟达含量,而且没有出现损失尖峰。通过改进的模型架构和系统优化策略,盘古 Ultra 拥有优异的性能表现和 52% 以上的算力利用率。并且有网友表示,训练过程中没有出现损失尖峰这一特征,似乎此
字节跳动 AILab Seed团队 推荐算法 大动作!字节AI Lab并入Seed,AI布局迎新变 195 0 据AI科技评论消息,近日字节AI Lab即将全部并入Seed团队,这一变动标志着字节内部AI研发架构迎来重大调整。据悉。字节AI Lab成立于 2016 年,曾是字节跳动AI研发的核心部门,由马维英负责,直接向张一鸣汇报。当时团队规模达 150 人,研究覆盖人工智能前沿技术,字节的推荐算法、短视频特效等都源于此,为抖音等产品的崛起立下汗马功劳,也助力字节在国内AI领域领先。但后来随着抖音、TikT
ChatGPT 原生图像生成功能已向免费用户推出 195 0 IT之家 3 月 31 日消息,ChatGPT 近期推出的 AI 图像生成功能引发了巨大反响,尤其是其“吉卜力风格”的图像生成,受到了众多网友的追捧。IT之家注意到,虽然官方还未宣布,但 OpenAI 已将 ChatGPT 这一原生 AI 图像生成功能向免费用户开放。OpenAI 此前于 3 月 26 日向全球所有 ChatGPT Plus、Pro 和 Team 用户推出了原生图像生成功能。然而
Aqara 智能语音伴侣 H1 发布:免唤醒词、可转动敲击操控、自带磁吸,289 元 195 0 IT之家 4 月 25 日消息,Aqara 绿米今日发布了一款智能语音伴侣 H1 新品,售价 299 元,领 10 元券后 289 元,现已在京东开售。新品可选黑白两色,支持自定义语音指令,可操控房间里的其他设备,采用蓝牙和 Thread 通信协议。该设备支持免唤醒词即拿即用,且使用后自动休眠,保护隐私。续航方面,Aqara 智能语音伴侣 H1 仅使用语音功能(未激活传感器模式),官方标称正常使
GPT4o GPT4o怎么用 GPT4o官网 GPT4o多少钱一个月 用户吐槽“ChatGPT太谄媚”,OpenAI 回滚“个性化”更新 195 0 站长之家(ChinaZ.com) 4月30日 消息:自上周以来,几乎所有用户都对 ChatGPT 的一种奇怪行为提出了抱怨。在这样的情况下,OpenAI 部署并撤回了对 ChatGPT 的一次更新。OpenAI 在最近发布的一篇博客文章中解释了这一切。ChatGPT 用户希望这个聊天机器人能更有人情味,并少一些刻板、少一点生硬。与 ChatGPT“公式化”的回复风格相比,不少用户们认为 Ant
腾讯混元大模型 AI大模型 国家智慧教育平台 人工智能应用 腾讯混元大模型应用实战课程正式上线国家智慧教育平台 195 0 近日,腾讯公司宣布其最新推出的 “腾讯混元大模型应用实战课程” 正式上线国家智慧教育平台。这一课程旨在为全国的高校师生提供全面的 AI 大模型技术知识和实用技能,帮助他们更高效地利用人工智能技术推动教育和科研的创新发展。3月28日,教育部在国家教育数字化战略行动2025年部署会上发布了国家智慧教育平台2.0智能版。这一新平台整合了众多教育资源,为教师和学生提供更加丰富和高效的学习体验。在这样的背景
OpenAI ioProducts 人工智能设备 语音人工智能助手 前苹果设计总监最新最开发项目或为一款无屏 AI 手机 195 0 据The Information报道,OpenAI 正在考虑收购一家公司,这家公司由前苹果设计总监 Jony Ive 和 OpenAI 首席执行官 Sam Altman 共同创立,名为 “io Products”。该公司专注于开发新型人工智能设备,包括一款可能没有屏幕的 “手机”,以及其他适用于家庭的智能产品。尽管项目接近的人士表示,这款产品并不完全是传统意义上的手机。Ive 与 Altman 的
Rapidus 2纳米半导体 AI组件 先进半导体 日本 Rapidus 开始试生产 AI 芯片 196 0 日本的国有企业 Rapidus Corp. 近日开始调整其芯片制造设备,预计将在本月底前启动先进半导体的试生产。这一步骤对于 Rapidus 而言至关重要,因为公司正努力进入人工智能(AI)组件市场。作为一家成立仅两年的初创企业,Rapidus 计划到2027年大规模生产采用2纳米工艺的半导体,届时其制造能力将与台湾的半导体制造巨头台积电相匹敌。图源备注:图片由AI生成,图片授权服务商Midjou
# AI工具 # AI项目和框架 NoteLLM – 小红书推出的笔记推荐多模态大模型框架 196 0 NoteLLM是什么NoteLLM 是小红书推出的针对笔记推荐的多模态大型语言模型框架。NoteLLM 基于生成笔记的压缩嵌入和自动生成标签类别,用大型语言模型(LLM)的强大语义理解能力,结合对比学习和指令微调技术,提升笔记推荐的准确性和相关性。NoteLLM-2 在NoteLLM基础上引入多模态输入,基于端到端微调策略,结合视觉编码器和 LLM,解决视觉信息被忽视的问题。NoteLLM-2
AI变天!HeyGen发布“有灵魂”的数字人Avatar IV 一张照片秒变“戏精”数字人,表情比真人还细腻 196 0 全球知名AI视频平台HeyGen正式发布Avatar IV数字人模型。基于创新的“扩散式音频驱动表情引擎”,用户仅需一张照片、一段30秒内的语音或文本脚本,即可生成高度逼真的数字人视频,表情、动作与语义情感深度同步,引发行业广泛关注。逼真演绎,源于先进技术内核Avatar IV仅需用户上传一张照片(支持侧脸及多角度图像)和30秒内的语音/脚本,即可生成动态数字人。新模型通过分析语音的节奏、语调及情